
1. نظرة عامة
في هذا الدرس التطبيقي، ستتعرّف على كيفية إعداد عمليات تنفيذ دفاتر الملاحظات وتشغيلها باستخدام Vertex AI Workbench.
ما ستتعلمه
ستتعرَّف على كيفية:
- استخدام المَعلمات في دفتر ملاحظات
- إعداد عمليات تنفيذ دفاتر الملاحظات وتشغيلها من واجهة مستخدم Vertex AI Workbench
تبلغ التكلفة الإجمالية لتشغيل هذا الدرس التطبيقي على Google Cloud حوالي 2 دولار أمريكي.
2. مقدّمة عن Vertex AI
يستخدم هذا المختبر أحدث منتج مستند إلى الذكاء الاصطناعي متاح على Google Cloud. تدمج Vertex AI عروض تعلُّم الآلة على Google Cloud في تجربة تطوير سلسة. في السابق، كان يمكن الوصول إلى النماذج المدرَّبة باستخدام AutoML والنماذج المخصَّصة من خلال خدمات منفصلة. يجمع العرض الجديد بين كليهما في واجهة برمجة تطبيقات واحدة، بالإضافة إلى منتجات جديدة أخرى. يمكنك أيضًا نقل المشاريع الحالية إلى Vertex AI. إذا كانت لديك أي ملاحظات، يُرجى الانتقال إلى صفحة الدعم.
تتضمّن Vertex AI العديد من المنتجات المختلفة لدعم مهام سير العمل الشاملة لتعلُّم الآلة. سيركّز هذا الدرس التطبيقي على Vertex AI Workbench.
تساعد أداة Vertex AI Workbench المستخدمين في إنشاء سير عمل متكامل مستند إلى دفاتر الملاحظات بسرعة من خلال الدمج العميق مع خدمات البيانات (مثل Dataproc وDataflow وBigQuery وDataplex) وVertex AI. تتيح هذه المنصة لعلماء البيانات الربط بخدمات بيانات Google Cloud Platform، وتحليل مجموعات البيانات، وتجربة تقنيات نمذجة مختلفة، وتفعيل النماذج المدرَّبة في بيئة الإنتاج، وإدارة عمليات تعلُّم الآلة من خلال دورة حياة النموذج.
3- نظرة عامة على حالة الاستخدام
في هذا الدرس التطبيقي، ستستخدم أسلوب التعلّم القائم على نقل المهام لتدريب نموذج لتصنيف الصور على مجموعة بيانات DeepWeeds من مجموعة بيانات TensorFlow. ستستخدم TensorFlow Hub لتجربة متّجهات الميزات المستخرَجة من بنى نماذج مختلفة، مثل ResNet50 وInception وMobileNet، وكلّها مدرَّبة مسبقًا على مجموعة بيانات ImageNet المعيارية. من خلال الاستفادة من أداة Notebook Executor عبر واجهة مستخدم Vertex AI Workbench، يمكنك تشغيل مهام على Vertex AI Training تستخدم هذه النماذج المدرَّبة مسبقًا وإعادة تدريب الطبقة الأخيرة للتعرّف على الفئات من مجموعة بيانات DeepWeeds.
4. إعداد البيئة
يجب أن يكون لديك مشروع على Google Cloud Platform مع تفعيل الفوترة لتتمكّن من تنفيذ هذا الدرس العملي. لإنشاء مشروع، اتّبِع التعليمات هنا.
الخطوة 1: تفعيل Compute Engine API
انتقِل إلى Compute Engine وانقر على تفعيل إذا لم يكن مفعّلاً بعد.
الخطوة 2: تفعيل واجهة برمجة التطبيقات Vertex AI API
انتقِل إلى قسم Vertex AI في Cloud Console وانقر على تفعيل واجهة Vertex AI API.

الخطوة 3: إنشاء مثيل Vertex AI Workbench
من قسم Vertex AI في Cloud Console، انقر على Workbench:

فعِّل واجهة برمجة التطبيقات Notebooks API إذا لم تكن مفعَّلة بعد.

بعد التفعيل، انقر على دفاتر الملاحظات المُدارة:

بعد ذلك، انقر على دفتر ملاحظات جديد.

أدخِل اسمًا لدفتر الملاحظات، ثم انقر على الإعدادات المتقدّمة.

ضمن "الإعدادات المتقدّمة"، فعِّل ميزة "إيقاف التشغيل عند عدم النشاط" واضبط عدد الدقائق على 60. هذا يعني أنّه سيتم إيقاف دفتر الملاحظات تلقائيًا عند عدم استخدامه حتى لا تتكبّد تكاليف غير ضرورية.

يمكنك ترك جميع الإعدادات المتقدّمة الأخرى كما هي.
بعد ذلك، انقر على إنشاء.
بعد إنشاء المثيل، انقر على فتح JupyterLab.

في المرة الأولى التي تستخدم فيها مثيلاً جديدًا، سيُطلب منك المصادقة.

تتضمّن Vertex AI Workbench طبقة توافق حسابية تتيح لك تشغيل النواة في TensorFlow وPySpark وR وما إلى ذلك، وكل ذلك من مثيل دفتر ملاحظات واحد. بعد المصادقة، ستتمكّن من اختيار نوع دفتر الملاحظات الذي تريد استخدامه من مشغّل التطبيقات.
بالنسبة إلى هذه الميزة الاختبارية، اختَر نواة TensorFlow 2.

5- كتابة رمز التدريب
تتألف مجموعة بيانات DeepWeeds من 17,509 صورة تعرض ثمانية أنواع مختلفة من الأعشاب الضارة الأصلية في أستراليا. في هذا القسم، ستكتب الرمز البرمجي لمعالجة مجموعة بيانات DeepWeeds مسبقًا وإنشاء نموذج لتصنيف الصور وتدريبه باستخدام متجهات الميزات التي تم تنزيلها من TensorFlow Hub.
عليك نسخ مقتطفات الرموز التالية إلى خلايا دفتر ملاحظاتك. تنفيذ الخلايا اختياري.
الخطوة 1: تنزيل مجموعة البيانات ومعالجتها مسبقًا
أولاً، ثبِّت الإصدار الليلي من "مجموعات بيانات TensorFlow" للتأكّد من الحصول على أحدث إصدار من مجموعة بيانات DeepWeeds.
!pip install tfds-nightly
بعد ذلك، استورِد المكتبات اللازمة:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
نزِّل البيانات من TensorFlow Datasets واستخرِج عدد الفئات وحجم مجموعة البيانات.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
حدِّد دالة معالجة مسبقة لتغيير مقياس بيانات الصورة بمقدار 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
لا تتضمّن مجموعة بيانات DeepWeeds تقسيمات للتدريب والتحقّق. ولا يتضمّن سوى مجموعة بيانات تدريبية. في الرمز البرمجي أدناه، ستستخدم% 80 من هذه البيانات للتدريب، و% 20 المتبقية للتحقّق من الصحة.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
الخطوة 2: إنشاء نموذج
بعد إنشاء مجموعتَي بيانات التدريب والتحقّق، تصبح جاهزًا لإنشاء النموذج. يوفر TensorFlow Hub متجهات الميزات، وهي نماذج مدرَّبة مسبقًا بدون طبقة التصنيف العليا. ستنشئ أداة استخراج ميزات من خلال تضمين النموذج المدرَّب مسبقًا في hub.KerasLayer، والذي يضمّ نموذج TensorFlow SavedModel كطبقة Keras. بعد ذلك، ستضيف طبقة تصنيف وتنشئ نموذجًا باستخدام Keras Sequential API.
أولاً، حدِّد المَعلمة feature_extractor_model، وهي اسم متجه الميزات في TensorFlow Hub الذي ستستخدمه كأساس لنموذجك.
feature_extractor_model = "inception_v3"
بعد ذلك، ستحوّل هذه الخلية إلى خلية مَعلمة، ما سيسمح لك بإدخال قيمة feature_extractor_model في وقت التشغيل.
أولاً، اختَر الخلية وانقر على "فاحص الخصائص" (Property inspector) في اللوحة اليمنى.

العلامات هي طريقة بسيطة لإضافة بيانات وصفية إلى دفتر ملاحظاتك. اكتب "المَعلمات" في مربّع "إضافة علامة" واضغط على Enter. في وقت لاحق عند إعداد التنفيذ، ستُدخل القيم المختلفة التي تريد اختبارها، وفي هذه الحالة نموذج TensorFlow Hub. يُرجى العِلم أنّه يجب كتابة الكلمة "parameters" (وليس أي كلمة أخرى) لأنّ هذه هي الطريقة التي يعرف بها منفّذ دفتر الملاحظات الخلايا التي يجب تحديد مَعلماتها.
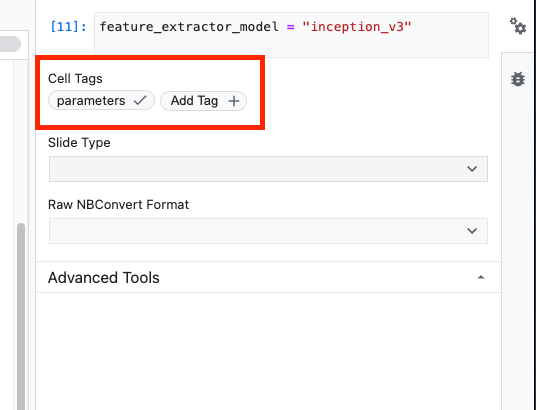
يمكنك إغلاق "عارض الخصائص" من خلال النقر على رمز الترس المزدوج مرة أخرى.
أنشئ خلية جديدة وحدِّد tf_hub_uri، حيث ستستخدم استيفاء السلسلة النصية لاستبدال اسم النموذج المُدرَّب مسبقًا الذي تريد استخدامه كنموذج أساسي لتنفيذ معيّن لدفتر الملاحظات. لقد ضبطت السمة feature_extractor_model تلقائيًا على "inception_v3"، ولكن القيم الصالحة الأخرى هي "resnet_v2_50" أو "mobilenet_v1_100_224". يمكنك استكشاف خيارات إضافية في فهرس TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
بعد ذلك، أنشئ أداة استخراج الميزات باستخدام hub.KerasLayer مع تمرير tf_hub_uri الذي حدّدته أعلاه. اضبط وسيطة trainable=False لتجميد المتغيرات كي لا يؤدي التدريب إلا إلى تعديل طبقة المصنّف الجديدة التي ستضيفها في الأعلى.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
لإكمال النموذج، عليك تضمين طبقة استخراج الميزات في نموذج tf.keras.Sequential وإضافة طبقة متصلة بالكامل للتصنيف. يجب أن يكون عدد الوحدات في عنوان التصنيف هذا مساويًا لعدد الفئات في مجموعة البيانات:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
أخيرًا، عليك تجميع النموذج وتطبيقه.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. تنفيذ دفتر الملاحظات
انقر على رمز المشغّل في أعلى دفتر الملاحظات.

الخطوة 1: ضبط مهمة التدريب
أدخِل اسمًا لعملية التنفيذ وقدِّم حزمة تخزين في مشروعك.

اضبط "نوع الجهاز" على 4 وحدات معالجة مركزية وذاكرة وصول عشوائي بسعة 15 غيغابايت.
وأضِف وحدة معالجة رسومات واحدة من NVIDIA.
اضبط البيئة على TensorFlow Enterprise 2.6 (وحدة معالجة الرسومات).
اختَر "تنفيذ لمرة واحدة".
الخطوة 2: ضبط المَعلمات
انقر على القائمة المنسدلة خيارات متقدّمة لضبط المَعلمة. في المربّع، اكتب feature_extractor_model=resnet_v2_50. سيؤدي ذلك إلى تجاهل inception_v3، وهي القيمة التلقائية التي ضبطتها لهذه المَعلمة في دفتر الملاحظات، واستخدام resnet_v2_50 بدلاً منها.

يمكنك ترك المربّع استخدام حساب الخدمة التلقائي محدّدًا.
بعد ذلك، انقر على إرسال.
الخطوة 3: فحص النتائج
في علامة التبويب "عمليات التنفيذ" في واجهة مستخدم Console، ستتمكّن من الاطّلاع على حالة تنفيذ دفتر الملاحظات.

إذا نقرت على اسم التنفيذ، سيتم نقلك إلى مهمة Vertex AI Training التي يتم فيها تشغيل دفتر الملاحظات.

عند اكتمال مهمتك، ستتمكّن من الاطّلاع على دفتر الملاحظات الناتج من خلال النقر على عرض النتيجة.

في دفتر الملاحظات الناتج، سترى أنّه تم استبدال قيمة feature_extractor_model بالقيمة التي مرّرتها في وقت التشغيل.

🎉 تهانينا! 🎉
تعرّفت على كيفية استخدام Vertex AI Workbench لإجراء ما يلي:
- استخدام المَعلمات في دفتر ملاحظات
- إعداد عمليات تنفيذ دفاتر الملاحظات وتشغيلها من واجهة مستخدم Vertex AI Workbench
لمزيد من المعلومات عن الأجزاء المختلفة من Vertex AI، اطّلِع على المستندات.
7. تنظيف
بشكلٍ تلقائي، يتم إيقاف دفاتر الملاحظات المُدارة تلقائيًا بعد مرور 180 دقيقة من عدم النشاط. إذا أردت إيقاف الجهاز الافتراضي يدويًا، انقر على الزر "إيقاف" في قسم Vertex AI Workbench في وحدة التحكّم. إذا أردت حذف دفتر الملاحظات بالكامل، انقر على زر "حذف".

لحذف حزمة التخزين، استخدِم قائمة التنقّل في Cloud Console، وانتقِل إلى "مساحة التخزين"، واختَر الحزمة، ثم انقر على "حذف":
