
1. Przegląd
W tym laboratorium dowiesz się, jak skonfigurować i uruchomić wykonania notatnika za pomocą Vertex AI Workbench.
Czego się dowiesz
Poznasz takie zagadnienia jak:
- Używanie parametrów w notatniku
- Konfigurowanie i uruchamianie wykonań notatnika w interfejsie Vertex AI Workbench
Całkowity koszt przeprowadzenia tego laboratorium w Google Cloud wynosi około 2 USD.
2. Wprowadzenie do Vertex AI
W tym module wykorzystujemy najnowszą ofertę produktów AI dostępną w Google Cloud. Vertex AI integruje oferty ML w Google Cloud, zapewniając płynne środowisko programistyczne. Wcześniej modele wytrenowane za pomocą AutoML i modele niestandardowe były dostępne w ramach osobnych usług. Nowa oferta łączy je w jeden interfejs API wraz z innymi nowymi usługami. Możesz też przeprowadzić migrację istniejących projektów do Vertex AI. Jeśli masz jakieś uwagi, odwiedź stronę pomocy.
Vertex AI obejmuje wiele różnych usług, które obsługują kompleksowe przepływy pracy związane z uczeniem maszynowym. Ten moduł będzie dotyczyć Vertex AI Workbench.
Vertex AI Workbench pomaga użytkownikom szybko tworzyć kompleksowe przepływy pracy oparte na notatnikach dzięki ścisłej integracji z usługami danych (takimi jak Dataproc, Dataflow, BigQuery i Dataplex) oraz Vertex AI. Umożliwia ona badaczom danych łączenie się z usługami danych GCP, analizowanie zbiorów danych, eksperymentowanie z różnymi technikami modelowania, wdrażanie wytrenowanych modeli w środowisku produkcyjnym i zarządzanie MLOps w całym cyklu życia modelu.
3. Omówienie przypadku użycia
W tym module użyjesz uczenia przez przenoszenie, aby wytrenować model klasyfikacji obrazów na podstawie zbioru danych DeepWeeds z TensorFlow Datasets. Aby eksperymentować z wektorami cech wyodrębnionymi z różnych architektur modeli, takich jak ResNet50, Inception i MobileNet, użyjesz TensorFlow Hub. Wszystkie te modele są wstępnie wytrenowane na zbiorze danych testowych ImageNet. Korzystając z wykonawcy notatnika w interfejsie Vertex AI Workbench, uruchomisz zadania w Vertex AI Training, które używają tych wstępnie wytrenowanych modeli, i ponownie wytrenujesz ostatnią warstwę, aby rozpoznawać klasy ze zbioru danych DeepWeeds.
4. Konfigurowanie środowiska
Aby wykonać to ćwiczenie, musisz mieć projekt w Google Cloud Platform z włączonymi płatnościami. Aby utworzyć projekt, postępuj zgodnie z instrukcjami.
Krok 1. Włącz interfejs Compute Engine API
Przejdź do Compute Engine i kliknij Włącz, jeśli nie jest jeszcze włączona.
Krok 2. Włącz interfejs Vertex AI API
Otwórz sekcję Vertex AI w konsoli Cloud i kliknij Włącz interfejs Vertex AI API.

Krok 3. Tworzenie instancji Vertex AI Workbench
W sekcji Vertex AI w konsoli Cloud kliknij Workbench:

Włącz interfejs Notebooks API, jeśli nie jest jeszcze włączony.

Po włączeniu kliknij ZARZĄDZANE NOTATNIKI:

Następnie wybierz NOWY NOTEBOOK.

Nadaj notatnikowi nazwę, a potem kliknij Ustawienia zaawansowane.

W sekcji Ustawienia zaawansowane włącz wyłączanie w przypadku bezczynności i ustaw liczbę minut na 60. Oznacza to, że Twój notebook będzie się automatycznie wyłączać, gdy nie jest używany, dzięki czemu nie poniesiesz niepotrzebnych kosztów.

Wszystkie pozostałe ustawienia zaawansowane możesz pozostawić bez zmian.
Następnie kliknij Utwórz.
Po utworzeniu instancji wybierz Otwórz JupyterLab.

Przy pierwszym użyciu nowej instancji pojawi się prośba o uwierzytelnienie.

Vertex AI Workbench ma warstwę zgodności obliczeniowej, która umożliwia uruchamianie jąder dla TensorFlow, PySpark, R itp. z jednej instancji notatnika. Po uwierzytelnieniu możesz wybrać typ notatnika, którego chcesz używać, w programie uruchamiającym.
W tym laboratorium wybierz jądro TensorFlow 2.

5. Pisanie kodu szkoleniowego
Zbiór danych DeepWeeds zawiera 17 509 obrazów przedstawiających 8 różnych gatunków chwastów występujących w Australii. W tej sekcji napiszesz kod do wstępnego przetwarzania zbioru danych DeepWeeds oraz utworzysz i wytrenujesz model klasyfikacji obrazów przy użyciu wektorów cech pobranych z TensorFlow Hub.
Musisz skopiować te fragmenty kodu do komórek notatnika. Wykonanie komórek jest opcjonalne.
Krok 1. Pobierz i wstępnie przetwórz zbiór danych
Najpierw zainstaluj nocną wersję zbiorów danych TensorFlow, aby mieć pewność, że pobierasz najnowszą wersję zbioru danych DeepWeeds.
!pip install tfds-nightly
Następnie zaimportuj niezbędne biblioteki:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Pobierz dane ze zbiorów danych TensorFlow i wyodrębnij liczbę klas oraz rozmiar zbioru danych.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Zdefiniuj funkcję wstępnego przetwarzania, aby przeskalować dane obrazu przez 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
Zbiór danych DeepWeeds nie zawiera podziału na zbiory do trenowania i walidacji. Zawiera tylko zbiór danych treningowych. W poniższym kodzie użyjesz 80% tych danych do trenowania, a pozostałych 20% – do walidacji.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Krok 2. Tworzenie modelu
Po utworzeniu zbiorów danych treningowych i do weryfikacji możesz już utworzyć model. TensorFlow Hub udostępnia wektory cech, czyli wstępnie wytrenowane modele bez górnej warstwy klasyfikacji. Ekstraktor cech utworzysz, owijając wstępnie wytrenowany model funkcją hub.KerasLayer, która owija TensorFlow SavedModel jako warstwę Keras. Następnie dodasz warstwę klasyfikacji i utworzysz model za pomocą interfejsu Keras Sequential API.
Najpierw zdefiniuj parametr feature_extractor_model, czyli nazwę wektora cech TensorFlow Hub, który będzie podstawą Twojego modelu.
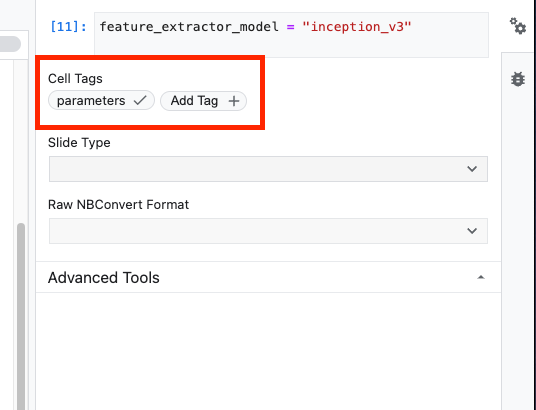
feature_extractor_model = "inception_v3"
Następnie przekształć tę komórkę w komórkę parametru, co umożliwi przekazywanie wartości parametru feature_extractor_model w czasie działania.
Najpierw wybierz komórkę i kliknij inspektora właściwości w panelu po prawej stronie.

Tagi to prosty sposób na dodawanie metadanych do notatnika. W polu Dodaj tag wpisz „parameters” i naciśnij Enter. Podczas konfigurowania wykonania przekażesz różne wartości, w tym przypadku model TensorFlow Hub, który chcesz przetestować. Pamiętaj, że musisz wpisać słowo „parameters” (a nie inne), ponieważ w ten sposób wykonawca notatnika wie, które komórki sparametryzować.
Aby zamknąć inspektora usługi, ponownie kliknij ikonę podwójnego koła zębatego.
Utwórz nową komórkę i zdefiniuj tf_hub_uri, w której użyjesz interpolacji ciągów znaków, aby zastąpić nazwę wstępnie wytrenowanego modelu, którego chcesz użyć jako modelu bazowego dla konkretnego wykonania notatnika. Domyślnie parametr feature_extractor_model ma wartość "inception_v3", ale inne prawidłowe wartości to "resnet_v2_50" lub "mobilenet_v1_100_224". Więcej opcji znajdziesz w katalogu TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
Następnie utwórz ekstraktor cech, używając funkcji hub.KerasLayer i przekazując zdefiniowany powyżej element tf_hub_uri. Ustaw argument trainable=False, aby zamrozić zmienne, tak aby trenowanie modyfikowało tylko nową warstwę klasyfikatora, którą dodasz na górze.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Aby ukończyć model, umieść warstwę wyodrębniania cech w tf.keras.Sequential modelu i dodaj w pełni połączoną warstwę do klasyfikacji. Liczba jednostek w tej głowicy klasyfikacji powinna być równa liczbie klas w zbiorze danych:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Na koniec skompiluj i dopasuj model.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Wykonywanie notatnika
U góry notatnika kliknij ikonę Wykonawca.

Krok 1. Skonfiguruj zadanie trenowania
Nadaj wykonaniu nazwę i podaj zasobnik pamięci w projekcie.

Ustaw typ maszyny na 4 procesory, 15 GB pamięci RAM.
Dodaj 1 GPU NVIDIA.
Ustaw środowisko na TensorFlow Enterprise 2.6 (GPU).
Wybierz Jednorazowe wykonanie.
Krok 2. Skonfiguruj parametry
Kliknij menu OPCJE ZAAWANSOWANE, aby ustawić parametr. W polu wpisz feature_extractor_model=resnet_v2_50. Spowoduje to zastąpienie wartością resnet_v2_50 wartości inception_v3, czyli wartością domyślną ustawioną dla tego parametru w notatniku.

Możesz pozostawić zaznaczone pole Użyj domyślnego konta usługi.
Następnie kliknij PRZEŚLIJ.
Krok 3. Sprawdź wyniki
Na karcie Wykonania w interfejsie konsoli możesz sprawdzić stan wykonania notatnika.

Jeśli klikniesz nazwę wykonania, przejdziesz do zadania Vertex AI Training, w którym działa Twój notatnik.

Po zakończeniu zadania możesz wyświetlić wyjściowy notatnik, klikając WYŚWIETL WYNIK.

W wyjściowym notatniku zobaczysz, że wartość feature_extractor_model została zastąpiona wartością przekazaną w czasie działania programu.

🎉 Gratulacje! 🎉
Wiesz już, jak używać Vertex AI Workbench do:
- Używanie parametrów w notatniku
- Konfigurowanie i uruchamianie wykonań notatnika w interfejsie Vertex AI Workbench
Więcej informacji o poszczególnych częściach Vertex AI znajdziesz w dokumentacji.
7. Czyszczenie
Domyślnie zarządzane notatniki wyłączają się automatycznie po 180 minutach bezczynności. Jeśli chcesz ręcznie wyłączyć instancję, kliknij przycisk Zatrzymaj w sekcji Vertex AI Workbench w konsoli. Jeśli chcesz całkowicie usunąć notatnik, kliknij przycisk Usuń.

Aby usunąć zasobnik Storage, w menu nawigacyjnym w konsoli Cloud otwórz Storage, wybierz zasobnik i kliknij Usuń:
