
1. 總覽
在本實驗室中,您將瞭解如何使用 Vertex AI Workbench 設定及啟動筆記本執行作業。
課程內容
內容如下:
- 在筆記本中使用參數
- 透過 Vertex AI Workbench 使用者介面設定及啟動筆記本執行作業
在 Google Cloud 上執行這個實驗室的總費用約為 $2 美元。
2. Vertex AI 簡介
本實驗室使用 Google Cloud 最新推出的 AI 產品服務。Vertex AI 整合了 Google Cloud 機器學習服務,提供流暢的開發體驗。以 AutoML 訓練的模型和自訂模型,先前需透過不同的服務存取。這項新服務將兩者併至單一 API,並加入其他新產品。您也可以將現有專案遷移至 Vertex AI。如有任何意見,請參閱支援頁面。
Vertex AI 包含許多不同的產品,可支援端對端機器學習工作流程。本實驗室將著重於 Vertex AI Workbench。
Vertex AI Workbench 與資料服務 (例如 Dataproc、Dataflow、BigQuery 和 Dataplex) 和 Vertex AI 深度整合,可協助使用者快速建構端對端筆記本工作流程。資料科學家可透過這個平台連線至 GCP 資料服務、分析資料集、實驗各種建模技術、將訓練好的模型部署至正式環境,以及在模型生命週期中管理 MLOps。
3. 用途總覽
在本實驗室中,您將使用遷移學習,在 TensorFlow Datasets 的 DeepWeeds 資料集上訓練圖像分類模型。您將使用 TensorFlow Hub,實驗從不同模型架構 (例如 ResNet50、Inception 和 MobileNet) 擷取的特徵向量,這些模型都已在 ImageNet 基準資料集上預先訓練。您將透過 Vertex AI Workbench 使用者介面,運用筆記本執行器在 Vertex AI 訓練 上啟動工作,這些工作會使用預先訓練的模型,並重新訓練最後一層,以辨識 DeepWeeds 資料集中的類別。
4. 設定環境
您必須擁有已啟用計費功能的 Google Cloud Platform 專案,才能執行這項程式碼研究室。如要建立專案,請按照這裡的說明操作。
步驟 1:啟用 Compute Engine API
前往「Compute Engine」,然後選取「啟用」 (如果尚未啟用)。
步驟 2:啟用 Vertex AI API
前往 Cloud 控制台的 Vertex AI 專區,然後點選「啟用 Vertex AI API」。

步驟 3:建立 Vertex AI Workbench 執行個體
在 Cloud 控制台的「Vertex AI」部分中,按一下「Workbench」:

如果尚未啟用 Notebooks API,請先啟用。

啟用後,按一下「MANAGED NOTEBOOKS」(代管型筆記本):

然後選取「新增記事本」。

為筆記本命名,然後按一下「進階設定」。

在「進階設定」下方啟用閒置關機功能,並將分鐘數設為 60。也就是說,筆記本會在閒置時自動關機,避免產生不必要的費用。

其他進階設定可以保留原樣。
接著點選「建立」。
建立執行個體後,請選取「Open JupyterLab」。

首次使用新執行個體時,系統會要求您驗證身分。

Vertex AI Workbench 具有運算相容性層,可讓您從單一筆記本執行個體啟動 TensorFlow、PySpark、R 等核心。完成驗證後,您就能從啟動器選取要使用的筆記本類型。
在本實驗室中,請選取 TensorFlow 2 核心。

5. 編寫訓練程式碼
DeepWeeds 資料集包含 17,509 張圖片,捕捉澳洲境內八種不同的原生雜草。在本節中,您將編寫程式碼來預先處理 DeepWeeds 資料集,並使用從 TensorFlow Hub 下載的特徵向量,建構及訓練圖片分類模型。
您需要將下列程式碼片段複製到筆記本的儲存格中。您可以選擇是否要執行儲存格。
步驟 1:下載及預先處理資料集
首先,請安裝 TensorFlow 資料集的 Nightly 版本,確保我們擷取的是最新版本的 DeepWeeds 資料集。
!pip install tfds-nightly
接著,匯入必要的程式庫:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
從 TensorFlow Datasets 下載資料,並擷取類別數量和資料集大小。
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
定義預先處理函式,將圖片資料縮放 255 倍。
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
DeepWeeds 資料集未提供訓練/驗證分割。僅隨附訓練資料集。在下列程式碼中,您會使用 80% 的資料進行訓練,其餘 20% 則用於驗證。
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
步驟 2:建立模型
建立訓練和驗證資料集後,就可以開始建構模型。TensorFlow Hub 提供特徵向量,也就是不含頂部分類層的預先訓練模型。您可以使用 hub.KerasLayer 包裝預先訓練模型,建立特徵擷取器,而 hub.KerasLayer 會將 TensorFlow SavedModel 包裝為 Keras 層。接著新增分類層,並使用 Keras Sequential API 建立模型。
首先,請定義參數 feature_extractor_model,這是您將做為模型基礎的 TensorFlow Hub 特徵向量名稱。
feature_extractor_model = "inception_v3"
接著,您要將這個儲存格設為參數儲存格,以便在執行階段傳遞 feature_extractor_model 的值。
首先,選取儲存格,然後按一下右側面板的屬性檢查器。

標記可輕鬆為筆記本新增中繼資料。在「新增代碼」方塊中輸入「parameters」,然後按下 Enter 鍵。稍後設定執行作業時,您會傳入不同的值 (在本例中為要測試的 TensorFlow Hub 模型)。請注意,您必須輸入「parameters」一詞 (而非任何其他字詞),筆記本執行器才能知道要將哪些儲存格參數化。
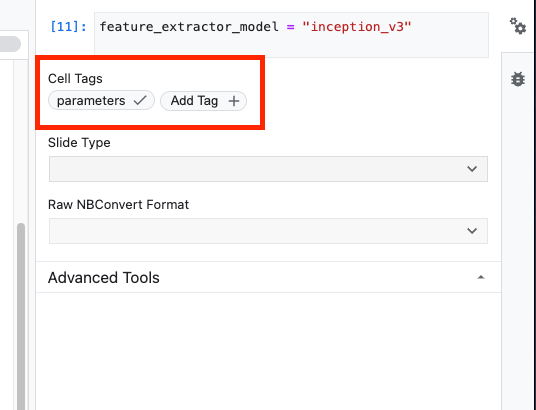
如要關閉屬性檢查器,請再次點選雙齒輪圖示。
建立新儲存格並定義 tf_hub_uri,您將使用字串插補,代入要當做筆記本特定執行作業基礎模型的預先訓練模型名稱。預設情況下,您已將 feature_extractor_model 設為 "inception_v3",但其他有效值為 "resnet_v2_50" 或 "mobilenet_v1_100_224"。您可以在 TensorFlow Hub 目錄中探索其他選項。
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
接著,使用 hub.KerasLayer 建立特徵擷取器,並傳入您在上方定義的 tf_hub_uri。將 trainable=False 引數設為凍結變數,這樣訓練只會修改您在頂端新增的分類器層。
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
如要完成模型,請將特徵擷取器層包裝在 tf.keras.Sequential 模型中,並新增用於分類的全連線層。這個分類標題中的單元數量應等於資料集中的類別數量:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
最後,編譯及調整模型。
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. 執行筆記本
按一下記事本頂端的「執行器」圖示。

步驟 1:設定訓練工作
為執行作業命名,並在專案中提供儲存空間 bucket。

將機型設為「4 個 CPU,15 GB RAM」。
並新增 1 個 NVIDIA GPU。
將環境設為 TensorFlow 企業版 2.6 (GPU)。
選擇「一次性執行」。
步驟 2:設定參數
按一下「進階選項」下拉式選單,設定參數。在方塊中輸入 feature_extractor_model=resnet_v2_50。這會將您在筆記本中為這個參數設定的預設值 inception_v3 覆寫為 resnet_v2_50。

您可以勾選「使用預設服務帳戶」方塊。
然後按一下「提交」。
步驟 3:查看結果
在控制台 UI 的「執行」分頁中,您可以查看筆記本的執行狀態。
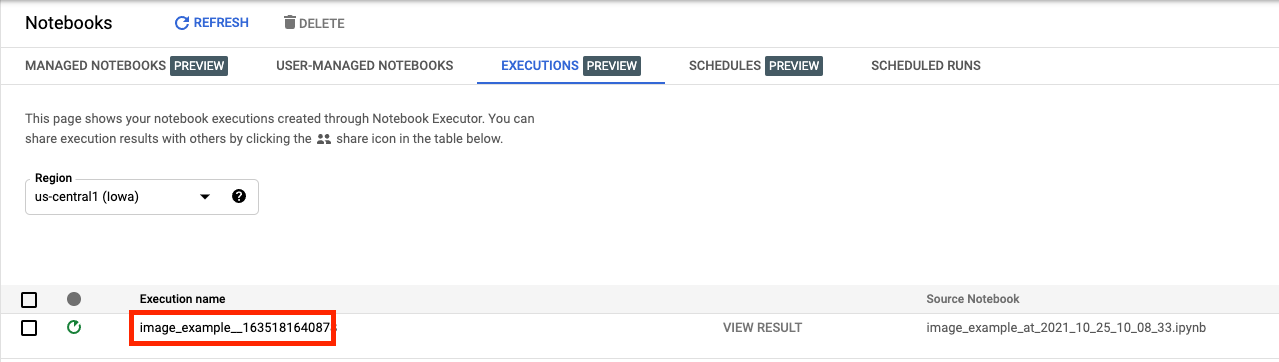
點選執行名稱後,系統會將您帶往筆記本執行的 Vertex AI 訓練工作。

工作完成後,按一下「查看結果」即可查看輸出筆記本。

在輸出筆記本中,您會看到 feature_extractor_model 的值已遭執行階段傳入的值覆寫。

🎉 恭喜!🎉
您已學會如何使用 Vertex AI Workbench 執行下列作業:
- 在筆記本中使用參數
- 透過 Vertex AI Workbench 使用者介面設定及啟動筆記本執行作業
如要進一步瞭解 Vertex AI 的其他部分,請參閱說明文件。
7. 清除
根據預設,代管型筆記本會在閒置 180 分鐘後自動關閉。如要手動關閉執行個體,請按一下控制台 Vertex AI Workbench 專區的「停止」按鈕。如要徹底刪除筆記本,請按一下「刪除」按鈕。

如要刪除 Storage Bucket,請使用 Cloud 控制台中的導覽選單瀏覽至 Storage,選取 bucket,然後按一下「Delete」:
