
1. Übersicht
BigQuery ist das vollständig verwaltete, kostengünstige Data Warehouse von Google für Analysen im Petabyte-Bereich. BigQuery ist ein NoOps-Angebot. Es muss keine Infrastruktur verwaltet werden. Da Sie keinen Datenbankadministrator benötigen, können Sie sich ganz auf die Analyse der Daten konzentrieren und über vertraute SQL-Befehle aussagekräftige Informationen erhalten. Dabei profitieren Sie von unserem Pay-As-You-Go-Modell.
In diesem Codelab verwenden Sie die Google Cloud BigQuery-Clientbibliothek, um öffentliche BigQuery-Datasets mit Node.js abzufragen.
Lerninhalte
- Cloud Shell verwenden
- BigQuery API aktivieren
- API-Anfragen authentifizieren
- BigQuery-Clientbibliothek für Node.js installieren
- Werke von Shakespeare abfragen
- GitHub-Dataset abfragen
- Caching- und Statistikanzeige anpassen
Voraussetzungen
Umfrage
Wie werden Sie diese Anleitung verwenden?
Wie würden Sie Ihre Erfahrung mit Node.js bewerten?
Wie würden Sie Ihre Erfahrungen mit der Verwendung von Google Cloud Platform-Diensten bewerten?
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes Projekt. Wenn Sie noch kein Gmail- oder G Suite-Konto haben, müssen Sie eines erstellen.


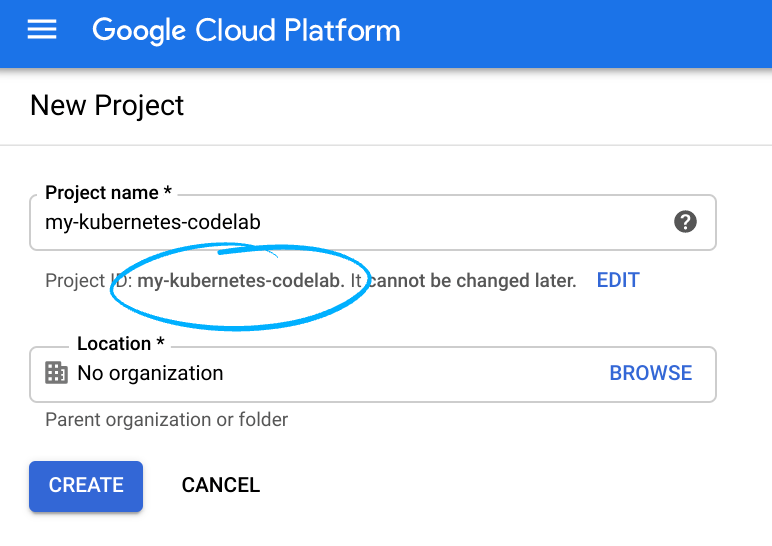
Notieren Sie sich die Projekt-ID, also den projektübergreifend nur einmal vorkommenden Namen eines Google Cloud-Projekts. Der oben angegebene Name ist bereits vergeben und kann leider nicht mehr verwendet werden. Sie wird später in diesem Codelab als PROJECT_ID bezeichnet.
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Die Durchführung dieses Codelabs sollte keine oder nur geringe Kosten verursachen. Folgen Sie bitte der Anleitung im Abschnitt „Bereinigen“, in der Sie erfahren, wie Sie Ressourcen herunterfahren können, damit nach Abschluss dieser Anleitung keine Gebühren anfallen. Neue Nutzer von Google Cloud kommen für das Programm für den kostenlosen Testzeitraum mit einem Guthaben von 300$ infrage.
Cloud Shell starten
Das Cloud SDK-Befehlszeilentool kann zwar per Fernzugriff von Ihrem Laptop aus bedient werden, in diesem Codelab verwenden Sie jedoch Google Cloud Shell, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Cloud Shell aktivieren
- Klicken Sie in der Cloud Console auf Cloud Shell aktivieren
.

Wenn Sie die Cloud Shell zuvor noch nicht gestartet haben, wird ein Fenster mit einer Beschreibung eingeblendet. Klicken Sie in diesem Fall einfach auf Weiter. So sieht dieses Fenster aus:

Das Herstellen der Verbindung mit der Cloud Shell sollte nur wenige Augenblicke dauern.

Auf dieser virtuellen Maschine sind alle Entwicklungstools installiert, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Die meisten, wenn nicht sogar alle Aufgaben in diesem Codelab können mit einem Browser oder Ihrem Chromebook erledigt werden.
Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist.
- Führen Sie in der Cloud Shell den folgenden Befehl aus, um zu prüfen, ob Sie authentifiziert sind:
gcloud auth list
Befehlsausgabe
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Befehlsausgabe
[core] project = <PROJECT_ID>
Ist dies nicht der Fall, können Sie die Einstellung mit diesem Befehl vornehmen:
gcloud config set project <PROJECT_ID>
Befehlsausgabe
Updated property [core/project].
3. Aktivieren der BigQuery-API
Die BigQuery API sollte standardmäßig in allen Google Cloud-Projekten aktiviert sein. Mit dem folgenden Befehl in Cloud Shell können Sie prüfen, ob dies der Fall ist:
gcloud services list
BigQuery sollte aufgeführt sein:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
Wenn die BigQuery API nicht aktiviert ist, können Sie sie mit dem folgenden Befehl in der Cloud Shell aktivieren:
gcloud services enable bigquery-json.googleapis.com
4. API-Anfragen authentifizieren
Für Anfragen an die BigQuery API müssen Sie ein Dienstkonto verwenden. Das Dienstkonto gehört zu Ihrem Projekt und wird von der Google BigQuery Node.js-Clientbibliothek zum Ausführen von BigQuery API-Anfragen verwendet. Wie jedes andere Nutzerkonto wird auch ein Dienstkonto durch eine E‑Mail-Adresse dargestellt. In diesem Abschnitt verwenden Sie das Cloud SDK, um ein Dienstkonto zu erstellen. Anschließend erstellen Sie die Anmeldedaten, die Sie für die Authentifizierung als Dienstkonto benötigen.
Zuerst legen Sie mit Ihrer PROJECT_ID eine Umgebungsvariable fest, die Sie in diesem Codelab verwenden werden:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Erstellen Sie als Nächstes ein neues Dienstkonto, um auf die BigQuery API zuzugreifen:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Erstellen Sie als Nächstes Anmeldedaten, die der Node.js-Code verwendet, um sich mit dem neuen Dienstkonto anzumelden. Erstellen Sie die Anmeldedaten und speichern Sie sie mit dem folgenden Befehl als JSON-Datei ~/key.json:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Legen Sie schließlich die Umgebungsvariable GOOGLE_APPLICATION_CREDENTIALS fest, die von der BigQuery API C#-Bibliothek (im nächsten Schritt beschrieben) verwendet wird, um Ihre Anmeldedaten zu finden. Die Umgebungsvariable sollte auf den vollständigen Pfad der von Ihnen erstellten JSON-Datei mit den Anmeldedaten festgelegt werden. Legen Sie die Umgebungsvariable mit dem folgenden Befehl fest:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
Weitere Informationen zur Authentifizierung der BigQuery API
5. Zugriffssteuerung einrichten
BigQuery verwendet die Identitäts- und Zugriffsverwaltung (Identity and Access Management, IAM), um den Zugriff auf Ressourcen zu verwalten. BigQuery bietet eine Reihe vordefinierter Rollen (Nutzer, Dateninhaber, Datenbetrachter usw.), die Sie dem Dienstkonto zuweisen können, das Sie im vorherigen Schritt erstellt haben. Weitere Informationen zur Zugriffssteuerung finden Sie in der BigQuery-Dokumentation.
Bevor Sie die öffentlichen Datasets abfragen können, muss das Dienstkonto mindestens die Rolle bigquery.user haben. Führen Sie in Cloud Shell den folgenden Befehl aus, um dem Dienstkonto die Rolle „bigquery.user“ zuzuweisen:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Mit dem folgenden Befehl können Sie prüfen, ob dem Dienstkonto die Nutzerrolle zugewiesen ist:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. BigQuery-Clientbibliothek für Node.js installieren
Erstellen Sie zuerst einen Ordner mit dem Namen BigQueryDemo und rufen Sie ihn auf:
mkdir BigQueryDemo
cd BigQueryDemo
Erstellen Sie als Nächstes ein Node.js-Projekt, mit dem Sie Beispiele für die BigQuery-Clientbibliothek ausführen:
npm init -y
Das erstellte Node.js-Projekt sollte angezeigt werden:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Installieren Sie die BigQuery-Clientbibliothek:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Sie können jetzt die BigQuery Node.js-Clientbibliothek verwenden.
7. Werke von Shakespeare abfragen
Ein öffentliches Dataset ist ein Dataset, das in BigQuery gespeichert ist und der Allgemeinheit zugänglich gemacht wird. Es sind viele andere öffentliche Datasets vorhanden, die Sie abfragen können. Einige dieser Datasets werden auch von Google gehostet, viele andere jedoch von Drittanbietern. Weitere Informationen finden Sie auf der Seite Öffentliche Datasets.
Zusätzlich zu den öffentlichen Datasets stellt BigQuery eine begrenzte Anzahl von Beispieltabellen bereit, die Sie abfragen können. Diese Tabellen sind in bigquery-public-data:samples dataset enthalten. Eine dieser Tabellen heißt shakespeare.. Sie enthält einen Wortindex der Werke von Shakespeare und gibt an, wie häufig jedes Wort in jedem Werk vorkommt.
In diesem Schritt führen Sie eine Abfrage für die Tabelle „shakespeare“ aus.
Öffnen Sie zuerst den Code-Editor rechts oben in Cloud Shell:

Erstellen Sie im Ordner BigQueryDemo eine Datei queryShakespeare.js :
touch queryShakespeare.js
Rufen Sie die Datei queryShakespeare.js auf und fügen Sie den folgenden Code ein:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Nehmen Sie sich ein oder zwei Minuten Zeit, um sich den Code anzusehen und zu sehen, wie die Tabelle abgefragt wird.
Führen Sie die App in Cloud Shell aus:
node queryShakespeare.js
Es sollte eine Liste mit Wörtern und deren Vorkommen angezeigt werden:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. GitHub-Dataset abfragen
Um sich besser mit BigQuery vertraut zu machen, führen Sie jetzt eine Abfrage für das öffentliche GitHub-Dataset aus. Die häufigsten Commit-Nachrichten finden Sie auf GitHub. Sie verwenden die BigQuery-Web-UI auch, um Ad-hoc-Abfragen in der Vorschau anzusehen und auszuführen.
So rufen Sie die Daten auf: Öffnen Sie das GitHub-Dataset in der BigQuery-Web-UI:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Wenn Sie sich eine schnelle Vorschau der Daten ansehen möchten, klicken Sie auf den Tab „Vorschau“:

Erstellen Sie die Datei queryGitHub.js im Ordner BigQueryDemo:
touch queryGitHub.js
Rufen Sie die Datei queryGitHub.js auf und fügen Sie den folgenden Code ein:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Nehmen Sie sich ein oder zwei Minuten Zeit, um sich den Code anzusehen und zu sehen, wie die Tabelle nach den häufigsten Commit-Nachrichten durchsucht wird.
Führen Sie die App in Cloud Shell aus:
node queryGitHub.js
Sie sollten eine Liste mit Commit-Nachrichten und ihren Vorkommen sehen:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Caching und Statistiken
Wenn Sie eine Abfrage ausführen, werden die Ergebnisse in BigQuery im Cache gespeichert. Daher dauert es bei nachfolgenden identischen Anfragen viel weniger Zeit. Sie können das Caching mit den Abfrageoptionen deaktivieren. BigQuery erfasst auch einige Statistiken zu den Abfragen, z. B. Erstellungszeit, Endzeit und insgesamt verarbeitete Byte.
In diesem Schritt deaktivieren Sie das Caching und lassen einige Statistiken zu den Anfragen anzeigen.
Rufen Sie die Datei queryShakespeare.js im Ordner BigQueryDemo auf und ersetzen Sie den Code durch Folgendes:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Einige Hinweise zum Code: Zuerst wird das Caching deaktiviert, indem UseQueryCache im Objekt options auf false gesetzt wird. Zweitens haben Sie über das Jobobjekt auf die Statistiken zur Abfrage zugegriffen.
Führen Sie die App in Cloud Shell aus:
node queryShakespeare.js
Sie sollten eine Liste mit Commit-Nachrichten und deren Vorkommen sehen. Außerdem sollten Sie einige Statistiken zur Abfrage sehen:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Daten in BigQuery laden
Wenn Sie Ihre eigenen Daten abfragen möchten, müssen Sie sie zuerst in BigQuery laden. BigQuery unterstützt das Laden von Daten aus vielen Quellen, z. B. Google Cloud Storage, anderen Google-Diensten oder einer lokalen, lesbaren Quelle. Sie können Ihre Daten sogar streamen. Weitere Informationen finden Sie auf der Seite Daten in BigQuery laden.
In diesem Schritt laden Sie eine in Google Cloud Storage gespeicherte JSON-Datei in eine BigQuery-Tabelle. Die JSON-Datei befindet sich unter: gs://cloud-samples-data/bigquery/us-states/us-states.json
Wenn Sie sich für den Inhalt der JSON-Datei interessieren, können Sie sie mit dem gsutil-Befehlszeilentool in Cloud Shell herunterladen:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Sie sehen, dass sie die Liste der US-Bundesstaaten enthält und jeder Bundesstaat ein JSON-Objekt in einer separaten Zeile ist:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Wenn Sie diese JSON-Datei in BigQuery laden möchten, erstellen Sie eine createDataset.js-Datei und eine loadBigQueryJSON.js-Datei im Ordner BigQueryDemo:
touch createDataset.js
touch loadBigQueryJSON.js
Installieren Sie die Google Cloud Storage Node.js-Clientbibliothek:
npm install --save @google-cloud/storage
Rufen Sie die Datei createDataset.js auf und fügen Sie den folgenden Code ein:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Rufen Sie dann die Datei loadBigQueryJSON.js auf und fügen Sie den folgenden Code ein:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Nehmen Sie sich ein bis zwei Minuten Zeit, um sich anzusehen, wie mit dem Code die JSON-Datei geladen und eine Tabelle (mit einem Schema) in einem Dataset erstellt wird.
Führen Sie die App in Cloud Shell aus:
node createDataset.js
node loadBigQueryJSON.js
In BigQuery werden ein Dataset und eine Tabelle erstellt:
Table my_states_table created.
Job [JOB ID] completed.
Sie können in der BigQuery-Web-UI prüfen, ob das Dataset erstellt wurde. Sie sollten ein neues Dataset und eine Tabelle sehen. Wenn Sie zum Tab „Vorschau“ der Tabelle wechseln, sehen Sie die tatsächlichen Daten:

11. Glückwunsch!
Sie haben gelernt, wie Sie BigQuery mit Node.js verwenden.
Bereinigen
So vermeiden Sie, dass Ihr Google Cloud Platform-Konto für die in diesem Schnellstart verwendeten Ressourcen belastet wird:
- Rufen Sie die Cloud Platform Console auf.
- Wählen Sie das Projekt aus, das Sie beenden möchten, und klicken Sie oben auf „Löschen“. Das Projekt wird dann zum Löschen geplant.
Weitere Informationen
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js auf der Google Cloud Platform: https://cloud.google.com/nodejs/
- Google BigQuery Node.js-Clientbibliothek: https://github.com/googleapis/nodejs-bigquery
Lizenz
Dieser Text ist mit einer Creative Commons Attribution 2.0 Generic License lizenziert.