
1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ tìm hiểu cách định cấu hình và chạy các hoạt động thực thi sổ tay bằng Vertex AI Workbench.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Sử dụng các tham số trong sổ tay
- Định cấu hình và chạy các hoạt động thực thi sổ tay từ giao diện người dùng Vertex AI Workbench
Tổng chi phí để chạy bài tập này trên Google Cloud là khoảng 2 USD.
2. Giới thiệu về Vertex AI
Phòng thí nghiệm này sử dụng sản phẩm AI mới nhất hiện có trên Google Cloud. Vertex AI tích hợp các sản phẩm ML trên Google Cloud thành một trải nghiệm phát triển liền mạch. Trước đây, các mô hình được huấn luyện bằng AutoML và các mô hình tuỳ chỉnh có thể truy cập thông qua các dịch vụ riêng biệt. Sản phẩm mới này kết hợp cả hai thành một API duy nhất, cùng với các sản phẩm mới khác. Bạn cũng có thể di chuyển các dự án hiện có sang Vertex AI. Nếu bạn có ý kiến phản hồi, vui lòng truy cập trang hỗ trợ.
Vertex AI có nhiều sản phẩm để hỗ trợ quy trình làm việc ML toàn diện. Lớp học này sẽ tập trung vào Vertex AI Workbench.
Vertex AI Workbench giúp người dùng nhanh chóng xây dựng quy trình làm việc toàn diện dựa trên sổ tay thông qua việc tích hợp sâu với các dịch vụ dữ liệu (như Dataproc, Dataflow, BigQuery và Dataplex) và Vertex AI. Nhờ đó, các nhà khoa học dữ liệu có thể kết nối với các dịch vụ dữ liệu của GCP, phân tích tập dữ liệu, thử nghiệm các kỹ thuật mô hình hoá khác nhau, triển khai các mô hình đã huấn luyện vào quy trình sản xuất và quản lý MLOps trong suốt vòng đời của mô hình.
3. Tổng quan về trường hợp sử dụng
Trong phòng thí nghiệm này, bạn sẽ sử dụng phương pháp học chuyển giao để huấn luyện một mô hình phân loại hình ảnh trên tập dữ liệu DeepWeeds từ Tập dữ liệu TensorFlow. Bạn sẽ sử dụng TensorFlow Hub để thử nghiệm với các vectơ đặc trưng được trích xuất từ nhiều cấu trúc mô hình, chẳng hạn như ResNet50, Inception và MobileNet, tất cả đều được huấn luyện trước trên tập dữ liệu điểm chuẩn ImageNet. Bằng cách tận dụng trình thực thi sổ tay thông qua giao diện người dùng Vertex AI Workbench, bạn sẽ chạy các công việc trên Vertex AI Training bằng cách sử dụng các mô hình được huấn luyện trước này và huấn luyện lại lớp cuối cùng để nhận dạng các lớp từ tập dữ liệu DeepWeeds.
4. Thiết lập môi trường
Bạn cần có một dự án trên Google Cloud Platform đã bật tính năng thanh toán để chạy lớp học lập trình này. Để tạo một dự án, hãy làm theo hướng dẫn tại đây.
Bước 1: Bật Compute Engine API
Chuyển đến Compute Engine rồi chọn Bật nếu bạn chưa bật.
Bước 2: Bật Vertex AI API
Chuyển đến mục Vertex AI trong Bảng điều khiển Cloud rồi nhấp vào Bật Vertex AI API.

Bước 3: Tạo một phiên bản Vertex AI Workbench
Trong phần Vertex AI của Cloud Console, hãy nhấp vào Workbench:

Bật Notebooks API nếu bạn chưa bật.

Sau khi bật, hãy nhấp vào MANAGED NOTEBOOKS (SỔ TAY ĐƯỢC QUẢN LÝ):
Sau đó, chọn SỔ TAY MỚI.

Đặt tên cho sổ tay của bạn, sau đó nhấp vào Cài đặt nâng cao.

Trong phần Cài đặt nâng cao, hãy bật chế độ tắt khi không hoạt động và đặt số phút thành 60. Điều này có nghĩa là sổ tay của bạn sẽ tự động tắt khi không sử dụng để bạn không phải chịu các chi phí không cần thiết.

Bạn có thể giữ nguyên tất cả các chế độ cài đặt nâng cao khác.
Tiếp theo, hãy nhấp vào Tạo.
Sau khi tạo phiên bản, hãy chọn Mở JupyterLab.

Vào lần đầu tiên sử dụng một phiên bản mới, bạn sẽ được yêu cầu xác thực.

Vertex AI Workbench có một lớp tương thích về điện toán, cho phép bạn chạy các nhân cho TensorFlow, PySpark, R, v.v., tất cả đều từ một phiên bản sổ tay duy nhất. Sau khi xác thực, bạn có thể chọn loại sổ tay mà bạn muốn sử dụng trong trình chạy.
Đối với phòng thí nghiệm này, hãy chọn nhân TensorFlow 2.

5. Viết mã huấn luyện
Tập dữ liệu DeepWeeds bao gồm 17.509 hình ảnh ghi lại 8 loài cỏ dại khác nhau có nguồn gốc từ Úc. Trong phần này, bạn sẽ viết mã để tiền xử lý tập dữ liệu DeepWeeds, đồng thời xây dựng và huấn luyện một mô hình phân loại hình ảnh bằng cách sử dụng các vectơ đặc trưng được tải xuống từ TensorFlow Hub.
Bạn cần sao chép các đoạn mã sau vào các ô của sổ tay. Bạn không bắt buộc phải thực thi các ô.
Bước 1: Tải xuống và tiền xử lý tập dữ liệu
Trước tiên, hãy cài đặt phiên bản hằng ngày của tập dữ liệu TensorFlow để đảm bảo chúng ta đang lấy phiên bản mới nhất của tập dữ liệu DeepWeeds.
!pip install tfds-nightly
Sau đó, hãy nhập các thư viện cần thiết:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
Tải dữ liệu xuống từ TensorFlow Datasets và trích xuất số lượng lớp cũng như kích thước tập dữ liệu.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
Xác định một hàm tiền xử lý để chia tỷ lệ dữ liệu hình ảnh theo 255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
Tập dữ liệu DeepWeeds không đi kèm với các phần chia tách để huấn luyện/xác thực. Nó chỉ đi kèm với một tập dữ liệu huấn luyện. Trong đoạn mã bên dưới, bạn sẽ dùng 80% dữ liệu đó để huấn luyện và 20% còn lại để xác thực.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
Bước 2: Tạo mô hình
Giờ đây, khi đã tạo tập dữ liệu huấn luyện và xác thực, bạn có thể bắt đầu xây dựng mô hình. TensorFlow Hub cung cấp các vectơ đặc trưng, là những mô hình được huấn luyện trước mà không có lớp phân loại trên cùng. Bạn sẽ tạo một trình trích xuất đối tượng bằng cách bao bọc mô hình được huấn luyện tiền kỳ bằng hub.KerasLayer, thao tác này sẽ bao bọc một TensorFlow SavedModel dưới dạng một lớp Keras. Sau đó, bạn sẽ thêm một lớp phân loại và tạo mô hình bằng API Keras Sequential.
Trước tiên, hãy xác định tham số feature_extractor_model, đây là tên của vectơ đặc trưng TensorFlow Hub mà bạn sẽ dùng làm cơ sở cho mô hình.
feature_extractor_model = "inception_v3"
Tiếp theo, bạn sẽ biến ô này thành một ô tham số, cho phép bạn truyền giá trị cho feature_extractor_model trong thời gian chạy.
Trước tiên, hãy chọn ô rồi nhấp vào trình kiểm tra thuộc tính trên bảng điều khiển bên phải.

Thẻ là một cách đơn giản để thêm siêu dữ liệu vào sổ tay. Nhập "parameters" vào hộp Thêm thẻ rồi nhấn phím Enter. Sau đó, khi định cấu hình quá trình thực thi, bạn sẽ truyền các giá trị khác nhau, trong trường hợp này là mô hình TensorFlow Hub mà bạn muốn kiểm thử. Lưu ý rằng bạn phải nhập từ "parameters" (chứ không phải từ nào khác) vì đây là cách trình thực thi sổ tay biết những ô nào cần tham số hoá.

Bạn có thể đóng trình kiểm tra thuộc tính bằng cách nhấp lại vào biểu tượng bánh răng kép.
Tạo một ô mới và xác định tf_hub_uri, trong đó bạn sẽ sử dụng tính năng nội suy chuỗi để thay thế tên của mô hình được huấn luyện tiền kỳ mà bạn muốn dùng làm mô hình cơ sở cho một lần thực thi cụ thể của sổ tay. Theo mặc định, bạn đã đặt feature_extractor_model thành "inception_v3", nhưng các giá trị hợp lệ khác là "resnet_v2_50" hoặc "mobilenet_v1_100_224". Bạn có thể khám phá các lựa chọn khác trong danh mục TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
Tiếp theo, hãy tạo trình trích xuất đối tượng bằng cách sử dụng hub.KerasLayer và truyền tf_hub_uri mà bạn đã xác định ở trên. Đặt đối số trainable=False để cố định các biến sao cho quá trình huấn luyện chỉ sửa đổi lớp phân loại mới mà bạn sẽ thêm vào trên cùng.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
Để hoàn tất mô hình, hãy gói lớp trích xuất đối tượng trong một mô hình tf.keras.Sequential và thêm một lớp kết nối đầy đủ để phân loại. Số lượng đơn vị trong tiêu đề phân loại này phải bằng số lượng lớp trong tập dữ liệu:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
Cuối cùng, hãy biên dịch và điều chỉnh mô hình.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. Chạy sổ tay
Nhấp vào biểu tượng Trình thực thi ở đầu sổ tay.

Bước 1: Định cấu hình quy trình huấn luyện
Đặt tên cho quá trình thực thi và cung cấp một vùng lưu trữ trong dự án của bạn.

Đặt Loại máy thành 4 CPU, 15 GB RAM.
Thêm 1 GPU NVIDIA.
Thiết lập môi trường thành TensorFlow Enterprise 2.6 (GPU).
Chọn Thực thi một lần.
Bước 2: Định cấu hình các tham số
Nhấp vào trình đơn thả xuống TUỲ CHỌN NÂNG CAO để đặt tham số. Trong hộp này, hãy nhập feature_extractor_model=resnet_v2_50. Thao tác này sẽ ghi đè inception_v3 (giá trị mặc định mà bạn đặt cho tham số này trong sổ tay) bằng resnet_v2_50.
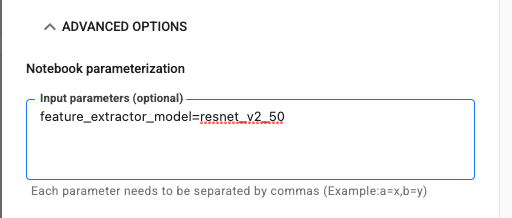
Bạn có thể giữ nguyên dấu đánh dấu trong hộp sử dụng tài khoản dịch vụ mặc định.
Sau đó, nhấp vào GỬI
Bước 3: Xem xét kết quả
Trong thẻ Thực thi trong giao diện người dùng Bảng điều khiển, bạn sẽ có thể xem trạng thái thực thi của sổ tay.

Nếu nhấp vào tên thực thi, bạn sẽ được chuyển đến công việc Huấn luyện Vertex AI nơi sổ tay của bạn đang chạy.
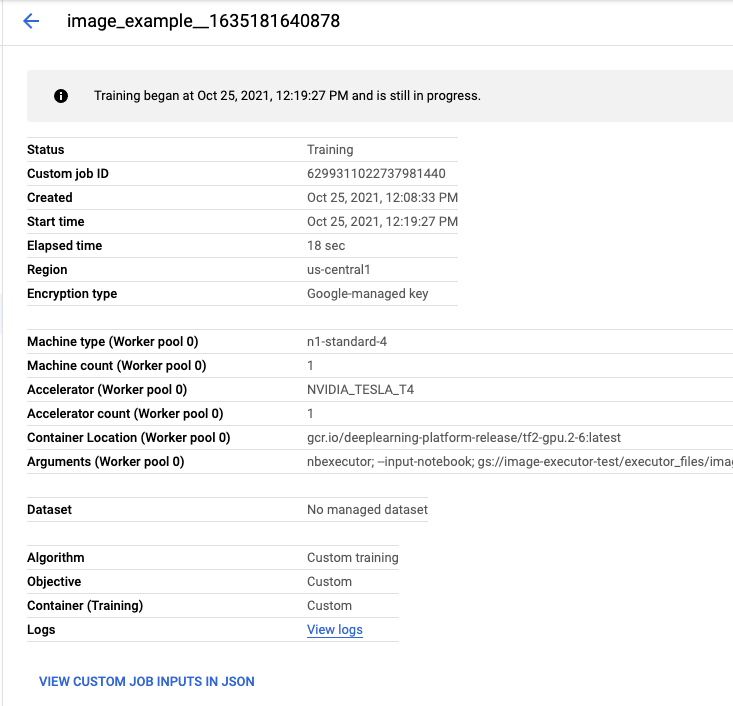
Khi công việc hoàn tất, bạn có thể xem sổ tay đầu ra bằng cách nhấp vào XEM KẾT QUẢ.

Trong sổ tay đầu ra, bạn sẽ thấy rằng giá trị của feature_extractor_model đã bị ghi đè bằng giá trị mà bạn đã truyền vào trong thời gian chạy.

🎉 Xin chúc mừng! 🎉
Bạn đã tìm hiểu cách sử dụng Vertex AI Workbench để:
- Sử dụng các tham số trong sổ tay
- Định cấu hình và chạy các hoạt động thực thi sổ tay từ giao diện người dùng Vertex AI Workbench
Để tìm hiểu thêm về các phần khác nhau của Vertex AI, hãy xem tài liệu.
7. Dọn dẹp
Theo mặc định, sổ tay được quản lý sẽ tự động tắt sau 180 phút không hoạt động. Nếu bạn muốn tắt thực thể theo cách thủ công, hãy nhấp vào nút Dừng trong phần Vertex AI Workbench của bảng điều khiển. Nếu bạn muốn xoá hoàn toàn sổ tay, hãy nhấp vào nút Xoá.

Để xoá Thùng lưu trữ, hãy sử dụng trình đơn Điều hướng trong Cloud Console, duyệt tìm Bộ nhớ, chọn thùng của bạn rồi nhấp vào Xoá:
