
1. Présentation
BigQuery est l'entrepôt de données analytiques de Google. Entièrement géré, il permet de traiter plusieurs pétaoctets de données à faible coût. BigQuery est une solution NoOps. Vous n'avez donc aucune infrastructure à gérer, et vous n'avez pas besoin de faire appel à un administrateur de base de données. Vous pouvez ainsi vous concentrer sur l'analyse des données pour dégager des insights pertinents, utiliser un langage SQL qui vous est familier et profiter de notre modèle de facturation à l'utilisation.
Dans cet atelier de programmation, vous allez utiliser la bibliothèque cliente Google Cloud BigQuery pour interroger des ensembles de données publics BigQuery avec Node.js.
Points abordés
- Utiliser Cloud Shell
- Activer l'API BigQuery
- Authentifier les requêtes API
- Installer la bibliothèque cliente BigQuery pour Node.js
- Interroger les œuvres de Shakespeare
- Interroger l'ensemble de données GitHub
- Ajuster la mise en cache et les statistiques d'affichage
Prérequis
- Un projet Google Cloud Platform
- Un navigateur tel que Chrome ou Firefox
- Vous maîtrisez l'utilisation de Node.js.
Enquête
Comment allez-vous utiliser ce tutoriel ?
Comment évalueriez-vous votre expérience avec Node.js ?
Quel est votre niveau d'expérience avec les services Google Cloud Platform ?
2. Préparation
Configuration de l'environnement d'auto-formation
- Connectez-vous à Cloud Console, puis créez un projet ou réutilisez un projet existant. (Si vous n'avez pas encore de compte Gmail ou G Suite, vous devez en créer un.)


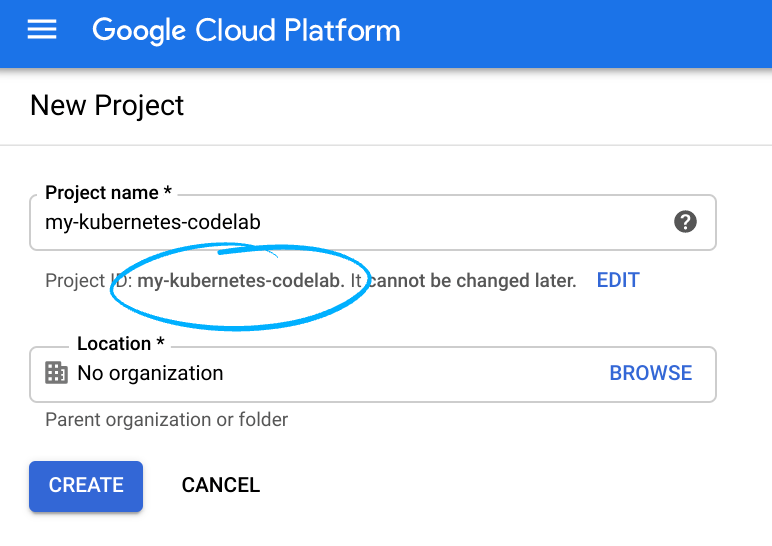
Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
- Vous devez ensuite activer la facturation dans Cloud Console pour pouvoir utiliser les ressources Google Cloud.
L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Veillez à suivre les instructions de la section "Nettoyer" qui indique comment désactiver les ressources afin d'éviter les frais une fois ce tutoriel terminé. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que l'outil de ligne de commande du SDK Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Activer Cloud Shell
- Dans Cloud Console, cliquez sur Activer Cloud Shell
.

Si vous n'avez jamais démarré Cloud Shell auparavant, un écran intermédiaire s'affiche en dessous de la ligne de flottaison, décrivant de quoi il s'agit. Si tel est le cas, cliquez sur Continuer. Cet écran ne s'affiche qu'une seule fois. Voici à quoi il ressemble :

Le provisionnement et la connexion à Cloud Shell ne devraient pas prendre plus de quelques minutes.

Cette machine virtuelle contient tous les outils de développement dont vous avez besoin. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez réaliser une grande partie, voire la totalité, des activités de cet atelier dans un simple navigateur ou sur votre Chromebook.
Une fois connecté à Cloud Shell, vous êtes en principe authentifié et le projet est défini avec votre ID de projet.
- Exécutez la commande suivante dans Cloud Shell pour vérifier que vous êtes authentifié :
gcloud auth list
Résultat de la commande
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si vous obtenez un résultat différent, exécutez cette commande :
gcloud config set project <PROJECT_ID>
Résultat de la commande
Updated property [core/project].
3. Activer l'API BigQuery
L'API BigQuery doit être activée par défaut dans tous les projets Google Cloud. Pour vérifier que c'est le cas, exécutez la commande suivante dans Cloud Shell :
gcloud services list
BigQuery devrait s'afficher :
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
Si l'API BigQuery n'est pas activée, vous pouvez utiliser la commande suivante dans Cloud Shell pour l'activer :
gcloud services enable bigquery-json.googleapis.com
4. Authentifier les requêtes API
Pour envoyer des requêtes à l'API BigQuery, vous devez utiliser un compte de service. Ce compte de service appartient à votre projet. Il permet à la bibliothèque cliente Node.js de Google BigQuery d'envoyer des requêtes à l'API BigQuery. Comme tout autre compte utilisateur, un compte de service est représenté par une adresse e-mail. Dans cette section, vous allez utiliser le SDK Cloud pour créer un compte de service, puis créer les identifiants nécessaires pour vous authentifier en tant que compte de service.
Commencez par définir une variable d'environnement avec votre ID_PROJET que vous utiliserez tout au long de cet atelier de programmation :
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Créez ensuite un compte de service pour accéder à l'API BigQuery à l'aide de la commande suivante :
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Créez ensuite des identifiants permettant à votre code Node.js de se connecter avec ce nouveau compte de service, et enregistrez-les dans un fichier JSON ~/key.json à l'aide de la commande suivante :
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Enfin, définissez la variable d'environnement GOOGLE_APPLICATION_CREDENTIALS, qui permet à la bibliothèque C# de l'API BigQuery, abordée à l'étape suivante, de trouver vos identifiants. La variable d'environnement doit être définie sur le chemin d'accès complet au fichier JSON des identifiants que vous avez créé. Définissez la variable d'environnement à l'aide de la commande suivante :
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
Pour en savoir plus sur l'authentification de l'API BigQuery, consultez la documentation.
5. Configurer le contrôle des accès
BigQuery utilise Identity and Access Management (IAM) pour gérer l'accès aux ressources. BigQuery propose plusieurs rôles prédéfinis (utilisateur, propriétaire des données, lecteur de données, etc.) que vous pouvez attribuer au compte de service que vous avez créé à l'étape précédente. Pour en savoir plus sur le contrôle des accès, consultez la documentation BigQuery.
Avant de pouvoir interroger les ensembles de données publics, vous devez vous assurer que le compte de service dispose au moins du rôle bigquery.user. Dans Cloud Shell, exécutez la commande suivante pour attribuer le rôle bigquery.user au compte de service :
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Vous pouvez exécuter la commande suivante pour vérifier que le rôle utilisateur est attribué au compte de service :
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Installer la bibliothèque cliente BigQuery pour Node.js
Commencez par créer un dossier BigQueryDemo et accédez-y :
mkdir BigQueryDemo
cd BigQueryDemo
Créez ensuite un projet Node.js que vous utiliserez pour exécuter des exemples de bibliothèque cliente BigQuery :
npm init -y
Le projet Node.js créé doit s'afficher :
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Installez la bibliothèque cliente BigQuery :
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Vous êtes maintenant prêt à utiliser la bibliothèque cliente BigQuery pour Node.js.
7. Interroger les œuvres de Shakespeare
Un ensemble de données public est un ensemble de données stocké dans BigQuery et mis à la disposition du grand public. Vous pouvez interroger de nombreux autres ensembles de données publics. Certains sont hébergés par Google, mais bien d'autres sont hébergés par des tiers. Pour en savoir plus, consultez la page Ensembles de données publics.
En plus des ensembles de données publics, BigQuery propose un nombre limité d'exemples de tables que vous pouvez interroger. Ces tables sont contenues dans bigquery-public-data:samples dataset. L'une de ces tables s'appelle shakespeare.. Elle contient un index de mots des œuvres de Shakespeare, indiquant le nombre de fois où chaque mot apparaît dans chaque corpus.
Dans cette étape, vous allez interroger la table "shakespeare".
Tout d'abord, ouvrez l'éditeur de code en haut à droite de Cloud Shell :

Créez un fichier queryShakespeare.js dans le dossier BigQueryDemo :
touch queryShakespeare.js
Accédez au fichier queryShakespeare.js et insérez le code suivant :
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Prenez une ou deux minutes pour étudier le code et voir comment la table est interrogée.
Retournez dans Cloud Shell et exécutez l'application :
node queryShakespeare.js
Une liste de mots et de leurs occurrences devrait s'afficher :
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. Interroger l'ensemble de données GitHub
Pour vous familiariser davantage avec BigQuery, vous allez maintenant exécuter une requête sur l'ensemble de données public GitHub. Vous trouverez les messages de commit les plus courants sur GitHub. Vous utiliserez également l'interface utilisateur Web de BigQuery pour prévisualiser et exécuter des requêtes ad hoc.
Pour afficher les données, ouvrez l'ensemble de données GitHub dans l'interface utilisateur Web de BigQuery :
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Pour obtenir un aperçu rapide des données, cliquez sur l'onglet "Aperçu" :

Créez le fichier queryGitHub.js dans le dossier BigQueryDemo :
touch queryGitHub.js
Accédez au fichier queryGitHub.js et insérez le code suivant :
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Prenez une ou deux minutes pour étudier le code et voir comment la table est interrogée pour obtenir les messages de commit les plus courants.
Retournez dans Cloud Shell et exécutez l'application :
node queryGitHub.js
Une liste des messages de commit et de leurs occurrences devrait s'afficher :
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Mise en cache et statistiques
Lorsque vous exécutez une requête, BigQuery met en cache les résultats. Par conséquent, les requêtes identiques suivantes prennent beaucoup moins de temps. Il est possible de désactiver la mise en cache à l'aide des options de requête. BigQuery suit également certaines statistiques sur les requêtes, telles que l'heure de création, l'heure de fin et le nombre total d'octets traités.
Dans cette étape, vous allez désactiver la mise en cache et afficher des statistiques sur les requêtes.
Accédez au fichier queryShakespeare.js dans le dossier BigQueryDemo et remplacez le code par ce qui suit :
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Quelques points à noter concernant le code : Tout d'abord, la mise en cache est désactivée en définissant UseQueryCache sur false dans l'objet options. Ensuite, vous avez accédé aux statistiques sur la requête à partir de l'objet Job.
Retournez dans Cloud Shell et exécutez l'application :
node queryShakespeare.js
Une liste des messages de commit et de leurs occurrences devrait s'afficher. Vous devriez également voir des statistiques sur la requête :
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Charger des données dans BigQuery
Si vous souhaitez interroger vos propres données, vous devez d'abord les charger dans BigQuery. BigQuery est compatible avec le chargement de données à partir de nombreuses sources, telles que Google Cloud Storage, d'autres services Google ou une source locale accessible en lecture. Vous pouvez même diffuser vos données. Pour en savoir plus, consultez la page Charger des données dans BigQuery.
Au cours de cette étape, vous allez charger un fichier JSON stocké dans Google Cloud Storage dans une table BigQuery. Le fichier JSON se trouve à l'emplacement suivant : gs://cloud-samples-data/bigquery/us-states/us-states.json
Si vous souhaitez en savoir plus sur le contenu du fichier JSON, vous pouvez utiliser l'outil de ligne de commande gsutil pour le télécharger dans Cloud Shell :
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Vous pouvez voir qu'il contient la liste des États américains, et que chaque État est un objet JSON sur une ligne distincte :
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Pour charger ce fichier JSON dans BigQuery, créez un fichier createDataset.js et un fichier loadBigQueryJSON.js dans le dossier BigQueryDemo :
touch createDataset.js
touch loadBigQueryJSON.js
Installez la bibliothèque cliente Google Cloud Storage Node.js :
npm install --save @google-cloud/storage
Accédez au fichier createDataset.js et insérez le code suivant :
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Accédez ensuite au fichier loadBigQueryJSON.js et insérez le code suivant :
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Prenez quelques minutes pour étudier comment le code charge le fichier JSON et crée une table (avec un schéma) dans un ensemble de données.
Retournez dans Cloud Shell et exécutez l'application :
node createDataset.js
node loadBigQueryJSON.js
Un ensemble de données et une table sont créés dans BigQuery :
Table my_states_table created.
Job [JOB ID] completed.
Pour vérifier que l'ensemble de données a été créé, vous pouvez accéder à l'UI Web de BigQuery. Vous devriez voir un nouvel ensemble de données et un tableau. Si vous passez à l'onglet "Aperçu" de la table, vous pouvez voir les données réelles :

11. Félicitations !
Vous avez appris à utiliser BigQuery avec Node.js.
Effectuer un nettoyage
Afin d'éviter que des frais ne soient facturés sur votre compte Google Cloud Platform pour les ressources utilisées dans ce démarrage rapide, procédez comme suit :
- Accédez à la console Cloud Platform.
- Sélectionnez le projet que vous souhaitez arrêter, puis cliquez sur "Supprimer" en haut de la page. Le projet sera alors programmé pour suppression.
En savoir plus
- Google BigQuery : https://cloud.google.com/bigquery/docs/
- Node.js sur Google Cloud Platform : https://cloud.google.com/nodejs/
- Bibliothèque cliente Node.js Google BigQuery : https://github.com/googleapis/nodejs-bigquery
Licence
Ce document est publié sous une licence Creative Commons Attribution 2.0 Generic.