
1. खास जानकारी
इस लैब में, Vertex AI Workbench की मदद से नोटबुक एक्ज़ीक्यूशन को कॉन्फ़िगर और लॉन्च करने का तरीका बताया गया है.
आपको ये सब सीखने को मिलेगा
आपको, इनके बारे में जानकारी मिलेगी:
- नोटबुक में पैरामीटर इस्तेमाल करना
- Vertex AI Workbench के यूज़र इंटरफ़ेस (यूआई) से, नोटबुक को कॉन्फ़िगर और लॉन्च करना
Google Cloud पर इस लैब को चलाने की कुल लागत करीब 2 डॉलर है.
2. Vertex AI के बारे में जानकारी
इस लैब में, Google Cloud पर उपलब्ध एआई प्रॉडक्ट की नई सुविधा का इस्तेमाल किया जाता है. Vertex AI, Google Cloud के सभी एमएल प्रॉडक्ट को एक साथ इंटिग्रेट करता है, ताकि डेवलपर को बेहतर अनुभव मिल सके. पहले, AutoML और कस्टम मॉडल से ट्रेन किए गए मॉडल को अलग-अलग सेवाओं के ज़रिए ऐक्सेस किया जा सकता था. नए ऑफ़र में, इन दोनों को एक ही एपीआई में शामिल किया गया है. साथ ही, इसमें अन्य नए प्रॉडक्ट भी शामिल हैं. मौजूदा प्रोजेक्ट को भी Vertex AI पर माइग्रेट किया जा सकता है. अगर आपको कोई सुझाव देना है या शिकायत करनी है, तो कृपया सहायता पेज पर जाएं.
Vertex AI में कई अलग-अलग प्रॉडक्ट शामिल हैं, ताकि मशीन लर्निंग के वर्कफ़्लो को शुरू से लेकर आखिर तक सपोर्ट किया जा सके. इस लैब में, Vertex AI Workbench पर फ़ोकस किया जाएगा.
Vertex AI Workbench की मदद से, उपयोगकर्ता डेटा सेवाओं (जैसे, Dataproc, Dataflow, BigQuery, और Dataplex) और Vertex AI के साथ डीप इंटिग्रेशन करके, नोटबुक पर आधारित वर्कफ़्लो को तेज़ी से बना सकते हैं. इसकी मदद से डेटा साइंटिस्ट, GCP की डेटा सेवाओं से कनेक्ट हो सकते हैं. साथ ही, डेटासेट का विश्लेषण कर सकते हैं, मॉडलिंग की अलग-अलग तकनीकों के साथ एक्सपेरिमेंट कर सकते हैं, ट्रेन किए गए मॉडल को प्रोडक्शन में डिप्लॉय कर सकते हैं, और मॉडल के लाइफ़साइकल के दौरान MLOps को मैनेज कर सकते हैं.
3. इस्तेमाल के उदाहरण के बारे में खास जानकारी
इस लैब में, TensorFlow Datasets से DeepWeeds डेटासेट पर, इमेज क्लासिफ़िकेशन मॉडल को ट्रेन करने के लिए ट्रांसफ़र लर्निंग का इस्तेमाल किया जाएगा. TensorFlow Hub का इस्तेमाल करके, अलग-अलग मॉडल आर्किटेक्चर से निकाले गए फ़ीचर वेक्टर के साथ एक्सपेरिमेंट किया जाएगा. जैसे, ResNet50, Inception, और MobileNet. इन सभी को ImageNet बेंचमार्क डेटासेट पर पहले से ही ट्रेन किया गया है. Vertex AI Workbench के यूज़र इंटरफ़ेस (यूआई) के ज़रिए नोटबुक एक्ज़ीक्यूटर का इस्तेमाल करके, Vertex AI Training पर ऐसे जॉब लॉन्च किए जाएंगे जो पहले से ट्रेन किए गए इन मॉडल का इस्तेमाल करते हैं. साथ ही, DeepWeeds डेटासेट से क्लास पहचानने के लिए, आखिरी लेयर को फिर से ट्रेन किया जाएगा.
4. अपना एनवायरमेंट सेट अप करने का तरीका
इस कोडलैब को चलाने के लिए, आपके पास बिलिंग की सुविधा वाला Google Cloud Platform प्रोजेक्ट होना चाहिए. प्रोजेक्ट बनाने के लिए, यहां दिए गए निर्देशों का पालन करें.
पहला चरण: Compute Engine API चालू करना
Compute Engine पर जाएं. अगर यह पहले से चालू नहीं है, तो चालू करें को चुनें.
दूसरा चरण: Vertex AI API चालू करना
Cloud Console के Vertex AI सेक्शन पर जाएं और Vertex AI API चालू करें पर क्लिक करें.

तीसरा चरण: Vertex AI Workbench इंस्टेंस बनाना
Cloud Console के Vertex AI सेक्शन में जाकर, Workbench पर क्लिक करें:
अगर Notebooks API पहले से चालू नहीं है, तो इसे चालू करें.
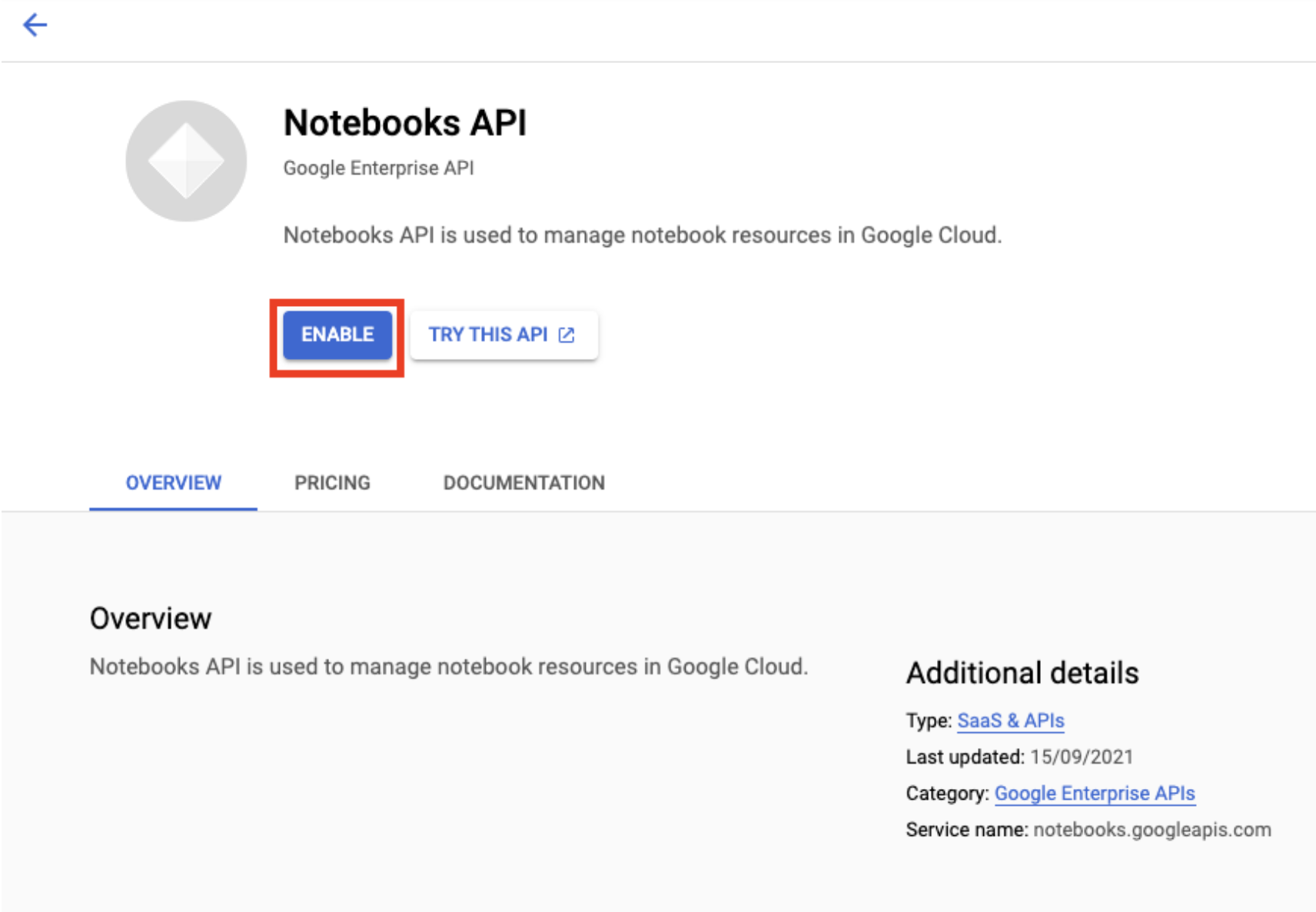
चालू होने के बाद, मैनेज की गई नोटबुक पर क्लिक करें:

इसके बाद, नई नोटबुक चुनें.
अपनी नोटबुक को कोई नाम दें. इसके बाद, बेहतर सेटिंग पर क्लिक करें.

ऐडवांस सेटिंग में जाकर, डिवाइस के बंद होने की सुविधा चालू करें. इसके बाद, डिवाइस के बंद होने का समय 60 मिनट पर सेट करें. इसका मतलब है कि इस्तेमाल न किए जाने पर, आपकी नोटबुक अपने-आप बंद हो जाएगी, ताकि आपको बिना वजह शुल्क न देना पड़े.

अन्य सभी ऐडवांस सेटिंग को डिफ़ॉल्ट रूप से सेट रहने दें.
इसके बाद, बनाएं पर क्लिक करें.
इंस्टेंस बन जाने के बाद, JupyterLab खोलें को चुनें.

पहली बार किसी नए इंस्टेंस का इस्तेमाल करते समय, आपसे पुष्टि करने के लिए कहा जाएगा.

Vertex AI Workbench में कंप्यूटिंग के साथ काम करने वाली एक लेयर होती है. इसकी मदद से, TensorFlow, PySpark, R वगैरह के लिए कर्नल लॉन्च किए जा सकते हैं. ये सभी कर्नल, एक ही नोटबुक इंस्टेंस से लॉन्च किए जा सकते हैं. पुष्टि करने के बाद, लॉन्चर से उस नोटबुक का टाइप चुना जा सकता है जिसका आपको इस्तेमाल करना है.
इस लैब के लिए, TensorFlow 2 कर्नल चुनें.

5. ट्रेनिंग कोड लिखना
DeepWeeds डेटासेट में 17,509 इमेज हैं. इनमें ऑस्ट्रेलिया में पाई जाने वाली आठ अलग-अलग तरह की खरपतवार की इमेज शामिल हैं. इस सेक्शन में, DeepWeeds डेटासेट को प्रीप्रोसेस करने के लिए कोड लिखा जाएगा. साथ ही, TensorFlow Hub से डाउनलोड किए गए फ़ीचर वेक्टर का इस्तेमाल करके, इमेज क्लासिफ़िकेशन मॉडल बनाया और उसे ट्रेन किया जाएगा.
आपको यहां दिए गए कोड स्निपेट को अपनी नोटबुक की सेल में कॉपी करना होगा. सेल को एक्ज़ीक्यूट करना ज़रूरी नहीं है.
पहला चरण: डेटासेट डाउनलोड करना और उसे प्रीप्रोसेस करना
सबसे पहले, TensorFlow datasets का नाइटली वर्शन इंस्टॉल करें. इससे यह पक्का किया जा सकेगा कि हम DeepWeeds डेटासेट का नया वर्शन इस्तेमाल कर रहे हैं.
!pip install tfds-nightly
इसके बाद, ज़रूरी लाइब्रेरी इंपोर्ट करें:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
TensorFlow Datasets से डेटा डाउनलोड करें. साथ ही, क्लास की संख्या और डेटासेट का साइज़ निकालें.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
इमेज डेटा को 255 से स्केल करने के लिए, प्रीप्रोसेसिंग फ़ंक्शन तय करें.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
DeepWeeds डेटासेट में, ट्रेनिंग/पुष्टि के लिए डेटा को अलग-अलग हिस्सों में नहीं बांटा गया है. यह सिर्फ़ ट्रेनिंग डेटासेट के साथ आता है. नीचे दिए गए कोड में, ट्रेनिंग के लिए 80% डेटा और पुष्टि करने के लिए बाकी 20% डेटा का इस्तेमाल किया जाएगा.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
दूसरा चरण: मॉडल बनाना
ट्रेनिंग और पुष्टि करने के लिए डेटासेट बनाने के बाद, अब मॉडल बनाया जा सकता है. TensorFlow Hub, फ़ीचर वेक्टर उपलब्ध कराता है. ये पहले से ट्रेन किए गए मॉडल होते हैं, जिनमें टॉप क्लासिफ़िकेशन लेयर नहीं होती. पहले से ट्रेन किए गए मॉडल को hub.KerasLayer से रैप करके, फ़ीचर एक्सट्रैक्टर बनाया जाएगा. यह TensorFlow SavedModel को Keras लेयर के तौर पर रैप करता है. इसके बाद, आपको क्लासिफ़िकेशन लेयर जोड़नी होगी. साथ ही, Keras Sequential API की मदद से मॉडल बनाना होगा.
सबसे पहले, पैरामीटर feature_extractor_model तय करें. यह TensorFlow Hub के उस फ़ीचर वेक्टर का नाम है जिसे आपको अपने मॉडल के आधार के तौर पर इस्तेमाल करना है.
feature_extractor_model = "inception_v3"
इसके बाद, इस सेल को पैरामीटर सेल बनाया जाएगा. इससे आपको रनटाइम के दौरान feature_extractor_model के लिए वैल्यू पास करने की अनुमति मिलेगी.
सबसे पहले, सेल चुनें और दाईं ओर मौजूद प्रॉपर्टी इंस्पेक्टर पर क्लिक करें.

टैग, नोटबुक में मेटाडेटा जोड़ने का एक आसान तरीका है. 'टैग जोड़ें' बॉक्स में "पैरामीटर" टाइप करें और Enter दबाएं. बाद में, एक्ज़ीक्यूशन को कॉन्फ़िगर करते समय, आपको अलग-अलग वैल्यू पास करनी होंगी. इस मामले में, आपको TensorFlow Hub मॉडल की जांच करनी है. ध्यान दें कि आपको "parameters" शब्द ही टाइप करना होगा, कोई और शब्द नहीं. ऐसा इसलिए, क्योंकि इससे ही नोटबुक एक्ज़ीक्यूटर को पता चलता है कि किन सेल को पैरामीटर के तौर पर इस्तेमाल करना है.

डबल गियर आइकॉन पर फिर से क्लिक करके, प्रॉपर्टी इंस्पेक्टर को बंद किया जा सकता है.
एक नई सेल बनाएं और tf_hub_uri को तय करें. यहां आपको स्ट्रिंग इंटरपोलेशन का इस्तेमाल करके, पहले से ट्रेन किए गए उस मॉडल का नाम डालना होगा जिसे आपको अपनी नोटबुक के किसी खास एक्ज़ीक्यूशन के लिए, बेस मॉडल के तौर पर इस्तेमाल करना है. डिफ़ॉल्ट रूप से, आपने feature_extractor_model को "inception_v3" पर सेट किया है. हालांकि, "resnet_v2_50" या "mobilenet_v1_100_224" भी मान्य वैल्यू हैं. TensorFlow Hub कैटलॉग में जाकर, अन्य विकल्प देखे जा सकते हैं.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
इसके बाद, hub.KerasLayer का इस्तेमाल करके फ़ीचर एक्सट्रैक्टर बनाएं और ऊपर तय किए गए tf_hub_uri को पास करें. वैरिएबल को फ़्रीज़ करने के लिए, trainable=False आर्ग्युमेंट सेट करें. इससे ट्रेनिंग के दौरान, सिर्फ़ नई क्लासिफ़ायर लेयर में बदलाव होगा. इस लेयर को सबसे ऊपर जोड़ा जाएगा.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
मॉडल को पूरा करने के लिए, फ़ीचर एक्सट्रैक्टर लेयर को tf.keras.Sequential मॉडल में रैप करें. साथ ही, क्लासिफ़िकेशन के लिए पूरी तरह से कनेक्टेड लेयर जोड़ें. इस क्लासिफ़िकेशन हेड में यूनिट की संख्या, डेटासेट में क्लास की संख्या के बराबर होनी चाहिए:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
आखिर में, मॉडल को कंपाइल और फ़िट करें.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. नोटबुक को एक्ज़ीक्यूट करना
नोटबुक में सबसे ऊपर मौजूद, एक्ज़ीक्यूटर आइकॉन पर क्लिक करें.

पहला चरण: ट्रेनिंग जॉब कॉन्फ़िगर करना
अपने एक्ज़ीक्यूशन को कोई नाम दें और अपने प्रोजेक्ट में स्टोरेज बकेट दें.

मशीन टाइप को 4 सीपीयू, 15 जीबी रैम पर सेट करें.
इसके बाद, 1 NVIDIA GPU जोड़ें.
एनवायरमेंट को TensorFlow Enterprise 2.6 (GPU) पर सेट करें.
'एक बार लागू होने वाला' विकल्प चुनें.
दूसरा चरण: पैरामीटर कॉन्फ़िगर करना
पैरामीटर सेट करने के लिए, ऐडवांस सेटिंग ड्रॉप-डाउन पर क्लिक करें. बॉक्स में, feature_extractor_model=resnet_v2_50 लिखें. इससे, नोटबुक में इस पैरामीटर के लिए सेट की गई डिफ़ॉल्ट वैल्यू inception_v3, resnet_v2_50 से बदल जाएगी.

डिफ़ॉल्ट सेवा खाते का इस्तेमाल करें बॉक्स को चुने हुए रहने दें.
इसके बाद, सबमिट करें पर क्लिक करें
तीसरा चरण: नतीजों की जांच करना
Console के यूज़र इंटरफ़ेस (यूआई) में मौजूद 'एक्ज़ीक्यूशन' टैब में, आपको अपनी नोटबुक के एक्ज़ीक्यूशन का स्टेटस दिखेगा.

एक्ज़ीक्यूशन के नाम पर क्लिक करने से, आपको Vertex AI Training जॉब पर ले जाया जाएगा. यहां आपकी नोटबुक चल रही है.
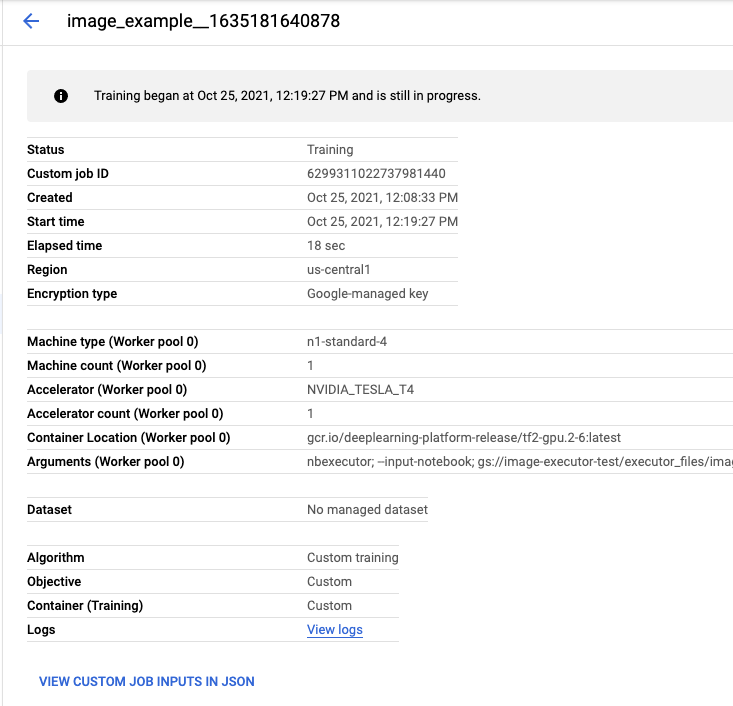
जॉब पूरा होने पर, नतीजे देखें पर क्लिक करके, आउटपुट नोटबुक देखी जा सकती है.

आउटपुट नोटबुक में, आपको दिखेगा कि feature_extractor_model की वैल्यू को रनटाइम में पास की गई वैल्यू से बदल दिया गया है.

🎉 बधाई हो! 🎉
आपने Vertex AI Workbench का इस्तेमाल करके ये काम करने का तरीका सीखा है:
- नोटबुक में पैरामीटर इस्तेमाल करना
- Vertex AI Workbench के यूज़र इंटरफ़ेस (यूआई) से, नोटबुक को कॉन्फ़िगर करना और उन्हें लॉन्च करना
Vertex AI के अलग-अलग हिस्सों के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
7. साफ़-सफ़ाई सेवा
डिफ़ॉल्ट रूप से, मैनेज की गई नोटबुक का इस्तेमाल न करने पर, वे 180 मिनट बाद अपने-आप बंद हो जाती हैं. अगर आपको इंस्टेंस को मैन्युअल तरीके से बंद करना है, तो कंसोल के Vertex AI Workbench सेक्शन में जाकर, Stop बटन पर क्लिक करें. अगर आपको नोटबुक पूरी तरह से मिटानी है, तो 'मिटाएं' बटन पर क्लिक करें.

स्टोरेज बकेट को मिटाने के लिए, Cloud Console में नेविगेशन मेन्यू का इस्तेमाल करके, स्टोरेज पर जाएं. इसके बाद, अपनी बकेट चुनें और मिटाएं पर क्लिक करें:
