
1. 📖 مقدمة
هل شعرت يومًا بالإحباط والكسل الشديدين لدرجة أنّك لم تتمكّن من إدارة جميع نفقاتك الشخصية؟ وأنا أيضًا! لهذا السبب، سننشئ في هذا الدرس التطبيقي حول الترميز مساعدًا شخصيًا لإدارة النفقات يستند إلى Gemini 2.5 لإنجاز جميع المهام نيابةً عنّا. بدءًا من إدارة الإيصالات التي تم تحميلها إلى تحليل ما إذا كنت قد أنفقت الكثير لشراء قهوة!
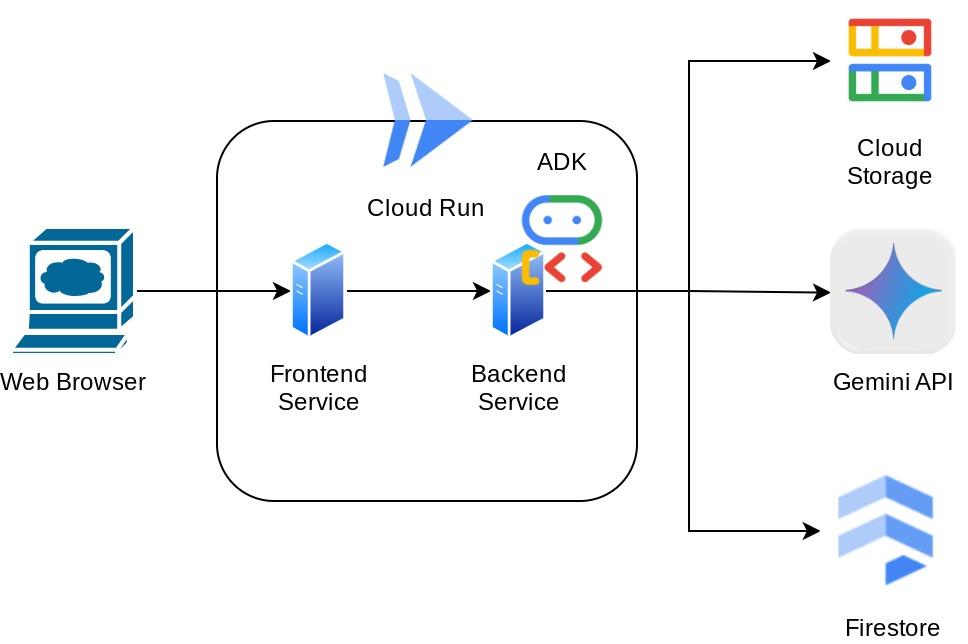
سيكون هذا المساعد متاحًا من خلال متصفّح الويب في شكل واجهة ويب للدردشة، حيث يمكنك التواصل معه أو تحميل بعض صور الإيصالات وطلب تخزينها، أو ربما البحث عن بعض الإيصالات للحصول على الملف وإجراء بعض تحليلات النفقات. ويستند كل ذلك إلى إطار عمل Google Agent Development Kit.
يتم تقسيم التطبيق نفسه إلى خدمتَين: الواجهة الأمامية والخلفية، ما يتيح لك إنشاء نموذج أولي سريع وتجربة شكله، بالإضافة إلى فهم شكل عقد واجهة برمجة التطبيقات لدمج كلتيهما.
خلال هذا الدرس العملي، ستتّبع نهجًا خطوة بخطوة على النحو التالي:
- إعداد مشروعك على Google Cloud وتفعيل جميع واجهات برمجة التطبيقات المطلوبة فيه
- إعداد حزمة على Google Cloud Storage وقاعدة بيانات على Firestore
- إنشاء فهرسة Firestore
- إعداد مساحة عمل لبيئة الترميز
- تنظيم الرمز المصدر للوكيل والأدوات والطلب وغير ذلك في حزمة ADK
- اختبار الوكيل باستخدام واجهة المستخدم المحلية لتطوير الويب في ADK
- إنشاء خدمة الواجهة الأمامية - واجهة المحادثة باستخدام مكتبة Gradio لإرسال بعض طلبات البحث وتحميل صور الإيصالات
- إنشاء خدمة الخلفية - خادم HTTP باستخدام FastAPI حيث يتضمّن رمز وكيل ADK وSessionService وArtifact Service
- إدارة متغيّرات البيئة وإعداد الملفات المطلوبة لتفعيل التطبيق على Cloud Run
- نشر التطبيق على Cloud Run
نظرة عامة على البنية
المتطلبات الأساسية
- القدرة على العمل باستخدام لغة Python
- فهم أساسي لبنية التطبيقات المتكاملة باستخدام خدمة HTTP
ما ستتعلمه
- إنشاء نماذج أولية لتطبيقات الويب باستخدام Gradio
- تطوير خدمات الخلفية باستخدام FastAPI وPydantic
- تصميم وكيل ADK مع الاستفادة من إمكاناته المتعدّدة
- استخدام الأداة
- إدارة الجلسات والعناصر
- استخدام وظيفة رد الاتصال لتعديل الإدخال قبل إرساله إلى Gemini
- استخدام BuiltInPlanner لتحسين تنفيذ المهام من خلال التخطيط
- تصحيح الأخطاء بسرعة من خلال واجهة الويب المحلية لحزمة تطوير التطبيقات (ADK)
- استراتيجية لتحسين التفاعل المتعدّد الوسائط من خلال تحليل المعلومات واسترجاعها عبر هندسة الطلبات وتعديل طلبات Gemini باستخدام عملية إعادة استدعاء ADK
- التوليد المعزّز بالاسترجاع المستند إلى الذكاء الاصطناعي الوكيل باستخدام Firestore كقاعدة بيانات متجهة
- إدارة متغيرات البيئة في ملف YAML باستخدام Pydantic-settings
- نشر التطبيق على Cloud Run باستخدام Dockerfile وتوفير متغيرات البيئة باستخدام ملف YAML
المتطلبات
- متصفّح الويب Chrome
- حساب Gmail
- مشروع على السحابة الإلكترونية تم تفعيل الفوترة فيه
يستخدم هذا الدرس التطبيقي حول الترميز، المصمّم للمطوّرين من جميع المستويات (بما في ذلك المبتدئين)، لغة Python في تطبيق المثال. ومع ذلك، لا يُشترط معرفة لغة Python لفهم المفاهيم المقدَّمة.
2. 🚀 قبل البدء
اختيار المشروع النشط في Cloud Console
يفترض هذا الدرس التطبيقي حول الترميز أنّ لديك مشروعًا على السحابة الإلكترونية على Google Cloud تم تفعيل الفوترة فيه. إذا لم تكن هذه الميزة متاحة لك بعد، يمكنك اتّباع التعليمات أدناه للبدء.
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع.
إعداد قاعدة بيانات Firestore
بعد ذلك، سنحتاج أيضًا إلى إنشاء قاعدة بيانات Firestore. Firestore في "الوضع الأصلي" هي قاعدة بيانات مستنِدة إلى تنسيق NoSQL ومصمَّمة للتوسّع التلقائي والأداء العالي وسهولة تطوير التطبيقات. يمكن أن تعمل أيضًا كقاعدة بيانات متجهة يمكنها دعم تقنية "الاسترجاع المعزّز بالإنشاء" في مختبرنا.
- ابحث عن firestore في شريط البحث، وانقر على منتج Firestore.
- بعد ذلك، انقر على الزر إنشاء قاعدة بيانات Firestore.
- استخدِم (تلقائي) كاسم لمعرّف قاعدة البيانات، واحرص على إبقاء الإصدار العادي محدّدًا. لأغراض العرض التوضيحي لهذا التمرين العملي، استخدِم Firestore Native مع قواعد الأمان المفتوحة.
- ستلاحظ أيضًا أنّ قاعدة البيانات هذه تتضمّن استخدامًا مجانيًا لطبقة الاستخدام YEAY! بعد ذلك، انقر على زر إنشاء قاعدة البيانات.
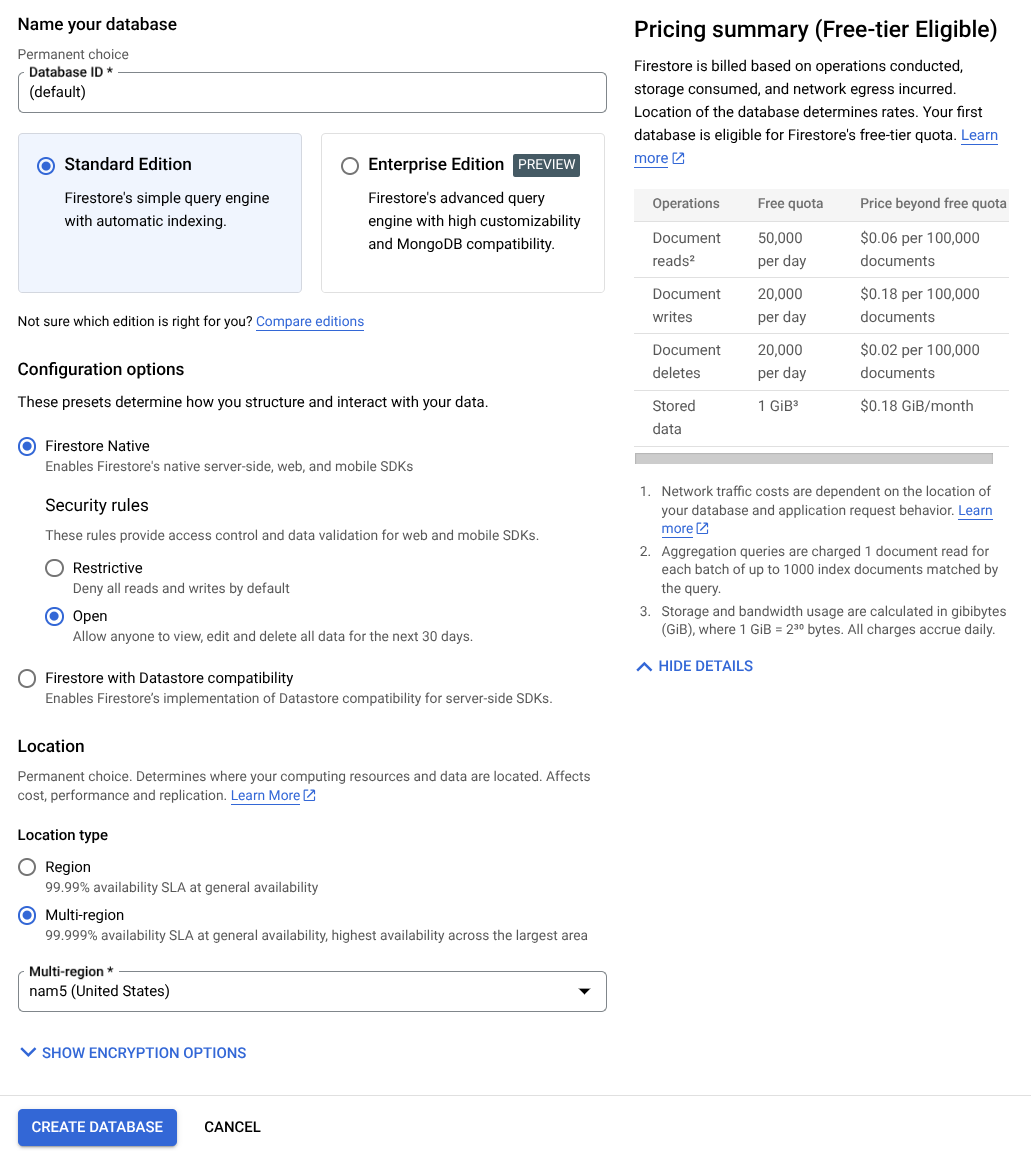
بعد تنفيذ هذه الخطوات، من المفترض أن تتم إعادة توجيهك إلى قاعدة بيانات Firestore التي أنشأتها للتو.
إعداد مشروع Cloud في نافذة Cloud Shell
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بأداة bq. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".
- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من إكمال عملية المصادقة وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
بدلاً من ذلك، يمكنك أيضًا الاطّلاع على معرّف PROJECT_ID في وحدة التحكّم.
انقر عليه وسيظهر لك كل مشروعك ورقم تعريف المشروع على الجانب الأيسر
- فعِّل واجهات برمجة التطبيقات المطلوبة من خلال الأمر الموضّح أدناه. قد تستغرق هذه العملية بضع دقائق، لذا يُرجى الانتظار.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
عند تنفيذ الأمر بنجاح، من المفترض أن تظهر لك رسالة مشابهة للرسالة الموضّحة أدناه:
Operation "operations/..." finished successfully.
يمكنك بدلاً من استخدام أمر gcloud، البحث عن كل منتج في وحدة التحكّم أو استخدام هذا الرابط.
في حال عدم توفّر أي واجهة برمجة تطبيقات، يمكنك تفعيلها في أي وقت أثناء عملية التنفيذ.
راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
إعداد حزمة Google Cloud Storage
بعد ذلك، من الوحدة الطرفية نفسها، علينا إعداد حزمة Cloud Storage لتخزين الملف الذي تم تحميله. نفِّذ الأمر التالي لإنشاء الحزمة. ستحتاج إلى اسم حزمة فريد وذو صلة بإيصالات مساعد النفقات الشخصية، لذا سنستخدم اسم الحزمة التالي مع رقم تعريف مشروعك
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
ستظهر النتيجة التالية
Creating gs://personal-expense-{your-project-id}
يمكنك التأكّد من ذلك من خلال الانتقال إلى "قائمة التنقّل" في أعلى يمين المتصفّح واختيار Cloud Storage -> Bucket.
إنشاء فهرس Firestore للبحث
Firestore هي قاعدة بيانات NoSQL بشكلٍ أصلي، ما يوفّر أداءً ومرونةً فائقَين في نموذج البيانات، ولكنّها تتضمّن قيودًا عندما يتعلّق الأمر بطلبات البحث المعقّدة. بما أنّنا نخطّط لاستخدام بعض طلبات البحث المركّبة المتعددة الحقول والبحث المتّجه، علينا إنشاء بعض الفهارس أولاً. يمكنك الاطّلاع على مزيد من التفاصيل في هذه المستندات.
- نفِّذ الأمر التالي لإنشاء فهرس يتيح طلبات البحث المركّبة.
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- وتنفيذ هذا الإجراء لدعم البحث المتّجه
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
يمكنك التحقّق من الفهرس الذي تم إنشاؤه من خلال الانتقال إلى Firestore في Cloud Console والنقر على مثيل قاعدة البيانات (تلقائي) واختيار الفهارس في شريط التنقّل.
الانتقال إلى Cloud Shell Editor وإعداد دليل عمل التطبيق
الآن، يمكننا إعداد أداة تعديل الرموز لتنفيذ بعض مهام الترميز. سنستخدم "محرّر Cloud Shell" لهذا الغرض.
- انقر على الزر "فتح المحرِّر"، وسيؤدي ذلك إلى فتح "محرِّر Cloud Shell"، ويمكننا كتابة الرمز هنا
- بعد ذلك، نحتاج أيضًا إلى التحقّق مما إذا كان قد تمّ ضبط الصدفة على معرّف المشروع الصحيح الذي لديك، وإذا رأيت قيمة داخل ( ) قبل رمز $ في الوحدة الطرفية ( في لقطة الشاشة أدناه، القيمة هي "adk-multimodal-tool")، فإنّ هذه القيمة تعرض المشروع الذي تمّ إعداده لجلسة الصدفة النشطة.

إذا كانت القيمة المعروضة صحيحة، يمكنك تخطّي الأمر التالي. ومع ذلك، إذا كان غير صحيح أو غير متوفّر، شغِّل الأمر التالي
gcloud config set project <YOUR_PROJECT_ID>
- بعد ذلك، لنستنسخ دليل العمل الخاص بالنموذج لهذا الدرس التطبيقي حول الترميز من Github، وننفّذ الأمر التالي. سيتم إنشاء دليل العمل في الدليل personal-expense-assistant
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- بعد ذلك، انتقِل إلى القسم العلوي من "محرّر Cloud Shell" (Cloud Shell Editor) وانقر على ملف (File) > فتح مجلد (Open Folder)، وابحث عن دليل اسم المستخدم ودليل personal-expense-assistant، ثم انقر على الزر موافق (OK). سيؤدي ذلك إلى جعل الدليل الذي تم اختياره هو دليل العمل الرئيسي. في هذا المثال، اسم المستخدم هو alvinprayuda، وبالتالي يظهر مسار الدليل أدناه

من المفترض أن يظهر "محرّر Cloud Shell" الآن على النحو التالي
إعداد البيئة
إعداد بيئة Python الافتراضية
الخطوة التالية هي إعداد بيئة التطوير. يجب أن تكون نافذة الجهاز النشطة الحالية داخل دليل العمل personal-expense-assistant. سنستخدم الإصدار 3.12 من Python في هذا الدرس التطبيقي حول الترميز، كما سنستخدم أداة إدارة مشاريع Python (uv) لتسهيل عملية إنشاء إصدار Python وبيئة افتراضية وإدارتهما.
- إذا لم تكن قد فتحت المحطة الطرفية بعد، افتحها بالنقر على المحطة الطرفية -> محطة طرفية جديدة، أو استخدِم Ctrl + Shift + C، وسيؤدي ذلك إلى فتح نافذة محطة طرفية في الجزء السفلي من المتصفح.

- الآن، لنبدأ البيئة الافتراضية باستخدام
uv، وننفّذ الأوامر التالية
cd ~/personal-expense-assistant
uv sync --frozen
سيؤدي ذلك إلى إنشاء الدليل .venv وتثبيت الموارد التابعة. ستمنحك نظرة خاطفة سريعة على pyproject.toml معلومات عن التبعيات المعروضة على النحو التالي
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
إعداد ملفات الإعداد
الآن، علينا إعداد ملفات الضبط لهذا المشروع. نستخدم pydantic-settings لقراءة الإعدادات من ملف YAML.
لقد قدّمنا نموذج الملف داخل settings.yaml.example، وسنحتاج إلى نسخ الملف وإعادة تسميته إلى settings.yaml. نفِّذ الأمر التالي لإنشاء الملف
cp settings.yaml.example settings.yaml
بعد ذلك، انسخ القيمة التالية في الملف
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
في هذا الدرس التطبيقي، سنستخدم القيم التي تم ضبطها مسبقًا لكل من GCLOUD_LOCATION, وBACKEND_URL, وDB_COLLECTION_NAME .
يمكننا الآن الانتقال إلى الخطوة التالية، وهي إنشاء الوكيل ثم الخدمات
3- 🚀 إنشاء الوكيل باستخدام Google ADK وGemini 2.5
مقدّمة حول بنية دليل ADK
لنبدأ باستكشاف ما يقدّمه "مجموعة أدوات تطوير التطبيقات" وكيفية إنشاء الوكيل. يمكنك الاطّلاع على مستندات ADK الكاملة من خلال عنوان URL هذا . توفّر لنا "حزمة تطوير التطبيقات" العديد من الأدوات المساعدة في تنفيذ أوامر واجهة سطر الأوامر. في ما يلي بعض هذه الحالات :
- إعداد بنية دليل الوكيل
- تجربة التفاعل بسرعة من خلال إدخال البيانات وإخراجها عبر واجهة سطر الأوامر
- إعداد واجهة ويب لواجهة مستخدم التطوير المحلي بسرعة
الآن، لننشئ بنية دليل الوكيل باستخدام أمر واجهة سطر الأوامر. نفِّذ الأمر التالي.
uv run adk create expense_manager_agent
عندما يُطلب منك ذلك، اختَر النموذج gemini-2.5-flash وبرنامج Vertex AI الخلفي. سيطلب منك المعالج بعد ذلك إدخال رقم تعريف المشروع وموقعه الجغرافي. يمكنك قبول الخيارات التلقائية بالضغط على مفتاح الإدخال أو تغييرها حسب الضرورة. يُرجى التأكّد من أنّك تستخدم رقم تعريف المشروع الصحيح الذي تم إنشاؤه سابقًا في هذا المختبر. ستبدو النتيجة على النحو التالي:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
سيتم إنشاء بنية دليل الوكيل التالية
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
وإذا فحصت الملفَين init.py وagent.py، سيظهر لك هذا الرمز
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
يمكنك الآن اختباره عن طريق تشغيل
uv run adk run expense_manager_agent
عند الانتهاء من الاختبار، يمكنك الخروج من الوكيل عن طريق كتابة exit أو الضغط على Ctrl+D.
إنشاء وكيل "إدارة النفقات"
لنبدأ بإنشاء وكيل إدارة النفقات. افتح ملف expense_manager_agent/agent.py وانسخ الرمز أدناه الذي سيتضمّن root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
شرح الرمز
يحتوي هذا النص البرمجي على عملية بدء تشغيل الوكيل حيث نضبط القيم الأولية لما يلي:
- ضبط النموذج المراد استخدامه على
gemini-2.5-flash - إعداد وصف الوكيل وتعليماته كتعليمات النظام التي تتم قراءتها من
task_prompt.md - توفير الأدوات اللازمة لدعم وظائف الوكيل
- تفعيل التخطيط قبل إنشاء الردّ النهائي أو تنفيذه باستخدام إمكانات التفكير في Gemini 2.5 Flash
- إعداد اعتراض معاودة الاتصال قبل إرسال الطلب إلى Gemini للحدّ من عدد بيانات الصور المُرسَلة قبل إجراء التوقّع
4. 🚀 ضبط إعدادات أدوات "الوكيل"
سيتمتّع وكيل إدارة النفقات بالقدرات التالية:
- استخراج البيانات من صورة الإيصال وتخزين البيانات والملف
- البحث الدقيق في بيانات النفقات
- البحث السياقي في بيانات النفقات
لذلك، نحتاج إلى الأدوات المناسبة لدعم هذه الوظيفة. أنشئ ملفًا جديدًا ضمن دليل expense_manager_agent وسمِّه tools.py
touch expense_manager_agent/tools.py
افتح الملف expense_manage_agent/tools.py، ثم انسخ الرمز أدناه
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
شرح الرمز
في عملية تنفيذ وظيفة الأدوات هذه، نصمّم الأدوات استنادًا إلى هاتين الفكرتين الرئيسيتين:
- تحليل بيانات الإيصالات وربطها بالملف الأصلي باستخدام عنصر نائب لسلسلة معرّف الصورة
[IMAGE-ID <hash-of-image-1>] - تخزين البيانات واسترجاعها باستخدام قاعدة بيانات Firestore
الأداة "store_receipt_data"
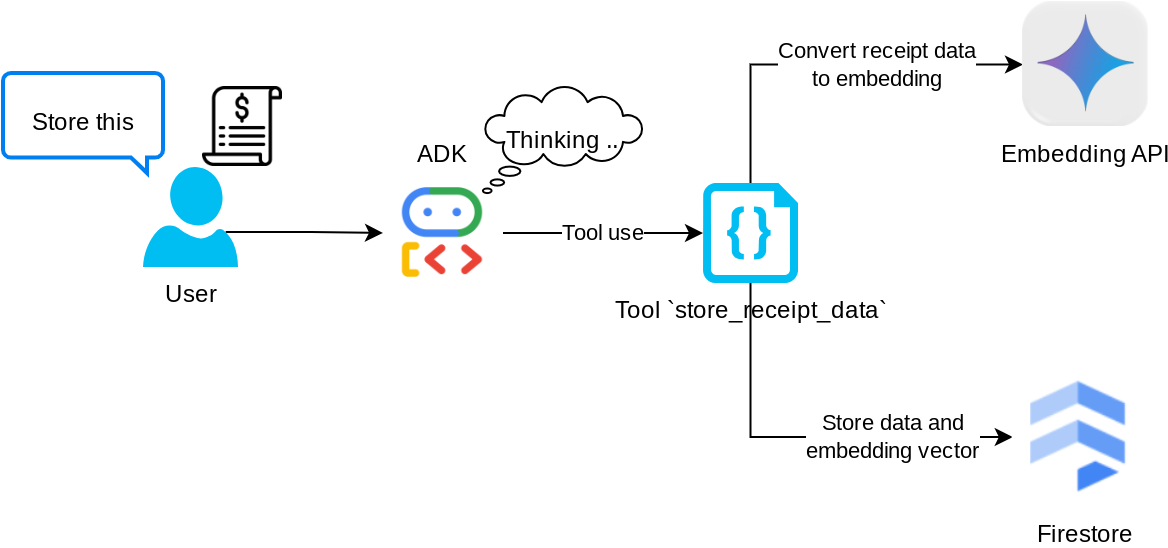
هذه الأداة هي أداة التعرّف البصري على الأحرف، وستحلّل المعلومات المطلوبة من بيانات الصورة، بالإضافة إلى التعرّف على سلسلة رقم تعريف الصورة وربطها معًا لتخزينها في قاعدة بيانات Firestore.
بالإضافة إلى ذلك، تحوّل هذه الأداة أيضًا محتوى الإيصال إلى تضمين باستخدام text-embedding-004، ما يتيح تخزين جميع البيانات الوصفية والتضمين وفهرستهما معًا. تفعيل إمكانية استرداد المعلومات إما من خلال طلب بحث أو بحث سياقي
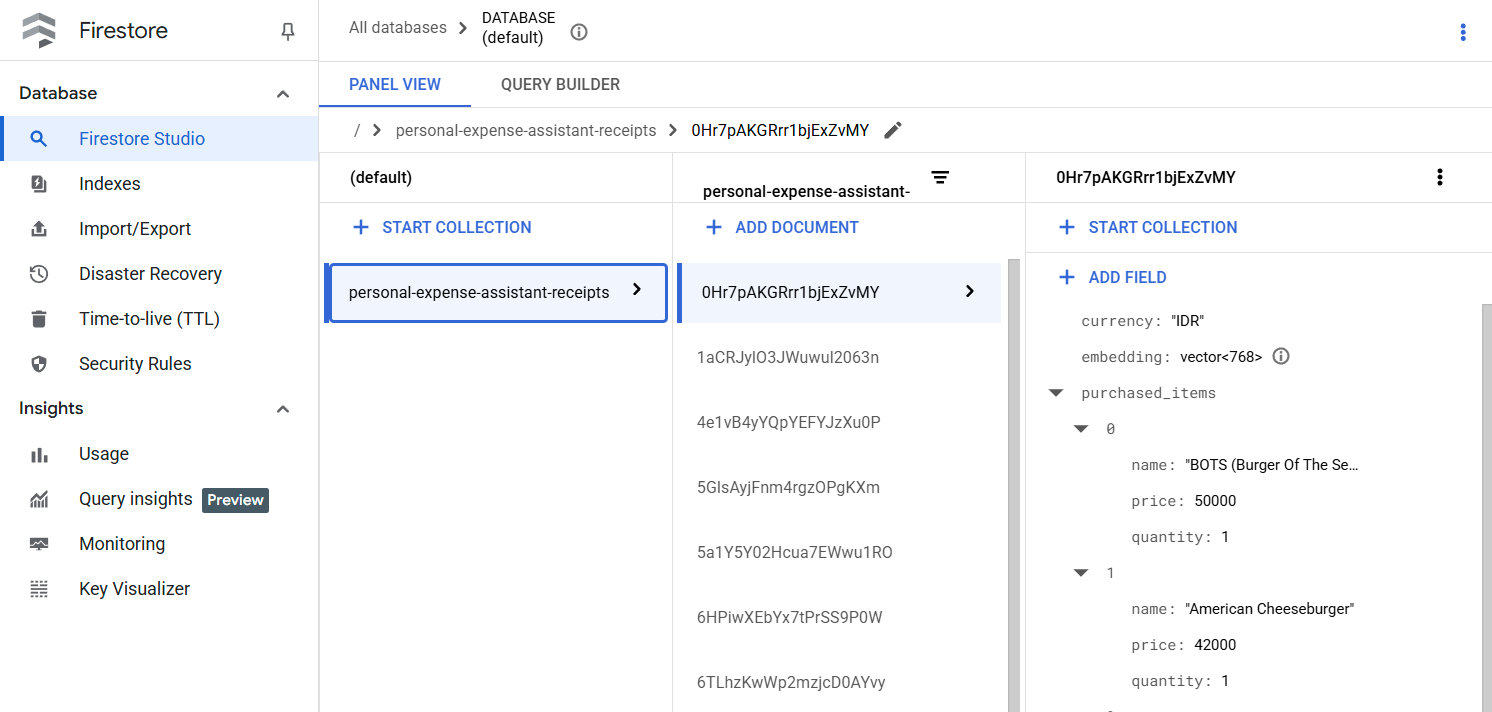
بعد تنفيذ هذه الأداة بنجاح، يمكنك ملاحظة أنّه تم فهرسة بيانات الإيصالات في قاعدة بيانات Firestore كما هو موضّح أدناه
الأداة "search_receipts_by_metadata_filter"
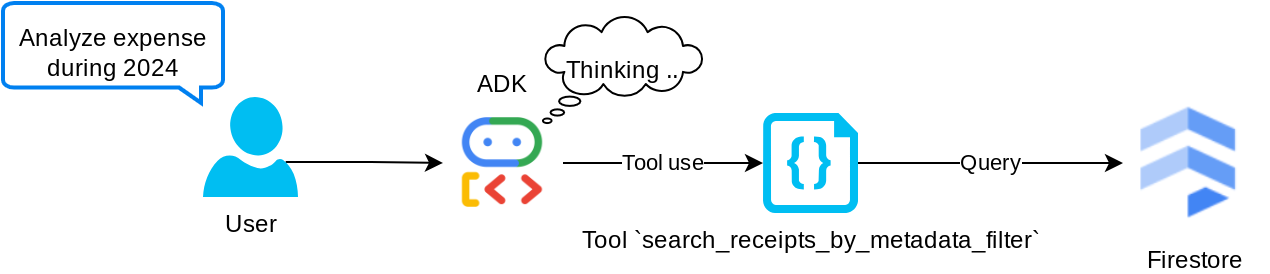
تحوّل هذه الأداة طلب المستخدم إلى فلتر طلب بيانات وصفية يتيح البحث حسب النطاق الزمني و/أو إجمالي المعاملة. سيعرض هذا الإجراء جميع بيانات الإيصالات المطابقة، وسنتجاهل حقل التضمين في هذه العملية لأنّ الوكيل لا يحتاج إليه لفهم السياق.
الأداة "search_relevant_receipts_by_natural_language_query"
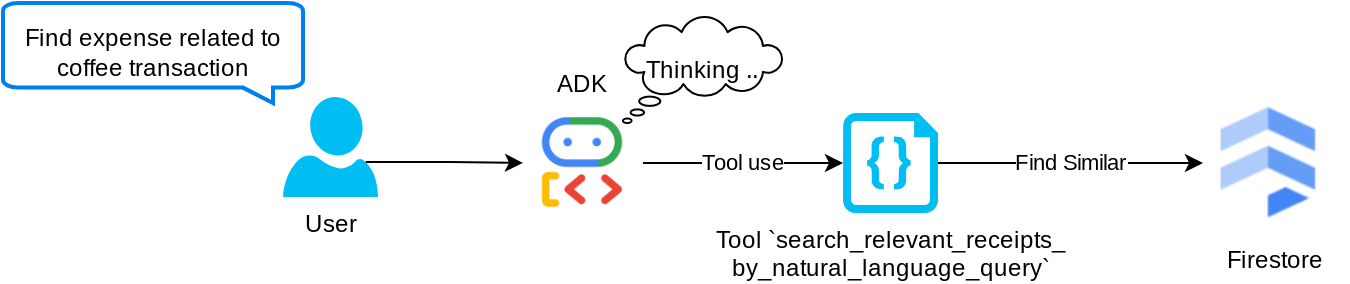
هذه هي أداة "التوليد المعزّز بالاسترجاع" (RAG). بإمكان الوكيل تصميم طلبه الخاص لاسترداد الإيصالات ذات الصلة من قاعدة بيانات المتجهات، ويمكنه أيضًا اختيار وقت استخدام هذه الأداة. إنّ فكرة السماح للوكيل باتخاذ قرار مستقل بشأن استخدام أداة التوليد المعزز بالاسترجاع هذه أو عدم استخدامها وتصميم طلبه الخاص هي أحد تعريفات نهج التوليد المعزز بالاسترجاع المستند إلى الوكيل.
ولا نسمح له بإنشاء طلب البحث الخاص به فحسب، بل نسمح له أيضًا بتحديد عدد المستندات ذات الصلة التي يريد استردادها. بالإضافة إلى هندسة الطلبات المناسبة، مثل
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
سيجعل ذلك هذه الأداة فعّالة وقادرة على البحث عن أي شيء تقريبًا، مع أنّها قد لا تعرض جميع النتائج المتوقّعة بسبب طبيعة البحث غير الدقيق باستخدام أقرب جار.
5- 🚀 تعديل سياق المحادثة من خلال عمليات ردّ الاتصال
تتيح لنا Google ADK "اعتراض" وقت تشغيل الوكيل على مستويات مختلفة. يمكنك الاطّلاع على مزيد من المعلومات حول هذه الإمكانية التفصيلية في هذه المستندات . في هذه التجربة، نستخدم before_model_callback لتعديل الطلب قبل إرساله إلى النموذج اللغوي الكبير من أجل إزالة بيانات الصور في سياق سجلّ المحادثات القديم ( يتم تضمين بيانات الصور في آخر 3 تفاعلات للمستخدم فقط) لتحسين الكفاءة.
ومع ذلك، نريد أن يتوفّر لدى الوكيل سياق بيانات الصورة عند الحاجة. لذلك، نضيف آلية لإضافة عنصر نائب لمعرّف صورة سلسلة بعد كل بيانات بايت للصورة في المحادثة. سيساعد ذلك الوكيل في ربط معرّف الصورة ببيانات الملف الفعلية التي يمكن استخدامها سواء عند تخزين الصورة أو استرجاعها. ستبدو البنية على النحو التالي
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
وعندما تصبح بيانات البايت قديمة في سجلّ المحادثات، يظلّ معرّف السلسلة متاحًا لإتاحة الوصول إلى البيانات بمساعدة استخدام الأداة. مثال على بنية السجلّ بعد إزالة بيانات الصور
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
لنبدأ! أنشئ ملفًا جديدًا ضمن دليل expense_manager_agent وسمِّه callbacks.py
touch expense_manager_agent/callbacks.py
افتح الملف expense_manager_agent/callbacks.py، ثم انسخ الرمز أدناه.
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 الطلب
يتطلّب تصميم وكيل يتمتّع بتفاعل وقدرات معقّدة العثور على طلب كافٍ لتوجيه الوكيل كي يتصرّف بالطريقة التي نريدها.
في السابق، كان لدينا آلية للتعامل مع بيانات الصور في سجلّ المحادثات، كما كانت لدينا أدوات قد لا يكون استخدامها سهلاً، مثل search_relevant_receipts_by_natural_language_query. نريد أيضًا أن يتمكّن الوكيل من البحث عن صورة الإيصال الصحيحة واستردادها. وهذا يعني أنّنا بحاجة إلى نقل كل هذه المعلومات بشكل صحيح في بنية طلب مناسبة
سنطلب من الوكيل تنظيم الناتج بالتنسيق التالي لترميز Markdown من أجل تحليل عملية التفكير والرد النهائي والمرفق ( إن وُجد).
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
لنبدأ بالطلب التالي لتحقيق توقعاتنا الأولية بشأن سلوك وكيل إدارة النفقات. يجب أن يكون الملف task_prompt.md موجودًا في دليل العمل الحالي، ولكن علينا نقله إلى الدليل expense_manager_agent. نفِّذ الأمر التالي لنقلها
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 اختبار الوكيل
لنحاول الآن التواصل مع الوكيل من خلال واجهة سطر الأوامر، وننفّذ الأمر التالي
uv run adk run expense_manager_agent
سيظهر لك ناتج مشابه لما يلي، حيث يمكنك الدردشة بالتناوب مع الوكيل، ولكن يمكنك إرسال نص فقط من خلال هذه الواجهة
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
بالإضافة إلى التفاعل من خلال واجهة سطر الأوامر، يتيح لنا ADK أيضًا توفير واجهة مستخدم خاصة بالتطوير للتفاعل مع ما يحدث أثناء التفاعل وفحصه. نفِّذ الأمر التالي لبدء خادم واجهة المستخدم للتطوير المحلي
uv run adk web --port 8080
سيؤدي ذلك إلى إنشاء ناتج مشابه للمثال التالي، ما يعني أنّه يمكننا الوصول إلى واجهة الويب.
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
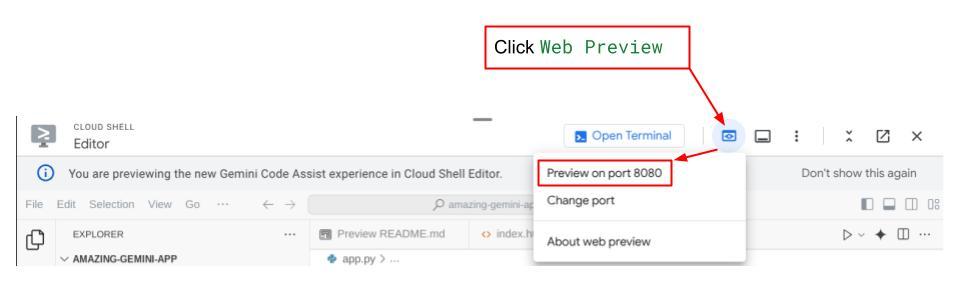
الآن، للتحقّق من ذلك، انقر على الزر معاينة الويب في أعلى منطقة "محرّر Cloud Shell"، ثم انقر على معاينة على المنفذ 8080.
ستظهر لك صفحة الويب التالية حيث يمكنك اختيار الوكلاء المتاحين من زر القائمة المنسدلة في أعلى اليمين ( في حالتنا، يجب أن يكون expense_manager_agent) والتفاعل مع الروبوت. ستظهر لك العديد من المعلومات حول تفاصيل السجلّ أثناء وقت تشغيل الوكيل في النافذة اليمنى.
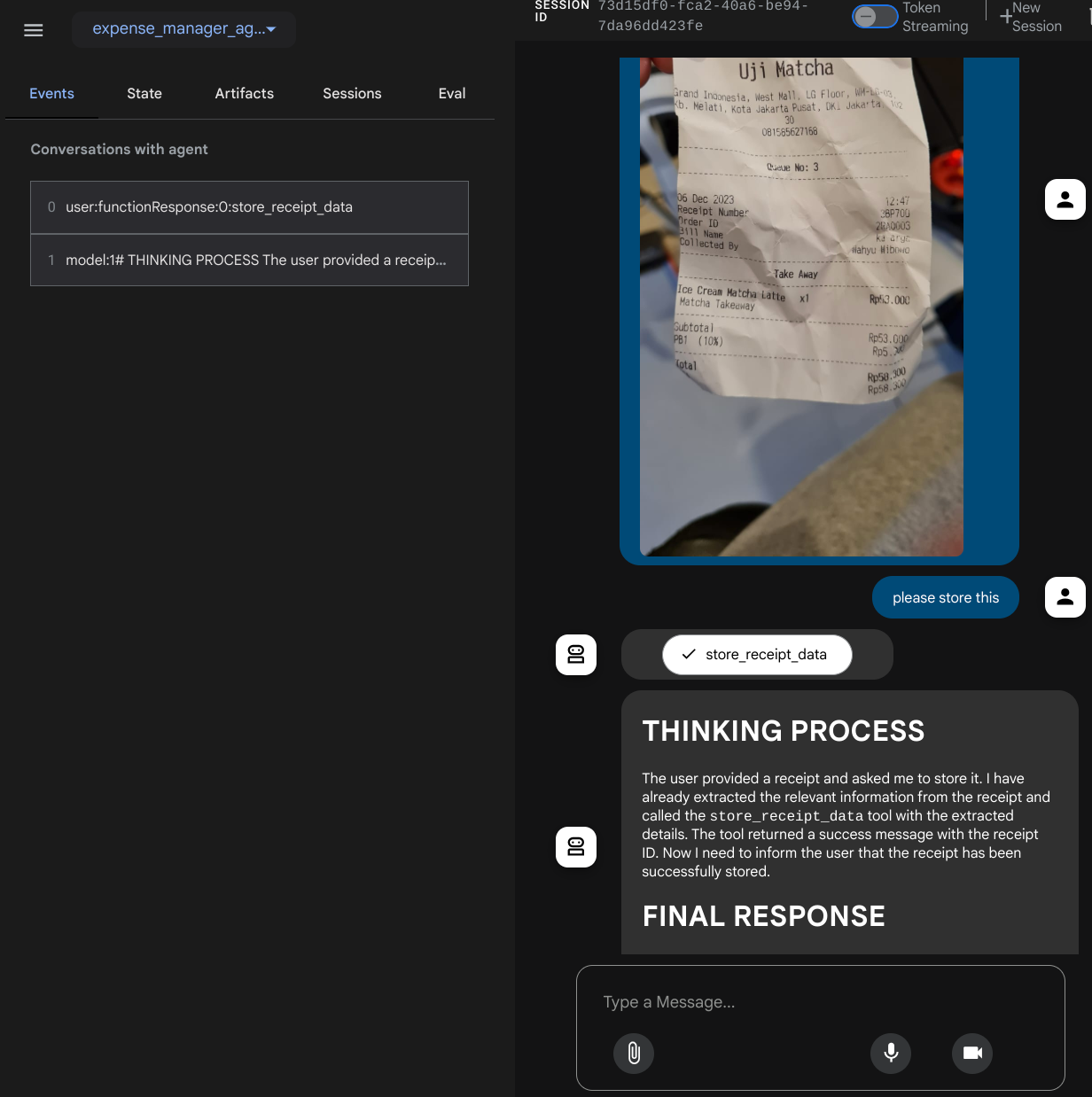
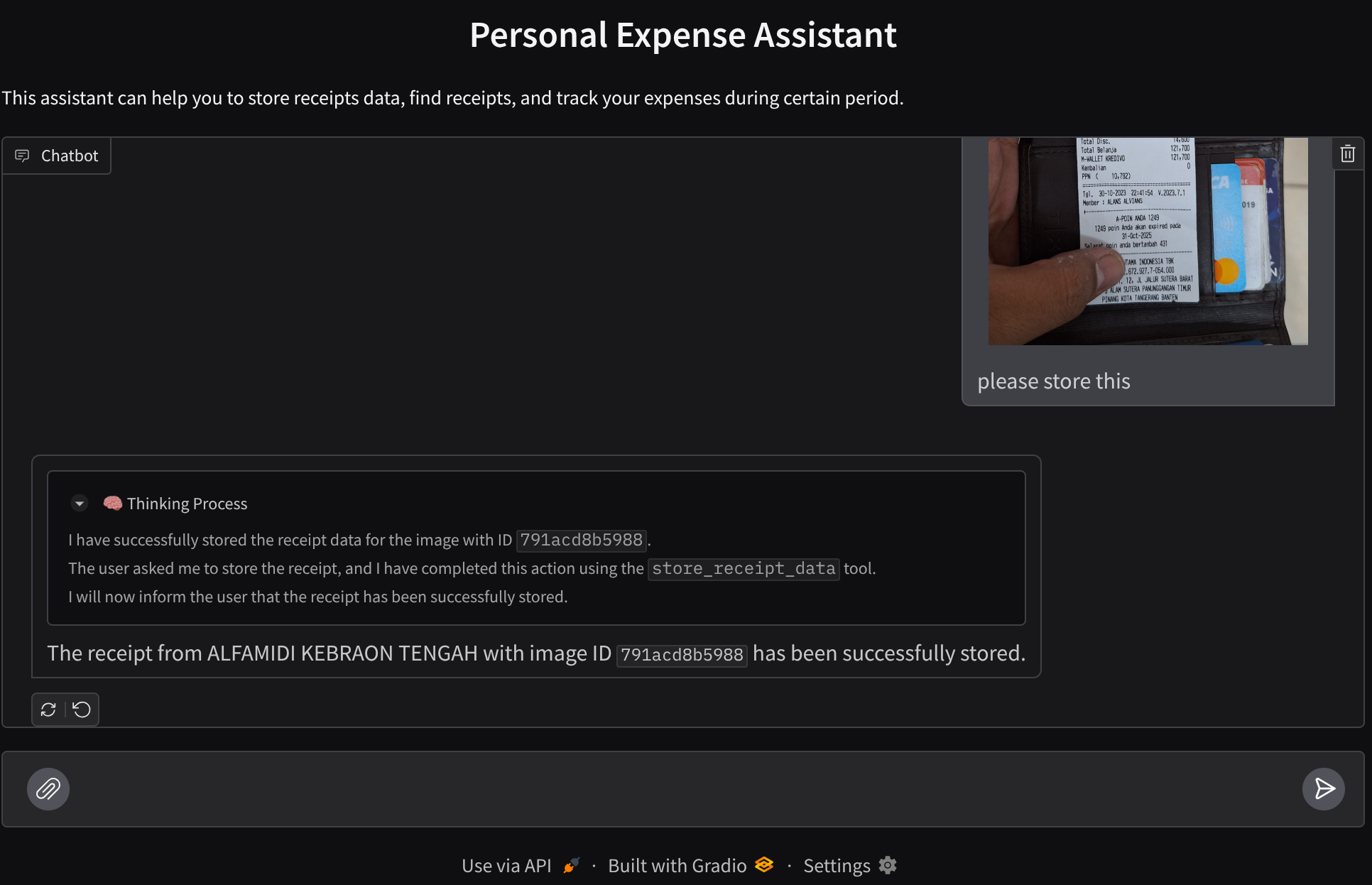
لنستكشف بعض الإجراءات. حمِّل هذين المثالين على الإيصالات ( المصدر : مجموعات بيانات Hugging Face mousserlane/id_receipt_dataset) . انقر بزر الماوس الأيمن على كل صورة واختَر حفظ الصورة باسم... ( سيؤدي ذلك إلى تنزيل صورة الإيصال)، ثم حمِّل الملف إلى البوت من خلال النقر على رمز "المشبك" وأخبِره بأنّك تريد تخزين هذه الإيصالات.


بعد ذلك، جرِّب طلبات البحث التالية لإجراء بعض عمليات البحث أو استرداد الملفات.
- "أريد تفصيلاً للنفقات وإجماليها خلال عام 2023"
- "أريد ملف إيصال من Indomaret"
عند استخدام بعض الأدوات، يمكنك فحص ما يحدث في واجهة مستخدم التطوير
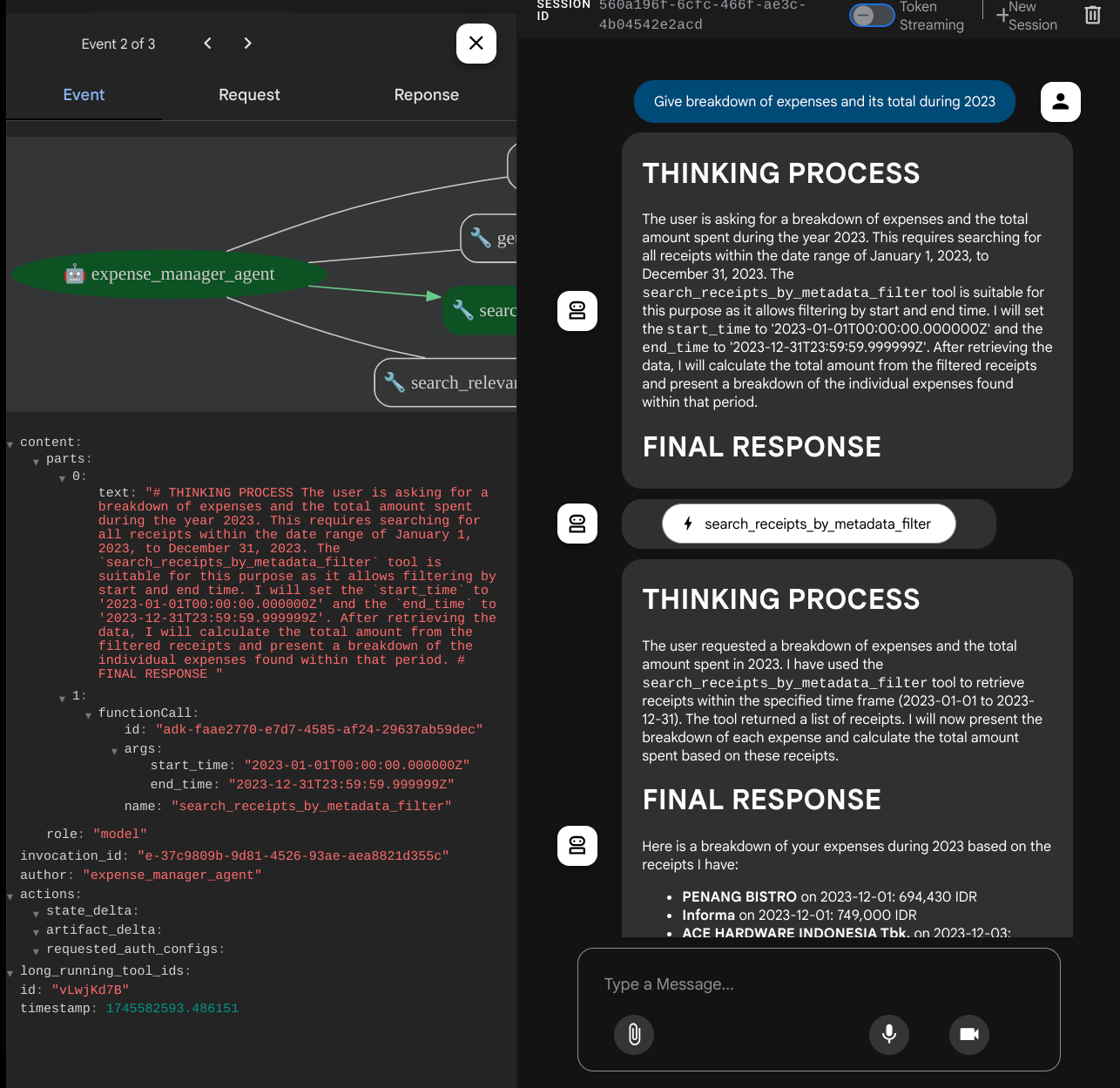
اطّلِع على طريقة ردّ الوكيل عليك وتحقّق مما إذا كان يلتزم بجميع القواعد المقدَّمة في الطلب داخل task_prompt.py. تهانينا! أصبح لديك الآن وكيل تطوير يعمل بشكل كامل.
حان الوقت الآن لإكمالها باستخدام واجهة مستخدم مناسبة وجذابة وإمكانات لتحميل ملف الصورة وتنزيله.
8. 🚀 إنشاء خدمة الواجهة الأمامية باستخدام Gradio
سننشئ واجهة ويب للمحادثة تبدو على النحو التالي
يحتوي على واجهة دردشة مع حقل إدخال ليتمكّن المستخدمون من إرسال النصوص وتحميل ملفات صور الإيصالات.
سننشئ خدمة الواجهة الأمامية باستخدام Gradio.
أنشئ ملفًا جديدًا وسمِّه frontend.py
touch frontend.py
ثم انسخ الرمز التالي واحفظه
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
بعد ذلك، يمكننا محاولة تشغيل خدمة الواجهة الأمامية باستخدام الأمر التالي. لا تنسَ إعادة تسمية الملف main.py إلى frontend.py
uv run frontend.py
ستظهر لك نتيجة مشابهة لهذه في Cloud Console
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
بعد ذلك، يمكنك التحقّق من واجهة الويب عند الضغط على ctrl+click على رابط عنوان URL المحلي. بدلاً من ذلك، يمكنك أيضًا الوصول إلى تطبيق الواجهة الأمامية من خلال النقر على زر معاينة الويب في أعلى يسار "أداة التعديل على السحابة الإلكترونية"، ثم النقر على معاينة على المنفذ 8080.
سيظهر لك واجهة الويب، ولكن ستتلقّى الخطأ المتوقّع عند محاولة إرسال المحادثة بسبب عدم إعداد خدمة الخلفية بعد.
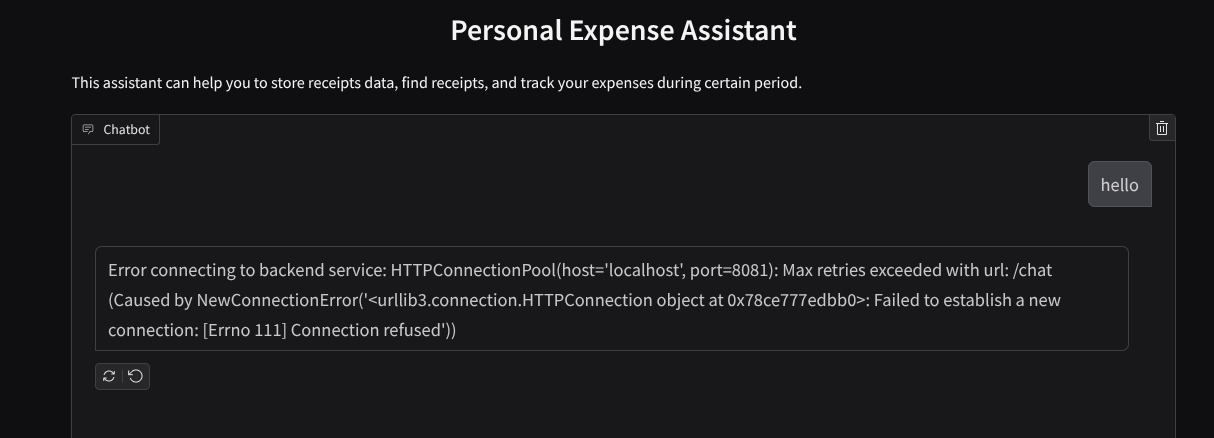
الآن، دع الخدمة تعمل ولا توقفها بعد. سنشغّل خدمة الخلفية في علامة تبويب أخرى في الوحدة الطرفية
شرح الرمز
في رمز الواجهة الأمامية هذا، نتيح للمستخدم أولاً إرسال نص وتحميل ملفات متعددة. تتيح لنا مكتبة Gradio إنشاء هذا النوع من الوظائف باستخدام طريقة gr.ChatInterface مع gr.MultimodalTextbox
قبل إرسال الملف والنص إلى الخلفية، علينا تحديد نوع MIME للملف لأنّ الخلفية تحتاج إليه. علينا أيضًا ترميز بايت ملف الصورة إلى base64 وإرساله مع نوع MIME.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
يتم تحديد المخطط المستخدَم للتفاعل بين الواجهة الأمامية والخلفية في schema.py. نستخدم Pydantic BaseModel لفرض التحقّق من صحة البيانات في المخطّط.
عند تلقّي الردّ، نفصل الجزء الذي يمثّل عملية التفكير عن الردّ النهائي والمرفق. وبالتالي، يمكننا استخدام مكوّن Gradio لعرض كل مكوّن مع مكوّن واجهة المستخدم.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9- 🚀 إنشاء خدمة خلفية باستخدام FastAPI
بعد ذلك، علينا إنشاء الخلفية التي يمكنها تهيئة الوكيل مع المكوّنات الأخرى لتتمكّن من تنفيذ بيئة تشغيل الوكيل.
أنشئ ملفًا جديدًا وسمِّه backend.py.
touch backend.py
ونسخ الرمز التالي
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
بعد ذلك، يمكننا محاولة تشغيل خدمة الخلفية. تذكَّر أنّه في الخطوة السابقة، شغّلنا خدمة الواجهة الأمامية بشكل صحيح، والآن سنحتاج إلى فتح وحدة طرفية جديدة ومحاولة تشغيل خدمة الخلفية هذه.
- أنشئ نافذة طرفية جديدة. انتقِل إلى نافذة الوحدة الطرفية في المنطقة السفلية وابحث عن زر "+" لإنشاء وحدة طرفية جديدة. يمكنك بدلاً من ذلك الضغط على Ctrl + Shift + C لفتح وحدة طرفية جديدة.

- بعد ذلك، تأكَّد من أنّك في دليل العمل personal-expense-assistant، ثم نفِّذ الأمر التالي
uv run backend.py
- في حال النجاح، ستظهر المخرجات على النحو التالي
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
شرح الرمز
تهيئة وكيل ADK وSessionService وArtifactService
لتشغيل الوكيل في خدمة الخلفية، علينا إنشاء Runner يأخذ كلاً من SessionService والوكيل. ستدير SessionService سجلّ المحادثات وحالتها، وبالتالي عند دمجها مع Runner، ستمنح وكيلنا القدرة على تلقّي سياق المحادثات الجارية.
نستخدم أيضًا ArtifactService للتعامل مع الملف الذي تم تحميله. يمكنك الاطّلاع على مزيد من التفاصيل حول الجلسة والعناصر في حزمة تطوير البرامج الإعلانية هنا.
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
في هذا العرض التوضيحي، نستخدم InMemorySessionService وGcsArtifactService لدمجهما مع وكيلنا Runner. بما أنّ سجلّ المحادثات يتم تخزينه في الذاكرة، سيتم فقدانه عند إيقاف خدمة الخلفية أو إعادة تشغيلها. نبدأ هذه العمليات داخل مراحل نشاط تطبيق FastAPI ليتم إدخالها كاعتمادية في المسار /chat.
تحميل الصور وتنزيلها باستخدام GcsArtifactService
سيتم تخزين جميع الصور التي تم تحميلها كعنصر بواسطة GcsArtifactService، ويمكنك التحقّق من ذلك داخل الدالة format_user_request_to_adk_content_and_store_artifacts في utils.py.
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
يجب تنسيق جميع الطلبات التي ستتم معالجتها بواسطة برنامج تشغيل الوكيل في النوع types.Content. داخل الدالة، نعالج أيضًا بيانات كل صورة ونستخرج رقم تعريفها ليتم استبداله بعنصر نائب لمعرّف الصورة.
يتم استخدام آلية مشابهة لتنزيل المرفقات بعد استخراج أرقام تعريف الصور باستخدام التعبيرات العادية:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 اختبار الدمج
من المفترض الآن أن يتم تشغيل خدمات متعدّدة في علامات تبويب مختلفة في وحدة تحكّم السحابة:
- تشغيل خدمة الواجهة الأمامية على المنفذ 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- تشغيل خدمة الخلفية على المنفذ 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
في الحالة الحالية، من المفترض أن تتمكّن من تحميل صور الإيصالات والدردشة بسلاسة مع المساعد من تطبيق الويب على المنفذ 8080.
انقر على الزر معاينة الويب في أعلى مساحة Cloud Shell Editor واختَر المعاينة على المنفذ 8080.
لنبدأ الآن بالتفاعل مع "المساعد".
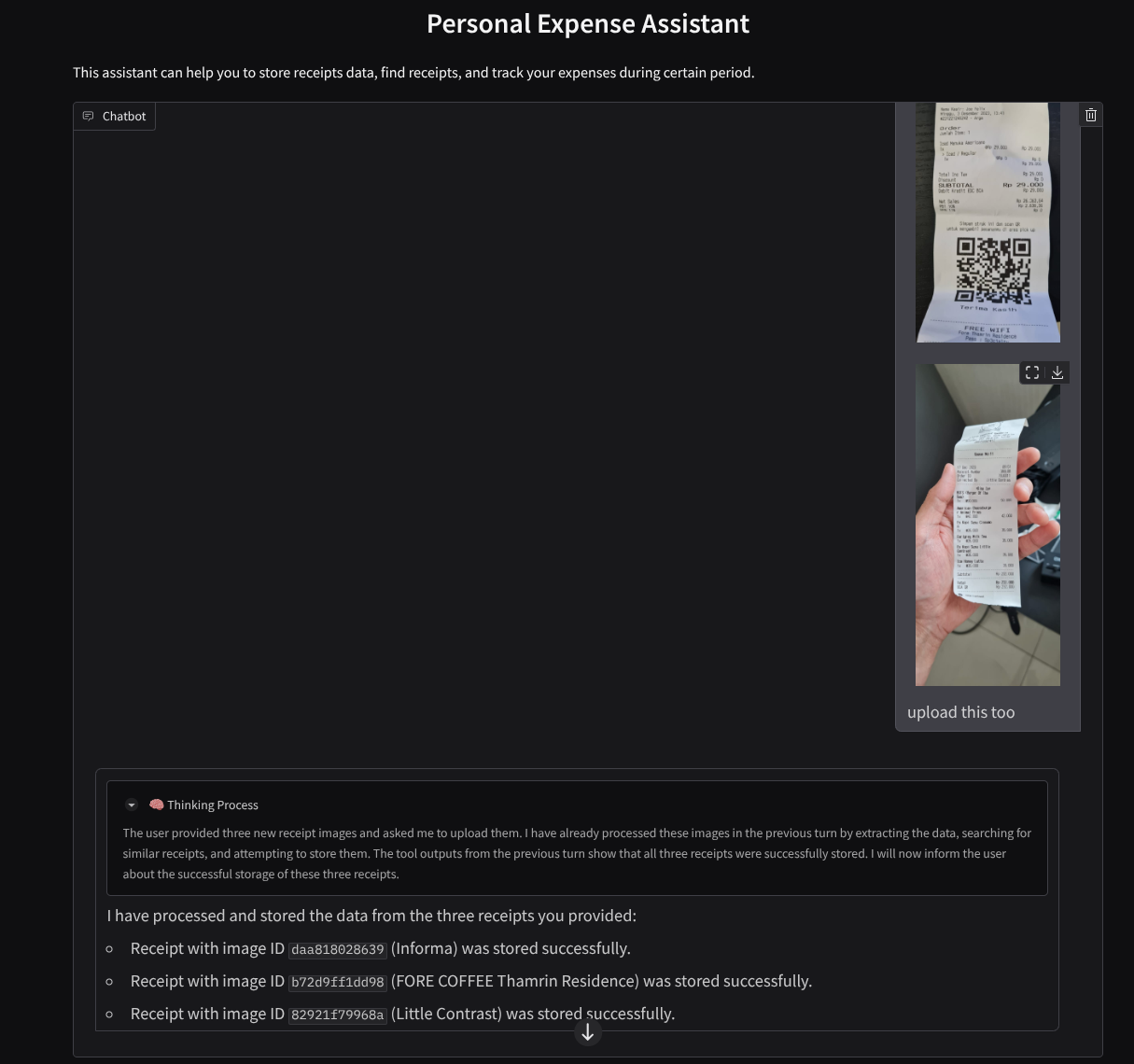
نزِّل الإيصالات التالية. نطاق التاريخ لبيانات الإيصالات هذا هو بين عامَي 2023 و2024، ويطلب من المساعد تخزينها أو تحميلها.
- Receipt Drive ( المصدر: مجموعات بيانات Hugging Face
mousserlane/id_receipt_dataset)
طرح أسئلة متنوعة
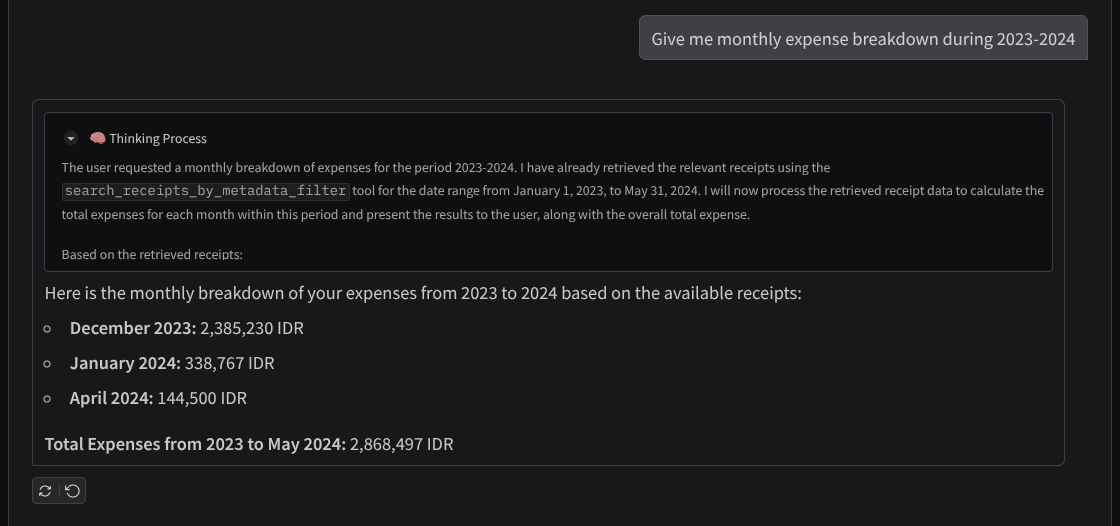
- "أريد تفصيلاً للنفقات الشهرية خلال الفترة 2023-2024"
- "عرض إيصال معاملة شراء القهوة"
- "أريد ملف إيصال من مطعم Yakiniku Like"
- Etc
في ما يلي مقتطف من تفاعل ناجح
11. 🚀 النشر على Cloud Run
بالطبع، نريد الوصول إلى هذا التطبيق الرائع من أي مكان. ولإجراء ذلك، يمكننا تجميع هذا التطبيق ونشره على Cloud Run. لأغراض هذا العرض التوضيحي، سيتم عرض هذه الخدمة كخدمة عامة يمكن للآخرين الوصول إليها. ومع ذلك، يُرجى العِلم أنّ هذه ليست أفضل ممارسة لهذا النوع من التطبيقات، لأنّها أكثر ملاءمةً للتطبيقات الشخصية.
في هذا الدرس التطبيقي حول الترميز، سنضع كلاً من خدمة الواجهة الأمامية وخدمة الخلفية في حاوية واحدة. سنحتاج إلى مساعدة supervisord لإدارة كلتا الخدمتين. يمكنك فحص ملف supervisord.conf والتحقّق من Dockerfile الذي ضبطنا فيه supervisord كنقطة دخول.
في هذه المرحلة، تتوفّر لدينا جميع الملفات اللازمة لنشر تطبيقاتنا على Cloud Run، فلنبدأ عملية النشر. انتقِل إلى "وحدة طرفية Cloud Shell" وتأكَّد من ضبط المشروع الحالي على مشروعك النشط. وإذا لم يكن كذلك، عليك استخدام الأمر gcloud configure لضبط رقم تعريف المشروع:
gcloud config set project [PROJECT_ID]
بعد ذلك، شغِّل الأمر التالي لنشره على Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
إذا طُلب منك تأكيد إنشاء سجلّ عناصر لملف Docker، ما عليك سوى الإجابة بـ Y. يُرجى العِلم أنّنا نسمح بالوصول غير المصادَق عليه هنا لأنّ هذا التطبيق هو تطبيق تجريبي. ننصحك باستخدام المصادقة المناسبة لتطبيقات المؤسسة والإنتاج.
بعد اكتمال عملية النشر، من المفترض أن تحصل على رابط مشابه لما يلي:
https://personal-expense-assistant-*******.us-central1.run.app
يمكنك المتابعة واستخدام التطبيق من نافذة التصفّح المتخفي أو جهازك الجوّال. من المفترض أن يكون قد تم نشره.
12. 🎯 التحدّي
حان الوقت الآن للتألق وصقل مهاراتك الاستكشافية. هل لديك المهارات اللازمة لتغيير الرمز البرمجي كي يتمكّن الخلفية من استيعاب عدة مستخدمين؟ ما هي المكوّنات التي يجب تعديلها؟
13. 🧹 تنظيف
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذا الدرس التطبيقي حول الترميز، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة إدارة الموارد.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
- بدلاً من ذلك، يمكنك الانتقال إلى Cloud Run في وحدة التحكّم، واختيار الخدمة التي نشرتها للتو وحذفها.