
1. סקירה כללית
בשיעור ה-Lab הזה תלמדו איך להגדיר ולהפעיל הרצות של מחברות באמצעות Vertex AI Workbench.
מה לומדים
במאמר הזה נסביר איך:
- שימוש בפרמטרים במחברת
- הגדרה והפעלה של הרצות של מחברות מתוך ממשק המשתמש של Vertex AI Workbench
העלות הכוללת של הרצת ה-Lab הזה ב-Google Cloud היא בערך 2$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את מוצרי ה-ML ב-Google Cloud לחוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שאומנו באמצעות AutoML ולמודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את שניהם ב-API אחד, יחד עם מוצרים חדשים אחרים. אפשר גם להעביר פרויקטים קיימים אל Vertex AI. אם יש לך משוב, אפשר לעיין בדף התמיכה.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. בשיעור ה-Lab הזה נתמקד ב-Vertex AI Workbench.
Vertex AI Workbench עוזר למשתמשים ליצור במהירות תהליכי עבודה מבוססי מחברות מקצה לקצה באמצעות שילוב עמוק עם שירותי נתונים (כמו Dataproc, Dataflow, BigQuery ו-Dataplex) ועם Vertex AI. היא מאפשרת למדעני נתונים להתחבר לשירותי נתונים של GCP, לנתח מערכי נתונים, להתנסות בטכניקות שונות של מידול, לפרוס מודלים מאומנים בסביבת ייצור ולנהל MLOps לאורך מחזור החיים של המודל.
3. סקירה כללית של תרחישי שימוש
בשיעור ה-Lab הזה תשתמשו בלמידת העברה כדי לאמן מודל לסיווג תמונות במערך הנתונים DeepWeeds מתוך TensorFlow Datasets. תשתמשו ב-TensorFlow Hub כדי להתנסות בווקטורים של תכונות שחולצו מארכיטקטורות שונות של מודלים, כמו ResNet50, Inception ו-MobileNet, שכולם אומנו מראש על מערך הנתונים של מדד הביצועים ImageNet. באמצעות ממשק המשתמש של Vertex AI Workbench, תשתמשו ב-notebook executor כדי להפעיל משימות ב-Vertex AI Training שמשתמשות במודלים שאומנו מראש, ותאמנו מחדש את השכבה האחרונה כדי לזהות את המחלקות ממערך הנתונים DeepWeeds.
4. הגדרת הסביבה
כדי להפעיל את ה-codelab הזה, צריך פרויקט ב-Google Cloud Platform שמופעל בו חיוב. כדי ליצור פרויקט, פועלים לפי ההוראות האלה.
שלב 1: הפעלת Compute Engine API
עוברים אל Compute Engine ובוחרים באפשרות הפעלה אם הוא עדיין לא מופעל.
שלב 2: הפעלת Vertex AI API
עוברים אל הקטע Vertex AI במסוף Cloud ולוחצים על הפעלת Vertex AI API.

שלב 3: יצירת מכונה של Vertex AI Workbench
בקטע Vertex AI במסוף Cloud, לוחצים על Workbench:

מפעילים את Notebooks API אם הוא עדיין לא מופעל.

אחרי ההפעלה, לוחצים על מחברות מנוהלות:

לאחר מכן בוחרים באפשרות מחברת חדשה.

נותנים שם למחברת ולוחצים על הגדרות מתקדמות.

בקטע 'הגדרות מתקדמות', מפעילים את ההגדרה 'כיבוי במצב לא פעיל' ומגדירים את מספר הדקות ל-60. המשמעות היא שמחברת ה-notebook תיסגר אוטומטית כשלא משתמשים בה, כדי שלא תצטברו עלויות מיותרות.

אפשר להשאיר את כל ההגדרות המתקדמות האחרות כמו שהן.
אחרי כן, לוחצים על יצירה.
אחרי שהמופע נוצר, בוחרים באפשרות Open JupyterLab.

בפעם הראשונה שמשתמשים במופע חדש, תופיע בקשה לבצע אימות.

ל-Vertex AI Workbench יש שכבת תאימות לחישובים שמאפשרת להפעיל ליבות של TensorFlow, PySpark, R וכו', והכול מתוך מופע notebook יחיד. אחרי האימות, תוכלו לבחור את סוג ה-notebook שבו אתם רוצים להשתמש מתוך מרכז האפליקציות.
בשיעור ה-Lab הזה, בוחרים בגרעין TensorFlow 2.

5. כתיבת קוד לאימון
מערך הנתונים DeepWeeds כולל 17,509 תמונות של שמונה מינים שונים של עשבים שגדלים באוסטרליה. בקטע הזה תכתבו את הקוד לעיבוד מוקדם של מערך הנתונים DeepWeeds, ותבנו ותאמנו מודל לסיווג תמונות באמצעות וקטורים של תכונות שהורדו מ-TensorFlow Hub.
תצטרכו להעתיק את קטעי הקוד הבאים לתאים של המחברת. ההרצה של התאים היא אופציונלית.
שלב 1: הורדה ועיבוד מוקדם של מערך הנתונים
קודם כל, מתקינים את גרסת הלילה של מערכי נתונים של TensorFlow כדי לוודא שאנחנו מקבלים את הגרסה העדכנית ביותר של מערך הנתונים DeepWeeds.
!pip install tfds-nightly
אחר כך מייבאים את הספריות הנדרשות:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
מורידים את הנתונים מ-TensorFlow Datasets ומחלצים את מספר הכיתות ואת גודל מערך הנתונים.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
מגדירים פונקציית עיבוד מקדים כדי לשנות את קנה המידה של נתוני התמונה ב-255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
מערך הנתונים DeepWeeds לא כולל פיצולים של נתוני אימון ואימות. הוא מגיע רק עם מערך נתונים לאימון. בקוד שלמטה תשתמשו ב-80% מהנתונים האלה לאימון, וב-20% הנותרים לאימות.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
שלב 2: יצירת מודל
אחרי שיצרתם מערכי נתונים לאימון ולתיקוף, אתם יכולים להתחיל לבנות את המודל. TensorFlow Hub מספק וקטורים של תכונות, שהם מודלים שעברו אימון מראש בלי שכבת הסיווג העליונה. תצרו מחלץ תכונות על ידי שימוש ב-wrapper של המודל שעבר אימון מראש עם hub.KerasLayer, שהוא wrapper של TensorFlow SavedModel כשכבת Keras. לאחר מכן תוסיפו שכבת סיווג ותיצרו מודל באמצעות Keras Sequential API.
קודם מגדירים את הפרמטר feature_extractor_model, שהוא השם של וקטור התכונות ב-TensorFlow Hub שבו תשתמשו כבסיס למודל.
feature_extractor_model = "inception_v3"
בשלב הבא, הופכים את התא הזה לתא פרמטר, שיאפשר להעביר ערך ל-feature_extractor_model בזמן הריצה.
קודם בוחרים את התא ולוחצים על בודק המאפיינים בחלונית השמאלית.

תגים הם דרך פשוטה להוסיף מטא-נתונים למחברת. מקלידים 'parameters' בתיבה 'הוספת תג' ומקישים על Enter. בהמשך, כשמגדירים את ההפעלה, מעבירים את הערכים השונים שרוצים לבדוק, ובמקרה הזה את המודל של TensorFlow Hub. חשוב להקפיד להקליד את המילה parameters (ולא מילה אחרת), כי כך מנוע ההפעלה של המחברת יודע אילו תאים להגדיר כפרמטרים.

כדי לסגור את חלון הבדיקה של המאפיינים, לוחצים שוב על סמל גלגל השיניים הכפול.
יוצרים תא חדש ומגדירים את tf_hub_uri, שבו משתמשים באינטרפולציה של מחרוזות כדי להחליף את שם המודל שאומן מראש שרוצים להשתמש בו כמודל הבסיס להרצה ספציפית של המחברת. כברירת מחדל, הגדרתם את feature_extractor_model ל-"inception_v3", אבל ערכים תקפים אחרים הם "resnet_v2_50" או "mobilenet_v1_100_224". אפשר לעיין באפשרויות נוספות בקטלוג של TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
לאחר מכן, יוצרים את מחלץ התכונות באמצעות hub.KerasLayer ומעבירים את tf_hub_uri שהגדרתם למעלה. מגדירים את הארגומנט trainable=False כדי להקפיא את המשתנים, כך שהאימון ישנה רק את שכבת המסווג החדשה שתוסיפו מעל.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
כדי להשלים את המודל, עוטפים את שכבת המחלץ של התכונות בtf.keras.Sequential model ומוסיפים שכבה מקושרת מלאה לסיווג. מספר היחידות בראש הסיווג הזה צריך להיות שווה למספר המחלקות במערך הנתונים:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
לבסוף, מקמפלים את המודל ומתאימים אותו.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. הפעלת פנקס
לוחצים על סמל ההרצה בחלק העליון של המחברת.

שלב 1: הגדרת משימת אימון
נותנים שם להרצה ומציינים קטגוריית אחסון בפרויקט.

מגדירים את סוג המכונה ל-4 CPUs, 15 GB RAM.
מוסיפים יחידת GPU אחת של NVIDIA.
מגדירים את הסביבה ל-TensorFlow Enterprise 2.6 (GPU).
בוחרים באפשרות 'הפעלה חד-פעמית'.
שלב 2: הגדרת פרמטרים
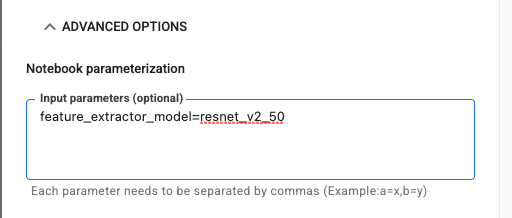
לוחצים על התפריט הנפתח אפשרויות מתקדמות כדי להגדיר את הפרמטר. בתיבה, מקלידים feature_extractor_model=resnet_v2_50. הערך הזה יחליף את inception_v3, שהוא ערך ברירת המחדל שהגדרתם לפרמטר הזה במחברת, בערך resnet_v2_50.
אפשר להשאיר את התיבה use default service account (שימוש בחשבון השירות שמוגדר כברירת מחדל) מסומנת.
ואז לוחצים על שליחה.
שלב 3: בדיקת התוצאות
בכרטיסייה 'הפעלות' בממשק המשתמש של Console, תוכלו לראות את הסטטוס של הפעלת המחברת.

אם לוחצים על שם ההרצה, מועברים אל משימת האימון של Vertex AI שבה פועל ה-notebook.
כשהמשימה תסתיים, תוכלו לראות את מחברת הפלט בלחיצה על הצגת התוצאה.

במחברת הפלט, אפשר לראות שהערך של feature_extractor_model הוחלף על ידי הערך שהועבר בזמן הריצה.

🎉 איזה כיף! 🎉
למדתם איך להשתמש ב-Vertex AI Workbench כדי:
- שימוש בפרמטרים במחברת
- הגדרה והפעלה של הרצות של מחברות מתוך ממשק המשתמש של Vertex AI Workbench
מידע נוסף על חלקים שונים ב-Vertex AI זמין בתיעוד.
7. הסרת המשאבים
כברירת מחדל, מחברות מנוהלות נסגרות אוטומטית אחרי 180 דקות של חוסר פעילות. כדי לכבות את המופע באופן ידני, לוחצים על הלחצן Stop (עצירה) בקטע Vertex AI Workbench במסוף. כדי למחוק את ה-Notebook לגמרי, לוחצים על לחצן המחיקה.

כדי למחוק את קטגוריית האחסון, בתפריט הניווט ב-Cloud Console, עוברים אל Storage, בוחרים את הקטגוריה ולוחצים על Delete:
