
১. সংক্ষিপ্ত বিবরণ
BigQuery হলো গুগলের সম্পূর্ণভাবে পরিচালিত, পেটাবাইট স্কেলের, স্বল্প খরচের অ্যানালিটিক্স ডেটা ওয়্যারহাউস। BigQuery হলো NoOps—এর জন্য কোনো পরিকাঠামো পরিচালনা করতে হয় না এবং আপনার কোনো ডেটাবেস অ্যাডমিনিস্ট্রেটরেরও প্রয়োজন নেই—ফলে আপনি অর্থপূর্ণ অন্তর্দৃষ্টি খুঁজে বের করার জন্য ডেটা বিশ্লেষণে মনোযোগ দিতে পারেন, পরিচিত SQL ব্যবহার করতে পারেন এবং আমাদের পে-অ্যাজ-ইউ-গো মডেলের সুবিধা নিতে পারেন।
এই কোডল্যাবে, আপনি Node.js ব্যবহার করে Google Cloud BigQuery ক্লায়েন্ট লাইব্রেরির সাহায্যে BigQuery পাবলিক ডেটাসেটগুলোতে কোয়েরি করবেন।
আপনি যা শিখবেন
- ক্লাউড শেল কীভাবে ব্যবহার করবেন
- BigQuery API কীভাবে সক্রিয় করবেন
- এপিআই অনুরোধগুলি কীভাবে প্রমাণীকরণ করবেন
- Node.js-এর জন্য BigQuery ক্লায়েন্ট লাইব্রেরি কীভাবে ইনস্টল করবেন
- শেক্সপিয়রের রচনা সম্পর্কে কীভাবে অনুসন্ধান করবেন
- গিটহাব ডেটাসেট কীভাবে কোয়েরি করবেন
- ক্যাশিং কীভাবে সামঞ্জস্য করবেন এবং পরিসংখ্যান প্রদর্শন করবেন
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড প্ল্যাটফর্ম প্রকল্প
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স
- Node.js ব্যবহারে পরিচিতি
জরিপ
আপনি এই টিউটোরিয়ালটি কীভাবে ব্যবহার করবেন?
Node.js নিয়ে আপনার অভিজ্ঞতাকে আপনি কীভাবে মূল্যায়ন করবেন?
গুগল ক্লাউড প্ল্যাটফর্ম পরিষেবা ব্যবহারের অভিজ্ঞতাকে আপনি কীভাবে মূল্যায়ন করবেন?
২. সেটআপ এবং প্রয়োজনীয়তা
স্ব-গতিতে পরিবেশ সেটআপ
- ক্লাউড কনসোলে সাইন ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। (যদি আপনার আগে থেকে Gmail বা G Suite অ্যাকাউন্ট না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে।)


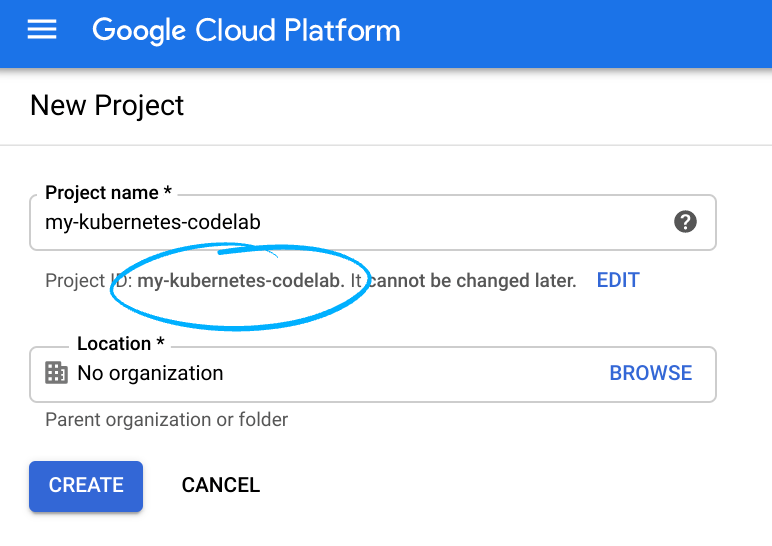
প্রজেক্ট আইডিটি মনে রাখবেন, যা সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে একটি অনন্য নাম (উপরের নামটি ইতিমধ্যে ব্যবহৃত হয়েছে এবং আপনার জন্য কাজ করবে না, দুঃখিত!)। এই কোডল্যাবে এটিকে পরবর্তীতে PROJECT_ID হিসাবে উল্লেখ করা হবে।
- এরপরে, গুগল ক্লাউড রিসোর্স ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং চালু করতে হবে।
এই কোডল্যাবটি চালাতে খুব বেশি খরচ হওয়ার কথা নয়, এমনকি আদৌ কোনো খরচ নাও হতে পারে। "পরিষ্কার-পরিচ্ছন্নতা" (Cleaning up) বিভাগে দেওয়া নির্দেশাবলী অবশ্যই অনুসরণ করবেন, যেখানে রিসোর্স বন্ধ করার পরামর্শ দেওয়া হয়েছে, যাতে এই টিউটোরিয়ালের বাইরে আপনার কোনো বিল না আসে। গুগল ক্লাউডের নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়াল প্রোগ্রামের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
যদিও ক্লাউড এসডিকে কমান্ড-লাইন টুলটি আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
ক্লাউড শেল সক্রিয় করুন
- ক্লাউড কনসোল থেকে, Activate Cloud Shell-এ ক্লিক করুন।
.

আপনি যদি আগে কখনো ক্লাউড শেল চালু না করে থাকেন, তাহলে এটি কী তা বর্ণনা করে একটি মধ্যবর্তী স্ক্রিন (নিচে দেওয়া আছে) আপনার সামনে আসবে। যদি তাই হয়, তাহলে 'Continue'-তে ক্লিক করুন (এবং আপনি এটি আর কখনো দেখতে পাবেন না)। একবারের জন্য আসা সেই স্ক্রিনটি দেখতে এইরকম:

ক্লাউড শেল প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত।

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার প্রায় সমস্ত কাজই শুধুমাত্র একটি ব্রাউজার বা আপনার ক্রোমবুক দিয়ে করা সম্ভব।
ক্লাউড শেলে সংযুক্ত হওয়ার পর আপনি দেখতে পাবেন যে, আপনাকে ইতিমধ্যেই প্রমাণীকৃত করা হয়েছে এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে।
- আপনি প্রমাণীকৃত কিনা তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
gcloud auth list
কমান্ড আউটপুট
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
কমান্ড আউটপুট
[core] project = <PROJECT_ID>
যদি তা না থাকে, তবে আপনি এই কমান্ডটি দিয়ে এটি সেট করতে পারেন:
gcloud config set project <PROJECT_ID>
কমান্ড আউটপুট
Updated property [core/project].
৩. BigQuery API সক্রিয় করুন
সকল গুগল ক্লাউড প্রজেক্টে BigQuery API ডিফল্টরূপে সক্রিয় থাকার কথা। ক্লাউড শেলে নিম্নলিখিত কমান্ডটি ব্যবহার করে আপনি এটি যাচাই করতে পারেন:
gcloud services list
আপনি BigQuery তালিকাভুক্ত দেখতে পাবেন:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
যদি BigQuery API সক্রিয় করা না থাকে, তাহলে আপনি ক্লাউড শেলে নিম্নলিখিত কমান্ডটি ব্যবহার করে এটি সক্রিয় করতে পারেন:
gcloud services enable bigquery-json.googleapis.com
৪. এপিআই অনুরোধ প্রমাণীকরণ করুন
BigQuery API-তে রিকোয়েস্ট পাঠানোর জন্য, আপনাকে একটি সার্ভিস অ্যাকাউন্ট ব্যবহার করতে হবে। একটি সার্ভিস অ্যাকাউন্ট আপনার প্রোজেক্টের অন্তর্গত, এবং এটি Google BigQuery Node.js ক্লায়েন্ট লাইব্রেরি দ্বারা BigQuery API-তে রিকোয়েস্ট পাঠানোর জন্য ব্যবহৃত হয়। অন্য যেকোনো ইউজার অ্যাকাউন্টের মতোই, একটি সার্ভিস অ্যাকাউন্ট একটি ইমেল অ্যাড্রেস দ্বারা চিহ্নিত করা হয়। এই অংশে, আপনি ক্লাউড SDK ব্যবহার করে একটি সার্ভিস অ্যাকাউন্ট তৈরি করবেন এবং তারপর সেই সার্ভিস অ্যাকাউন্ট হিসেবে অথেন্টিকেট করার জন্য প্রয়োজনীয় ক্রেডেনশিয়াল তৈরি করবেন।
প্রথমে, আপনার PROJECT_ID দিয়ে একটি এনভায়রনমেন্ট ভেরিয়েবল সেট করুন, যা আপনি এই কোডল্যাব জুড়ে ব্যবহার করবেন:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
এরপরে, BigQuery API অ্যাক্সেস করার জন্য নিম্নলিখিত পদ্ধতি ব্যবহার করে একটি নতুন সার্ভিস অ্যাকাউন্ট তৈরি করুন:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
এরপরে, এমন ক্রেডেনশিয়াল তৈরি করুন যা আপনার Node.js কোড নতুন সার্ভিস অ্যাকাউন্ট হিসেবে লগইন করতে ব্যবহার করবে। নিম্নলিখিত কমান্ডটি ব্যবহার করে এই ক্রেডেনশিয়ালগুলো তৈরি করুন এবং " ~/key.json " নামে একটি JSON ফাইল হিসেবে সংরক্ষণ করুন:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
অবশেষে, GOOGLE_APPLICATION_CREDENTIALS এনভায়রনমেন্ট ভেরিয়েবলটি সেট করুন, যা আপনার ক্রেডেনশিয়াল খুঁজে পেতে পরবর্তী ধাপে আলোচিত BigQuery API C# লাইব্রেরি দ্বারা ব্যবহৃত হয়। এনভায়রনমেন্ট ভেরিয়েবলটি আপনার তৈরি করা ক্রেডেনশিয়াল JSON ফাইলের সম্পূর্ণ পাথে সেট করতে হবে। নিম্নলিখিত কমান্ডটি ব্যবহার করে এনভায়রনমেন্ট ভেরিয়েবলটি সেট করুন:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
BigQuery API-এর প্রমাণীকরণ সম্পর্কে আপনি আরও পড়তে পারেন।
৫. অ্যাক্সেস কন্ট্রোল সেটআপ করুন
BigQuery রিসোর্সগুলিতে অ্যাক্সেস পরিচালনা করার জন্য আইডেন্টিটি অ্যান্ড অ্যাক্সেস ম্যানেজমেন্ট (IAM) ব্যবহার করে। BigQuery-তে বেশ কিছু পূর্বনির্ধারিত রোল (যেমন user, dataOwner, dataViewer ইত্যাদি) রয়েছে, যেগুলো আপনি পূর্ববর্তী ধাপে তৈরি করা আপনার সার্ভিস অ্যাকাউন্টে অ্যাসাইন করতে পারেন। আপনি BigQuery ডকুমেন্টেশনে অ্যাক্সেস কন্ট্রোল সম্পর্কে আরও পড়তে পারেন।
পাবলিক ডেটাসেটগুলো কোয়েরি করার আগে, আপনাকে নিশ্চিত করতে হবে যে সার্ভিস অ্যাকাউন্টটির অন্তত bigquery.user রোলটি আছে। ক্লাউড শেলে, সার্ভিস অ্যাকাউন্টটিতে bigquery.user রোলটি অ্যাসাইন করার জন্য নিম্নলিখিত কমান্ডটি চালান:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
সার্ভিস অ্যাকাউন্টটিকে ইউজার রোল বরাদ্দ করা হয়েছে কিনা তা যাচাই করতে আপনি নিম্নলিখিত কমান্ডটি চালাতে পারেন:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
৬. Node.js-এর জন্য BigQuery ক্লায়েন্ট লাইব্রেরি ইনস্টল করুন।
প্রথমে, একটি BigQueryDemo ফোল্ডার তৈরি করুন এবং সেখানে যান:
mkdir BigQueryDemo
cd BigQueryDemo
এরপরে, একটি Node.js প্রজেক্ট তৈরি করুন যা আপনি BigQuery ক্লায়েন্ট লাইব্রেরির স্যাম্পলগুলো চালানোর জন্য ব্যবহার করবেন:
npm init -y
আপনি তৈরি হওয়া Node.js প্রজেক্টটি দেখতে পাবেন:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
BigQuery ক্লায়েন্ট লাইব্রেরি ইনস্টল করুন:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
এখন আপনি BigQuery Node.js ক্লায়েন্ট লাইব্রেরি ব্যবহার করার জন্য প্রস্তুত!
৭. শেক্সপিয়রের রচনাবলী সম্পর্কে অনুসন্ধান করুন।
পাবলিক ডেটাসেট হলো এমন যেকোনো ডেটাসেট যা BigQuery-তে সংরক্ষিত থাকে এবং সাধারণ মানুষের জন্য উপলব্ধ করা হয়। আপনার কোয়েরি করার জন্য আরও অনেক পাবলিক ডেটাসেট রয়েছে, যার মধ্যে কয়েকটি গুগল দ্বারা হোস্ট করা হয়, তবে আরও অনেক ডেটাসেট তৃতীয় পক্ষ দ্বারা হোস্ট করা হয়। আপনি পাবলিক ডেটাসেট পেজে এ বিষয়ে আরও পড়তে পারেন।
পাবলিক ডেটাসেটগুলো ছাড়াও, BigQuery সীমিত সংখ্যক স্যাম্পল টেবিল সরবরাহ করে যেগুলো আপনি কোয়েরি করতে পারেন। এই টেবিলগুলো bigquery-public-data:samples dataset অন্তর্ভুক্ত। সেই টেবিলগুলোর মধ্যে একটির নাম হলো shakespeare. এতে শেক্সপিয়রের রচনার একটি শব্দ সূচক রয়েছে, যা প্রতিটি কর্পাসে প্রতিটি শব্দ কতবার এসেছে তা দেখায়।
এই ধাপে, আপনি শেক্সপিয়ার টেবিলটি কোয়েরি করবেন।
প্রথমে, ক্লাউড শেলের উপরের ডান দিক থেকে কোড এডিটরটি খুলুন:
BigQueryDemo ফোল্ডারের ভিতরে একটি queryShakespeare.js ফাইল তৈরি করুন:
touch queryShakespeare.js
queryShakespeare.js ফাইলটিতে যান এবং নিম্নলিখিত কোডটি সন্নিবেশ করুন:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
এক বা দুই মিনিট সময় নিয়ে কোডটি দেখুন এবং খেয়াল করুন কীভাবে টেবিলটি কোয়েরি করা হয়েছে।
ক্লাউড শেলে ফিরে এসে অ্যাপটি চালান:
node queryShakespeare.js
আপনি শব্দ এবং সেগুলোর ব্যবহারের একটি তালিকা দেখতে পাবেন:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
৮. গিটহাব ডেটাসেটটি কোয়েরি করুন।
BigQuery-এর সাথে আরও পরিচিত হওয়ার জন্য, আপনি এখন GitHub পাবলিক ডেটাসেটের বিরুদ্ধে একটি কোয়েরি চালাবেন। আপনি GitHub-এ সবচেয়ে সাধারণ কমিট মেসেজগুলো খুঁজে পাবেন। এছাড়াও, আপনি BigQuery-এর ওয়েব UI ব্যবহার করে অ্যাড-হক কোয়েরিগুলোর প্রিভিউ দেখবেন এবং চালাবেন।
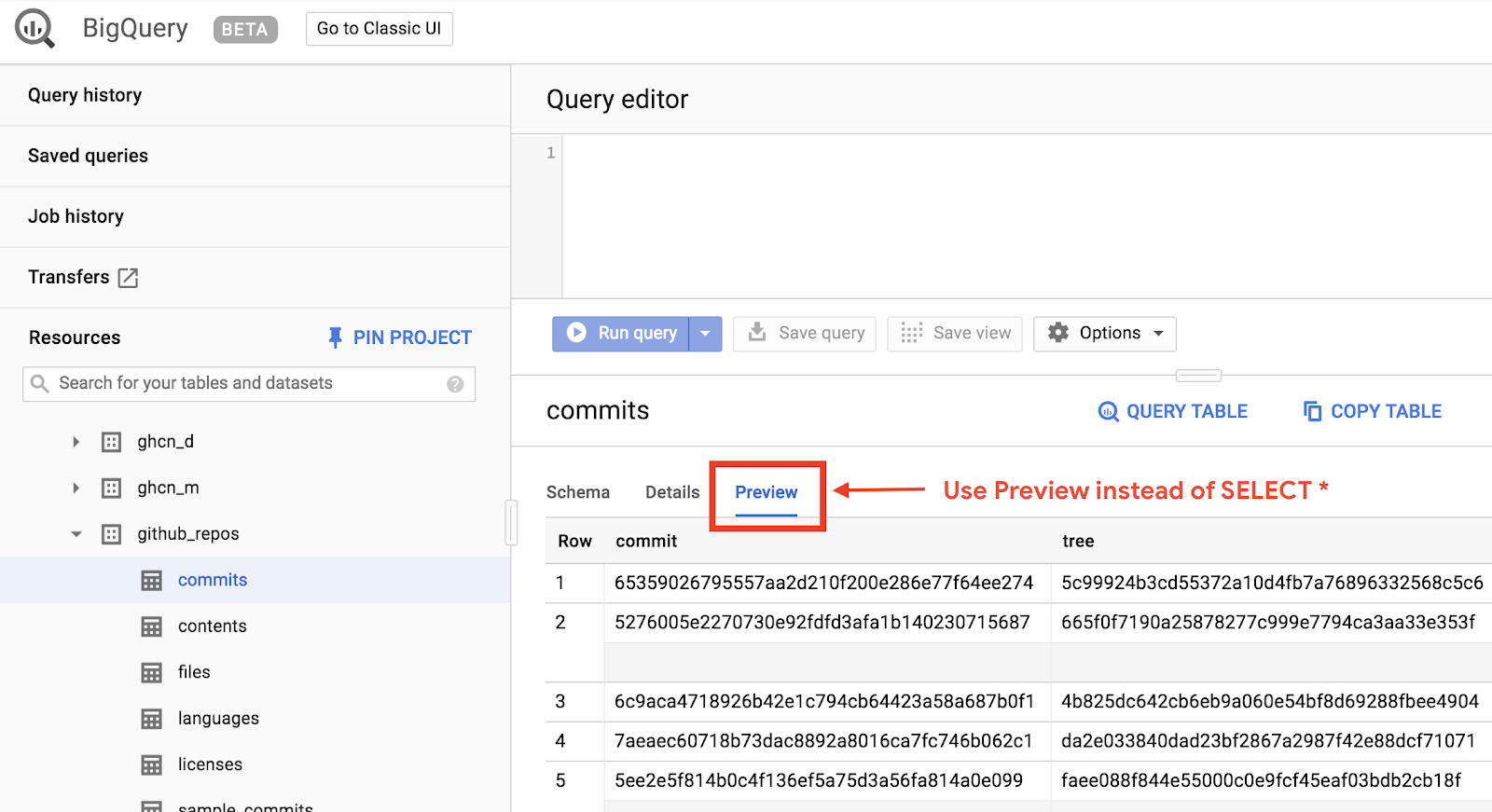
ডেটা দেখতে, BigQuery ওয়েব UI-তে GitHub ডেটাসেটটি খুলুন:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
ডেটা দেখতে কেমন তা দ্রুত দেখে নিতে, প্রিভিউ ট্যাবে ক্লিক করুন:
BigQueryDemo ফোল্ডারের ভিতরে queryGitHub.js ফাইলটি তৈরি করুন:
touch queryGitHub.js
queryGitHub.js ফাইলটিতে যান এবং নিম্নলিখিত কোডটি সন্নিবেশ করুন:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
এক বা দুই মিনিট সময় নিয়ে কোডটি দেখুন এবং খেয়াল করুন কীভাবে সবচেয়ে সাধারণ কমিট মেসেজগুলোর জন্য টেবিলটি কোয়েরি করা হয়।
ক্লাউড শেলে ফিরে এসে অ্যাপটি চালান:
node queryGitHub.js
আপনি কমিট বার্তা এবং সেগুলোর উপস্থিতির একটি তালিকা দেখতে পাবেন:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
৯. ক্যাশিং এবং পরিসংখ্যান
আপনি যখন কোনো কোয়েরি চালান, BigQuery ফলাফলগুলো ক্যাশ করে রাখে। এর ফলে, পরবর্তী একই ধরনের কোয়েরিগুলো চালাতে অনেক কম সময় লাগে। কোয়েরি অপশন ব্যবহার করে ক্যাশিং নিষ্ক্রিয় করা সম্ভব। BigQuery এছাড়াও কোয়েরিগুলো সম্পর্কে কিছু পরিসংখ্যানের হিসাব রাখে, যেমন তৈরির সময়, শেষের সময় এবং মোট প্রক্রিয়াকৃত বাইট।
এই ধাপে, আপনি ক্যাশিং নিষ্ক্রিয় করবেন এবং কোয়েরিগুলো সম্পর্কে কিছু পরিসংখ্যান প্রদর্শন করবেন।
BigQueryDemo ফোল্ডারের ভিতরে থাকা queryShakespeare.js ফাইলটিতে যান এবং কোডটি নিম্নলিখিত কোড দিয়ে প্রতিস্থাপন করুন:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
কোডটি সম্পর্কে কয়েকটি বিষয় লক্ষণীয়। প্রথমত, options অবজেক্টের ভিতরে UseQueryCache কে false সেট করার মাধ্যমে ক্যাশিং নিষ্ক্রিয় করা হয়েছে। দ্বিতীয়ত, আপনি job অবজেক্ট থেকে কোয়েরিটির পরিসংখ্যান অ্যাক্সেস করেছেন।
ক্লাউড শেলে ফিরে এসে অ্যাপটি চালান:
node queryShakespeare.js
আপনি কমিট মেসেজ এবং সেগুলোর উপস্থিতির একটি তালিকা দেখতে পাবেন। এছাড়াও, আপনি কোয়েরিটি সম্পর্কে কিছু পরিসংখ্যানও দেখতে পাবেন:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
১০. BigQuery-তে ডেটা লোড করা
আপনি যদি আপনার নিজের ডেটা কোয়েরি করতে চান, তাহলে আপনাকে প্রথমে BigQuery-তে আপনার ডেটা লোড করতে হবে। BigQuery গুগল ক্লাউড স্টোরেজ, অন্যান্য গুগল পরিষেবা বা একটি স্থানীয়, পাঠযোগ্য উৎসের মতো অনেক উৎস থেকে ডেটা লোড করা সমর্থন করে। এমনকি আপনি আপনার ডেটা স্ট্রিমও করতে পারেন। আপনি "BigQuery-তে ডেটা লোড করা" পৃষ্ঠায় এ বিষয়ে আরও পড়তে পারেন।
এই ধাপে, আপনি গুগল ক্লাউড স্টোরেজে সংরক্ষিত একটি JSON ফাইল BigQuery টেবিলে লোড করবেন। JSON ফাইলটি এই ঠিকানায় অবস্থিত: gs://cloud-samples-data/bigquery/us-states/us-states.json
আপনি যদি JSON ফাইলের বিষয়বস্তু সম্পর্কে জানতে আগ্রহী হন, তাহলে gsutil কমান্ড লাইন টুল ব্যবহার করে ক্লাউড শেলে এটি ডাউনলোড করতে পারেন:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
আপনি দেখতে পাচ্ছেন যে এতে মার্কিন যুক্তরাষ্ট্রের রাজ্যগুলির তালিকা রয়েছে এবং প্রতিটি রাজ্য একটি আলাদা লাইনে একটি JSON অবজেক্ট হিসাবে আছে:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
এই JSON ফাইলটি BigQuery-তে লোড করার জন্য, BigQueryDemo ফোল্ডারের ভিতরে একটি createDataset.js ফাইল এবং একটি loadBigQueryJSON.js ফাইল তৈরি করুন:
touch createDataset.js
touch loadBigQueryJSON.js
গুগল ক্লাউড স্টোরেজ নোড.জেএস ক্লায়েন্ট লাইব্রেরি ইনস্টল করুন:
npm install --save @google-cloud/storage
createDataset.js ফাইলটিতে যান এবং নিম্নলিখিত কোডটি সন্নিবেশ করুন:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
এরপর, loadBigQueryJSON.js ফাইলটিতে যান এবং নিম্নলিখিত কোডটি সন্নিবেশ করুন:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
কোডটি কীভাবে JSON ফাইল লোড করে এবং একটি ডেটাসেটে (স্কিমা সহ) একটি টেবিল তৈরি করে, তা মনোযোগ দিয়ে দেখতে এক বা দুই মিনিট সময় নিন।
ক্লাউড শেলে ফিরে এসে অ্যাপটি চালান:
node createDataset.js
node loadBigQueryJSON.js
BigQuery-তে একটি ডেটাসেট এবং একটি টেবিল তৈরি করা হয়:
Table my_states_table created.
Job [JOB ID] completed.
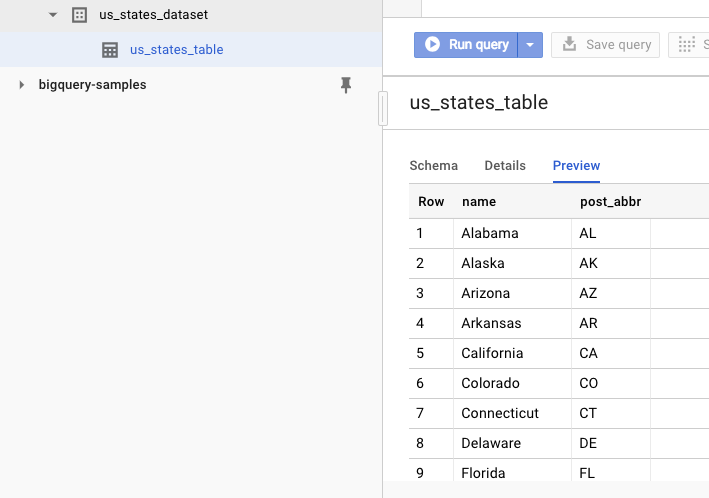
ডেটা সেট তৈরি হয়েছে কিনা তা যাচাই করতে, আপনি BigQuery ওয়েব UI-তে যেতে পারেন। সেখানে আপনি একটি নতুন ডেটা সেট এবং একটি টেবিল দেখতে পাবেন। টেবিলটির প্রিভিউ ট্যাবে গেলে আপনি আসল ডেটা দেখতে পাবেন:
১১. অভিনন্দন!
আপনি Node.js ব্যবহার করে BigQuery ব্যবহার করতে শিখেছেন!
পরিষ্কার করা
এই কুইকস্টার্টে ব্যবহৃত রিসোর্সগুলির জন্য আপনার গুগল ক্লাউড প্ল্যাটফর্ম অ্যাকাউন্টে চার্জ হওয়া এড়াতে:
- ক্লাউড প্ল্যাটফর্ম কনসোলে যান।
- যে প্রজেক্টটি বন্ধ করতে চান, সেটি নির্বাচন করুন, তারপর উপরে থাকা 'ডিলিট' বোতামে ক্লিক করুন: এটি প্রজেক্টটিকে মুছে ফেলার জন্য নির্ধারিত করবে।
আরও জানুন
- গুগল বিগকোয়েরি: https://cloud.google.com/bigquery/docs/
- গুগল ক্লাউড প্ল্যাটফর্মে নোড.জেএস: https://cloud.google.com/nodejs/
- গুগল বিগকোয়েরি নোড.জেএস ক্লায়েন্ট লাইব্রেরি: https://github.com/googleapis/nodejs-bigquery
লাইসেন্স
এই কাজটি ক্রিয়েটিভ কমন্স অ্যাট্রিবিউশন ২.০ জেনেরিক লাইসেন্সের অধীনে রয়েছে।