
1. Przegląd
BigQuery to w pełni zarządzana, ekonomiczna hurtownia danych analitycznych Google w skali petabajtowej. BigQuery to usługa typu NoOps – nie musisz zarządzać infrastrukturą ani zatrudniać administratora bazy danych, więc możesz skupić się na analizowaniu danych w celu uzyskania przydatnych informacji, korzystać ze znanego Ci języka SQL i wykorzystywać nasz model płatności według wykorzystania.
W tym module dowiesz się, jak używać biblioteki klienta Google Cloud BigQuery do wykonywania zapytań w publicznych zbiorach danych BigQuery za pomocą Node.js.
Czego się nauczysz
- Jak korzystać z Cloud Shell
- Włączanie interfejsu BigQuery API
- Uwierzytelnianie żądań do interfejsu API
- Instalowanie biblioteki klienta BigQuery w Node.js
- Jak wyszukiwać dzieła Szekspira
- Jak wysyłać zapytania do zbioru danych GitHub
- Jak dostosować statystyki buforowania i wyświetlania
Czego potrzebujesz
Ankieta
Jak zamierzasz korzystać z tego samouczka?
Jak oceniasz swoje doświadczenie z Node.js?
Jak oceniasz korzystanie z usług Google Cloud Platform?
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. (Jeśli nie masz jeszcze konta Gmail lub G Suite, musisz je utworzyć).


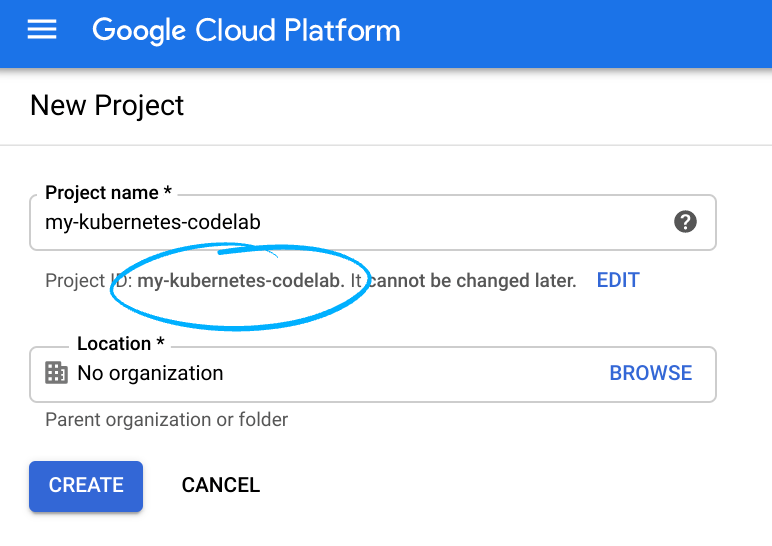
Zapamiętaj identyfikator projektu, czyli unikalną nazwę we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
- Następnie musisz włączyć rozliczenia w konsoli Cloud, aby korzystać z zasobów Google Cloud.
Ukończenie tego laboratorium nie powinno wiązać się z dużymi kosztami, a nawet z żadnymi. Wykonaj instrukcje z sekcji „Czyszczenie”, w której znajdziesz informacje o tym, jak wyłączyć zasoby, aby uniknąć naliczenia opłat po zakończeniu tego samouczka. Nowi użytkownicy Google Cloud mogą skorzystać z programu bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Narzędzie wiersza poleceń Cloud SDK może być obsługiwane zdalnie z laptopa, ale w tym module użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
Aktywowanie Cloud Shell
- W konsoli Cloud kliknij Aktywuj Cloud Shell
.

Jeśli uruchamiasz Cloud Shell po raz pierwszy, zobaczysz ekran pośredni (część strony widoczna po przewinięciu) z opisem tego środowiska. W takim przypadku kliknij Dalej, a ten ekran nie będzie się już wyświetlać. Ten wyświetlany jednorazowo ekran wygląda tak:

Uzyskanie dostępu do środowiska Cloud Shell i połączenie się z nim powinno zająć tylko kilka chwil.

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Większość zadań w tym module, a być może wszystkie, możesz wykonać w przeglądarce lub na Chromebooku.
Po połączeniu z Cloud Shell zobaczysz, że uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu.
- Aby potwierdzić, że uwierzytelnianie zostało przeprowadzone, uruchom w Cloud Shell to polecenie:
gcloud auth list
Wynik polecenia
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Wynik polecenia
[core] project = <PROJECT_ID>
Jeśli nie, możesz go ustawić za pomocą tego polecenia:
gcloud config set project <PROJECT_ID>
Wynik polecenia
Updated property [core/project].
3. Włączanie interfejsu BigQuery API
Interfejs BigQuery API powinien być domyślnie włączony we wszystkich projektach Google Cloud. Możesz to sprawdzić za pomocą tego polecenia w Cloud Shell:
gcloud services list
Powinna się wyświetlić lista BigQuery:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
Jeśli interfejs BigQuery API nie jest włączony, możesz go włączyć za pomocą tego polecenia w Cloud Shell:
gcloud services enable bigquery-json.googleapis.com
4. Uwierzytelnianie żądań do interfejsu API
Aby wysyłać żądania do interfejsu BigQuery API, musisz użyć konta usługi. Konto usługi należy do Twojego projektu i jest używane przez bibliotekę klienta Google BigQuery w Node.js do wysyłania żądań do interfejsu BigQuery API. Podobnie jak każde inne konto użytkownika, konto usługi jest reprezentowane przez adres e-mail. W tej sekcji użyjesz pakietu SDK Cloud, aby utworzyć konto usługi, a następnie utworzysz dane logowania, które będą potrzebne do uwierzytelnienia się jako konto usługi.
Najpierw ustaw zmienną środowiskową wykorzystującą Twój PROJECT_ID (IDENTYFIKATOR_PROJEKTU), której będziesz używać podczas naszych ćwiczeń z programowania:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Następnie utwórz nowe konto usługi, aby uzyskać dostęp do interfejsu BigQuery API, używając:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Następnie utwórz dane logowania, których kod Node.js będzie używać do logowania się na nowe konto usługi. Utworzone dane zapisz w pliku JSON „~/key.json” przy użyciu następującego polecenia:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Na koniec ustaw zmienną środowiskową GOOGLE_APPLICATION_CREDENTIALS, która jest używana przez bibliotekę C# interfejsu BigQuery API (omówioną w następnym kroku) do znajdowania Twoich danych logowania. Zmienna środowiskowa powinna zawierać pełną ścieżkę do utworzonego przez Ciebie pliku JSON z danymi logowania. Ustaw zmienną środowiskową za pomocą tego polecenia:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
Więcej informacji o uwierzytelnianiu BigQuery API
5. Konfigurowanie kontroli dostępu
BigQuery używa usługi Identity and Access Management (IAM) do zarządzania dostępem do zasobów. BigQuery ma kilka predefiniowanych ról (użytkownik, właściciel danych, przeglądający dane itp.), które możesz przypisać do konta usługi utworzonego w poprzednim kroku. Więcej informacji o kontroli dostępu znajdziesz w dokumentacji BigQuery.
Zanim zaczniesz wysyłać zapytania do publicznych zbiorów danych, musisz się upewnić, że konto usługi ma co najmniej rolę bigquery.user. Aby przypisać rolę bigquery.user do konta usługi, uruchom w Cloud Shell to polecenie:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Aby sprawdzić, czy do konta usługi przypisana jest rola użytkownika, możesz uruchomić to polecenie:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Instalowanie biblioteki klienta BigQuery w Node.js
Najpierw utwórz folder BigQueryDemo i przejdź do niego:
mkdir BigQueryDemo
cd BigQueryDemo
Następnie utwórz projekt Node.js, którego będziesz używać do uruchamiania przykładowych bibliotek klienta BigQuery:
npm init -y
Powinien wyświetlić się utworzony projekt Node.js:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Zainstaluj bibliotekę klienta BigQuery:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Możesz już korzystać z biblioteki klienta BigQuery w Node.js.
7. Wyszukiwanie w dziełach Szekspira
Publiczny zbiór danych to dowolny zbiór danych przechowywany w BigQuery i udostępniany ogółowi użytkowników. Możesz wysyłać zapytania do wielu innych publicznych zbiorów danych, z których część jest hostowana przez Google, a większość przez inne firmy. Więcej informacji znajdziesz na stronie Publiczne zbiory danych.
Oprócz publicznych zbiorów danych BigQuery udostępnia ograniczoną liczbę przykładowych tabel, do których możesz wysyłać zapytania. Tabele te znajdują się w bigquery-public-data:samples dataset. Jedna z tych tabel nosi nazwę shakespeare.. Zawiera ona indeks słów z dzieł Szekspira, podając liczbę wystąpień każdego słowa w poszczególnych korpusach.
W tym kroku wyślesz zapytanie do tabeli shakespeare.
Najpierw otwórz edytor kodu w prawym górnym rogu Cloud Shell:

Utwórz plik queryShakespeare.js w folderze BigQueryDemo :
touch queryShakespeare.js
Otwórz plik queryShakespeare.js i wstaw ten kod:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Poświęć minutę lub dwie na przeanalizowanie kodu i sprawdzenie, jak wysyłane są zapytania do tabeli.
Wróć do Cloud Shell i uruchom aplikację:
node queryShakespeare.js
Powinna się wyświetlić lista słów i ich wystąpień:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. Tworzenie zapytania dotyczącego zbioru danych GitHub
Aby lepiej poznać BigQuery, wykonasz teraz zapytanie dotyczące publicznego zbioru danych GitHub. Najczęstsze komunikaty zatwierdzenia znajdziesz na GitHubie. Użyjesz też interfejsu internetowego BigQuery, aby wyświetlać podgląd zapytań doraźnych i je uruchamiać.
Aby wyświetlić dane, otwórz zbiór danych GitHub w interfejsie internetowym BigQuery:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Aby szybko sprawdzić, jak wyglądają dane, kliknij kartę Podgląd:

Utwórz plik queryGitHub.js w folderze BigQueryDemo:
touch queryGitHub.js
Otwórz plik queryGitHub.js i wstaw ten kod:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Poświęć chwilę na przeanalizowanie kodu i sprawdź, jak w tabeli wyszukiwane są najczęstsze komunikaty o zatwierdzeniu.
Wróć do Cloud Shell i uruchom aplikację:
node queryGitHub.js
Powinna pojawić się lista komunikatów o zatwierdzeniu i ich wystąpień:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Pamięć podręczna i statystyki
Gdy uruchamiasz zapytanie, BigQuery zapisuje wyniki w pamięci podręcznej. Dzięki temu kolejne identyczne zapytania zajmują znacznie mniej czasu. Buforowanie można wyłączyć za pomocą opcji zapytania. BigQuery śledzi też niektóre statystyki dotyczące zapytań, takie jak czas utworzenia, czas zakończenia i łączna liczba przetworzonych bajtów.
W tym kroku wyłączysz buforowanie i wyświetlisz statystyki dotyczące zapytań.
Otwórz plik queryShakespeare.js w folderze BigQueryDemo i zastąp kod tym kodem:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Kilka uwag na temat kodu. Najpierw wyłącz buforowanie, ustawiając wartość UseQueryCache na false wewnątrz obiektu options. Po drugie, statystyki zapytania zostały pobrane z obiektu zadania.
Wróć do Cloud Shell i uruchom aplikację:
node queryShakespeare.js
Powinna wyświetlić się lista komunikatów o zatwierdzeniu i ich wystąpień. Powinny też pojawić się statystyki dotyczące zapytania:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Wczytywanie danych do BigQuery
Jeśli chcesz wysyłać zapytania o własne dane, musisz najpierw wczytać je do BigQuery. BigQuery obsługuje wczytywanie danych z wielu źródeł, takich jak Google Cloud Storage, inne usługi Google lub lokalne źródło, z którego można odczytywać dane. Możesz nawet przesyłać strumieniowo swoje dane. Więcej informacji znajdziesz na stronie Wczytywanie danych do BigQuery.
W tym kroku załadujesz plik JSON przechowywany w Google Cloud Storage do tabeli BigQuery. Plik JSON znajduje się w lokalizacji: gs://cloud-samples-data/bigquery/us-states/us-states.json
Jeśli chcesz sprawdzić zawartość pliku JSON, możesz go pobrać w Cloud Shell za pomocą narzędzia wiersza poleceń gsutil:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Widzisz, że zawiera listę stanów USA, a każdy stan jest obiektem JSON w osobnym wierszu:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Aby wczytać ten plik JSON do BigQuery, utwórz plik createDataset.js i plik loadBigQueryJSON.js w folderze BigQueryDemo:
touch createDataset.js
touch loadBigQueryJSON.js
Zainstaluj bibliotekę klienta Google Cloud Storage w Node.js:
npm install --save @google-cloud/storage
Otwórz plik createDataset.js i wstaw ten kod:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Następnie otwórz plik loadBigQueryJSON.js i wstaw ten kod:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Poświęć chwilę na zapoznanie się z tym, jak kod wczytuje plik JSON i tworzy tabelę (ze schematem) w zbiorze danych.
Wróć do Cloud Shell i uruchom aplikację:
node createDataset.js
node loadBigQueryJSON.js
W BigQuery zostaną utworzone zbiór danych i tabela:
Table my_states_table created.
Job [JOB ID] completed.
Aby sprawdzić, czy zbiór danych został utworzony, możesz otworzyć interfejs internetowy BigQuery. Powinien pojawić się nowy zbiór danych i tabela. Jeśli przejdziesz na kartę Podgląd tabeli, zobaczysz rzeczywiste dane:

11. Gratulacje!
Wiesz już, jak korzystać z BigQuery za pomocą Node.js.
Czyszczenie danych
Oto kroki, które musisz wykonać, aby uniknąć obciążenia konta Google Cloud Platform opłatami za zasoby zużyte podczas krótkiego wprowadzenia:
- Otwórz konsolę Cloud Platform.
- Wybierz projekt, który chcesz zamknąć, a następnie kliknij „Usuń” u góry. Spowoduje to zaplanowanie usunięcia projektu.
Więcej informacji
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js w Google Cloud Platform: https://cloud.google.com/nodejs/
- Biblioteka klienta Google BigQuery Node.js: https://github.com/googleapis/nodejs-bigquery
Licencja
To zadanie jest licencjonowane na podstawie ogólnej licencji Creative Commons Attribution 2.0.