
1. نظرة عامة
BigQuery هو مستودع بيانات إحصاءات مُدار بالكامل ومنخفض التكلفة على نطاق بيتابايت من Google. لا تتطلّب BigQuery أي عمليات، إذ لا تحتاج إلى إدارة أي بنية أساسية ولا تحتاج إلى مسؤول قاعدة بيانات، ما يتيح لك التركيز على تحليل البيانات للعثور على إحصاءات مفيدة واستخدام لغة SQL المألوفة والاستفادة من نموذج الدفع حسب الاستخدام.
في هذا الدرس التطبيقي حول الترميز، ستستخدم مكتبة برامج Google Cloud BigQuery لطلب البحث في مجموعات بيانات BigQuery العامة باستخدام Node.js.
ما ستتعلمه
- كيفية استخدام Cloud Shell
- كيفية تفعيل BigQuery API
- كيفية مصادقة طلبات البيانات من واجهة برمجة التطبيقات
- كيفية تثبيت مكتبة برامج BigQuery لنظام التشغيل Node.js
- كيفية البحث عن أعمال شكسبير
- كيفية تشغيل طلب بحث في مجموعة بيانات GitHub
- كيفية ضبط إعدادات التخزين المؤقت وعرض الإحصاءات
المتطلبات
استطلاع الرأي
كيف ستستخدم هذا البرنامج التعليمي؟
كيف تقيّم تجربتك مع Node.js؟
ما هو تقييمك لتجربة استخدام خدمات Google Cloud Platform؟
2. الإعداد والمتطلبات
إعداد البيئة بالسرعة التي تناسبك
- سجِّل الدخول إلى Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. (إذا لم يكن لديك حساب على Gmail أو G Suite، عليك إنشاء حساب).


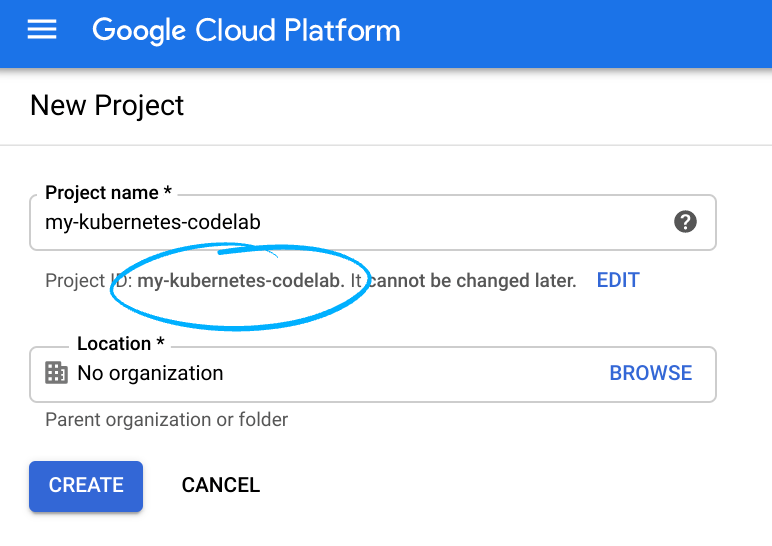
تذكَّر رقم تعريف المشروع، وهو اسم فريد في جميع مشاريع Google Cloud (الاسم أعلاه مستخدَم حاليًا ولن يكون متاحًا لك، نأسف لذلك). سيتم الإشارة إليه لاحقًا في هذا الدرس العملي باسم PROJECT_ID.
- بعد ذلك، عليك تفعيل الفوترة في Cloud Console من أجل استخدام موارد Google Cloud.
لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز الكثير من المال، إن لم تكلفك شيئًا على الإطلاق. احرص على اتّباع أي تعليمات في قسم "التنظيف" الذي ينصحك بكيفية إيقاف الموارد حتى لا تتحمّل رسومًا تتجاوز هذا البرنامج التعليمي. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل أداة سطر الأوامر Cloud SDK عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس التطبيقي حول الترميز Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
تفعيل Cloud Shell
- من Cloud Console، انقر على تفعيل Cloud Shell
.

إذا لم يسبق لك بدء Cloud Shell، ستظهر لك شاشة وسيطة (الجزء السفلي غير المرئي من الصفحة) توضّح ماهيته. في هذه الحالة، انقر على متابعة (ولن تظهر لك مرة أخرى). في ما يلي الشكل الذي ستظهر به هذه الشاشة لمرة واحدة:

يستغرق توفير Cloud Shell والاتصال به بضع لحظات فقط.

يتم تحميل هذا الجهاز الافتراضي بجميع أدوات التطوير التي تحتاج إليها. توفّر هذه الخدمة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت وتعمل في Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إنجاز معظم العمل في هذا الدرس التطبيقي حول الترميز، إن لم يكن كله، باستخدام متصفّح أو جهاز Chromebook فقط.
بعد الاتصال بـ Cloud Shell، من المفترض أن يظهر لك أنّه تم إثبات هويتك وأنّه تم ضبط المشروع على رقم تعريف مشروعك.
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من إكمال عملية المصادقة:
gcloud auth list
ناتج الأمر
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
ناتج الأمر
[core] project = <PROJECT_ID>
إذا لم يكن كذلك، يمكنك تعيينه من خلال هذا الأمر:
gcloud config set project <PROJECT_ID>
ناتج الأمر
Updated property [core/project].
3- تفعيل BigQuery API
يجب أن تكون BigQuery API مفعَّلة تلقائيًا في جميع مشاريع Google Cloud. يمكنك التحقّق من صحة ذلك باستخدام الأمر التالي في Cloud Shell:
gcloud services list
من المفترض أن يظهر BigQuery في القائمة:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
إذا لم تكن BigQuery API مفعّلة، يمكنك استخدام الأمر التالي في Cloud Shell لتفعيلها:
gcloud services enable bigquery-json.googleapis.com
4. مصادقة طلبات البيانات من واجهة برمجة التطبيقات
لإرسال طلبات إلى BigQuery API، عليك استخدام حساب خدمة. حساب الخدمة هو حساب يخص مشروعك، وتستخدمه مكتبة برامج Google BigQuery Node.js لإجراء طلبات BigQuery API. وكما هو الحال مع أي حساب مستخدم آخر، يتم تمثيل حساب الخدمة بعنوان بريد إلكتروني. في هذا القسم، ستستخدم Cloud SDK لإنشاء حساب خدمة، ثم ستنشئ بيانات الاعتماد اللازمة للمصادقة بصفتك حساب الخدمة.
أولاً، اضبط متغيّر بيئة باستخدام PROJECT_ID الذي ستستخدمه خلال هذا الدرس التطبيقي حول الترميز:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
بعد ذلك، أنشئ حساب خدمة جديدًا للوصول إلى BigQuery API باستخدام:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
بعد ذلك، أنشِئ بيانات اعتماد سيستخدمها رمز Node.js لتسجيل الدخول بصفتك حساب الخدمة الجديد. أنشئ بيانات الاعتماد هذه واحفظها كملف JSON باسم "~/key.json" باستخدام الأمر التالي:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
أخيرًا، اضبط متغيّر البيئة GOOGLE_APPLICATION_CREDENTIALS الذي تستخدمه مكتبة BigQuery API C#، والتي سيتم تناولها في الخطوة التالية، للعثور على بيانات الاعتماد. يجب ضبط متغيّر البيئة على المسار الكامل لملف JSON الخاص ببيانات الاعتماد الذي أنشأته. اضبط متغيّر البيئة باستخدام الأمر التالي:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
يمكنك الاطّلاع على مزيد من المعلومات حول المصادقة على BigQuery API.
5- إعداد التحكّم في إمكانية الوصول
يستخدم BigQuery خدمة "إدارة الهوية وإمكانية الوصول" (IAM) لإدارة إمكانية الوصول إلى الموارد. يتضمّن BigQuery عددًا من الأدوار المحدّدة مسبقًا (مستخدم ومالك بيانات وعارض بيانات وما إلى ذلك) يمكنك تعيينها لحساب الخدمة الذي أنشأته في الخطوة السابقة. يمكنك الاطّلاع على مزيد من المعلومات عن التحكّم في الوصول في مستندات BigQuery.
قبل أن تتمكّن من طلب البحث في مجموعات البيانات العامة، عليك التأكّد من أنّ حساب الخدمة لديه دور bigquery.user على الأقل. في Cloud Shell، نفِّذ الأمر التالي لإسناد دور bigquery.user إلى حساب الخدمة:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
يمكنك تنفيذ الأمر التالي للتأكّد من أنّ حساب الخدمة تمّ تعيينه لدور المستخدم:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. تثبيت مكتبة عميل BigQuery لنظام التشغيل Node.js
أولاً، أنشئ مجلدًا باسم BigQueryDemo وانتقِل إليه:
mkdir BigQueryDemo
cd BigQueryDemo
بعد ذلك، أنشئ مشروع Node.js الذي ستستخدمه لتشغيل نماذج مكتبة برامج BigQuery:
npm init -y
من المفترض أن يظهر لك مشروع Node.js الذي تم إنشاؤه:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
ثبِّت مكتبة برامج BigQuery:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
أنت الآن جاهز لاستخدام مكتبة عميل BigQuery Node.js.
7. الاستعلام عن أعمال شكسبير
مجموعة البيانات العامة هي أي مجموعة بيانات يتم تخزينها في BigQuery وتكون متاحة لعامة الجمهور. تتوفّر العديد من مجموعات البيانات العامة الأخرى التي يمكنك طلب البحث فيها، بعضها تستضيفه Google، والعديد منها تستضيفه جهات خارجية. يمكنك قراءة المزيد من المعلومات في صفحة مجموعات البيانات العامة.
بالإضافة إلى مجموعات البيانات العامة، توفّر BigQuery عددًا محدودًا من جداول العيّنات التي يمكنك طلب البحث فيها. يتم تضمين هذه الجداول في bigquery-public-data:samples dataset. أحد هذه الجداول يُسمى shakespeare. ويحتوي على فهرس كلمات لأعمال شكسبير، مع توضيح عدد المرات التي تظهر فيها كل كلمة في كل مجموعة نصوص.
في هذه الخطوة، ستستعلم عن جدول shakespeare.
أولاً، افتح أداة تعديل الرموز من أعلى يسار Cloud Shell:
أنشئ ملف queryShakespeare.js داخل المجلد BigQueryDemo :
touch queryShakespeare.js
انتقِل إلى ملف queryShakespeare.js وأدرِج الرمز التالي:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
يُرجى تخصيص دقيقة أو دقيقتين لدراسة الرمز البرمجي والاطّلاع على كيفية طلب البيانات من الجدول.
في Cloud Shell، شغِّل التطبيق:
node queryShakespeare.js
ستظهر لك قائمة بالكلمات وعدد مرات تكرارها:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. الاستعلام عن مجموعة بيانات GitHub
للتعرّف أكثر على BigQuery، ستُصدر الآن طلب بحث مقابل مجموعة بيانات GitHub العامة. يمكنك العثور على رسائل عمليات الإيداع الأكثر شيوعًا على GitHub. ستستخدم أيضًا واجهة مستخدم الويب في BigQuery لمعاينة طلبات البحث المخصّصة وتنفيذها.
لعرض البيانات، افتح مجموعة بيانات GitHub في واجهة مستخدم الويب في BigQuery:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
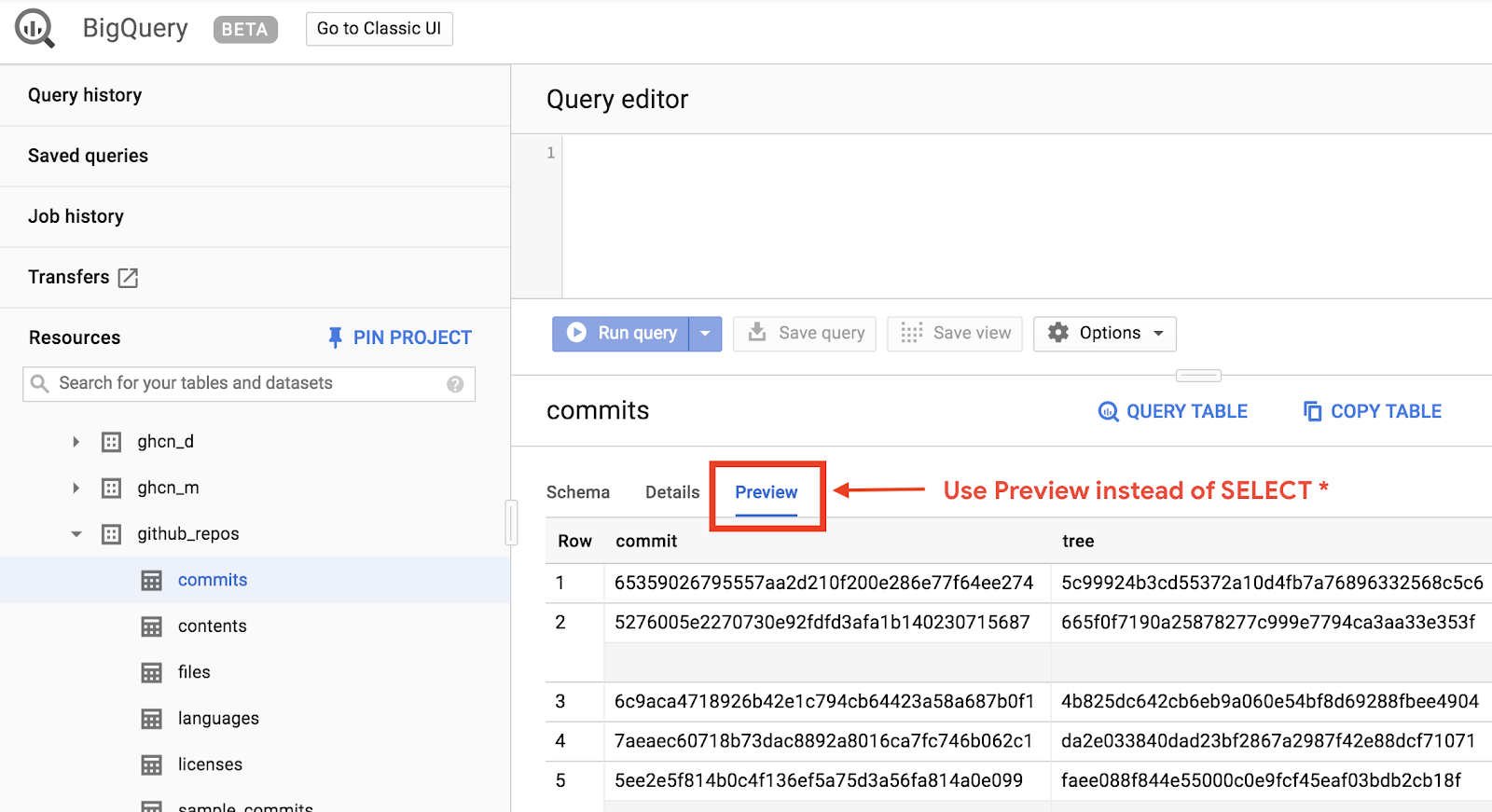
للحصول على معاينة سريعة لشكل البيانات، انقر على علامة التبويب "معاينة":
أنشئ الملف queryGitHub.js داخل المجلد BigQueryDemo:
touch queryGitHub.js
انتقِل إلى ملف queryGitHub.js وأدرِج الرمز التالي:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
يستغرق الأمر دقيقة أو دقيقتين لدراسة الرمز البرمجي ومعرفة كيفية طلب البحث من الجدول عن رسائل عمليات الإيداع الأكثر شيوعًا.
في Cloud Shell، شغِّل التطبيق:
node queryGitHub.js
ستظهر لك قائمة برسائل عمليات الدمج وعدد مرات حدوثها:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9- التخزين المؤقت والإحصاءات
عند تنفيذ طلب بحث، تخزّن BigQuery النتائج مؤقتًا. نتيجةً لذلك، تستغرق طلبات البحث المتطابقة اللاحقة وقتًا أقل بكثير. يمكنك إيقاف التخزين المؤقت باستخدام خيارات طلب البحث. يتتبّع BigQuery أيضًا بعض الإحصاءات حول طلبات البحث، مثل وقت الإنشاء ووقت الانتهاء وإجمالي عدد وحدات البايت التي تمت معالجتها.
في هذه الخطوة، ستوقف التخزين المؤقت وتعرض بعض الإحصاءات حول طلبات البحث.
انتقِل إلى ملف queryShakespeare.js داخل مجلد BigQueryDemo واستبدِل الرمز بالرمز التالي:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
في ما يلي بعض الملاحظات حول الرمز. أولاً، يتم إيقاف التخزين المؤقت من خلال ضبط UseQueryCache على false داخل العنصر options. ثانيًا، يمكنك الوصول إلى إحصاءات حول الاستعلام من عنصر المهمة.
في Cloud Shell، شغِّل التطبيق:
node queryShakespeare.js
من المفترض أن تظهر لك قائمة برسائل عمليات الدمج وعدد مرات حدوثها. بالإضافة إلى ذلك، من المفترض أن تظهر لك بعض الإحصاءات حول طلب البحث:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. تحميل البيانات إلى BigQuery
إذا أردت طلب البحث عن بياناتك، عليك أولاً تحميل بياناتك إلى BigQuery. تتيح BigQuery تحميل البيانات من مصادر عديدة، مثل Google Cloud Storage أو خدمات Google الأخرى أو مصدر محلي قابل للقراءة. يمكنك حتى بث بياناتك. يمكنك الاطّلاع على مزيد من المعلومات في صفحة تحميل البيانات إلى BigQuery.
في هذه الخطوة، ستحمّل ملف JSON مخزَّنًا في Google Cloud Storage إلى جدول BigQuery. يقع ملف JSON في: gs://cloud-samples-data/bigquery/us-states/us-states.json
إذا كنت مهتمًا بمعرفة محتوى ملف JSON، يمكنك استخدام أداة سطر الأوامر gsutil لتنزيله في Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
يمكنك ملاحظة أنّه يحتوي على قائمة بالولايات الأمريكية، وكل ولاية هي عنصر JSON في سطر منفصل:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
لتحميل ملف JSON هذا إلى BigQuery، أنشئ ملف createDataset.js وملف loadBigQueryJSON.js داخل المجلد BigQueryDemo:
touch createDataset.js
touch loadBigQueryJSON.js
ثبِّت مكتبة برامج Google Cloud Storage Node.js:
npm install --save @google-cloud/storage
انتقِل إلى ملف createDataset.js وأدرِج الرمز التالي:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
بعد ذلك، انتقِل إلى ملف loadBigQueryJSON.js وأدرِج الرمز التالي:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
خصِّص دقيقة أو دقيقتَين لدراسة كيفية تحميل الرمز لملف JSON وإنشاء جدول (يتضمّن مخططًا) في مجموعة بيانات.
في Cloud Shell، شغِّل التطبيق:
node createDataset.js
node loadBigQueryJSON.js
يتم إنشاء مجموعة بيانات وجدول في BigQuery:
Table my_states_table created.
Job [JOB ID] completed.
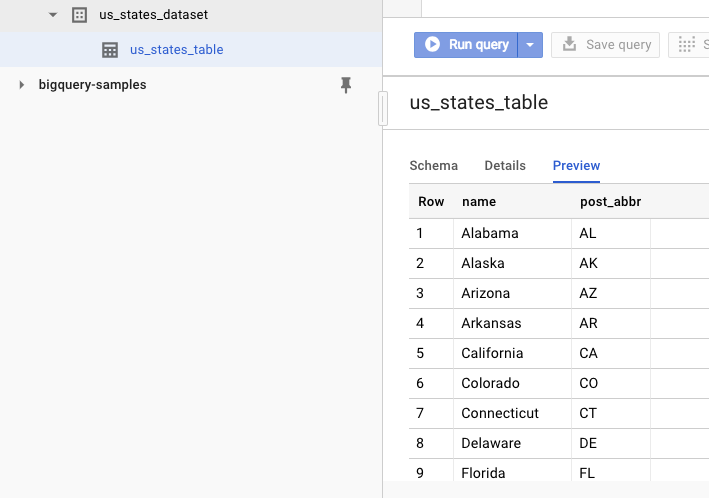
للتأكّد من إنشاء مجموعة البيانات، يمكنك الانتقال إلى واجهة مستخدم الويب في BigQuery. من المفترض أن تظهر لك مجموعة بيانات وجدول جديدان. إذا انتقلت إلى علامة التبويب "معاينة" في الجدول، يمكنك الاطّلاع على البيانات الفعلية:
11. تهانينا!
لقد تعلّمت كيفية استخدام BigQuery باستخدام Node.js.
تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud Platform مقابل الموارد المستخدَمة في هذا الدليل السريع، اتّبِع الخطوات التالية:
- انتقِل إلى وحدة تحكّم Cloud Platform.
- اختَر المشروع الذي تريد إيقافه، ثم انقر على "حذف" في أعلى الصفحة: يؤدي ذلك إلى تحديد موعد لحذف المشروع.
مزيد من المعلومات
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js على Google Cloud Platform: https://cloud.google.com/nodejs/
- مكتبة برامج Google BigQuery Node.js: https://github.com/googleapis/nodejs-bigquery
الترخيص
يخضع هذا العمل لترخيص المشاع الإبداعي مع نسب العمل إلى مؤلفه 2.0 Generic License.