
1. Panoramica
BigQuery è il data warehouse di analisi di Google completamente gestito, a basso costo e con capacità di petabyte. BigQuery è NoOps, ovvero non esistono infrastrutture da gestire e non hai bisogno di un amministratore di database, per cui puoi concentrarti sull'analisi dei dati per trovare informazioni significative, utilizzare un ambiente SQL familiare e sfruttare i vantaggi offerti dal modello di pagamento a consumo.
In questo codelab utilizzerai la libreria client BigQuery di Google Cloud per eseguire query sui set di dati pubblici di BigQuery con Node.js.
Cosa imparerai a fare
- Come utilizzare Cloud Shell
- Come abilitare l'API BigQuery
- Come autenticare le richieste API
- Come installare la libreria client di BigQuery per Node.js
- Come eseguire query sulle opere di Shakespeare
- Come eseguire query sul set di dati GitHub
- Come regolare le statistiche di memorizzazione nella cache e visualizzazione
Che cosa ti serve
- Un progetto Google Cloud
- Un browser, ad esempio Chrome o Firefox
- Familiarità con l'utilizzo di Node.js
Sondaggio
Come utilizzerai questo tutorial?
Come valuteresti la tua esperienza con Node.js?
Come valuti la tua esperienza di utilizzo dei servizi Google Cloud Platform?
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai già un account Gmail o G Suite, devi crearne uno.


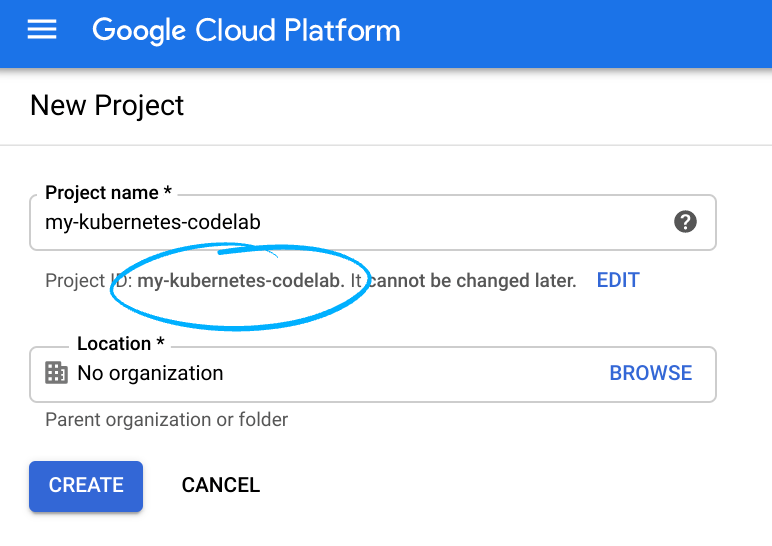
Ricorda l'ID progetto, un nome univoco tra tutti i progetti Google Cloud (il nome sopra è già stato utilizzato e non funzionerà per te, mi dispiace). In questo codelab verrà chiamato PROJECT_ID.
- Successivamente, dovrai abilitare la fatturazione in Cloud Console per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costare molto, se non nulla. Assicurati di seguire le istruzioni riportate nella sezione "Pulizia", che ti consiglia come arrestare le risorse in modo da non incorrere in addebiti oltre questo tutorial. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene lo strumento a riga di comando Cloud SDK possa essere utilizzato da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Attiva Cloud Shell
- Nella console Cloud, fai clic su Attiva Cloud Shell
.

Se non hai mai avviato Cloud Shell, viene visualizzata una schermata intermedia (sotto la piega) che ne descrive le funzionalità. In questo caso, fai clic su Continua e non comparirà più. Ecco come si presenta la schermata intermedia:

Bastano pochi istanti per eseguire il provisioning e connettersi a Cloud Shell.

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui hai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Gran parte del lavoro per questo codelab, se non tutto, può essere svolto semplicemente con un browser o con Chromebook.
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo ID progetto.
- Esegui questo comando in Cloud Shell per verificare che l'account sia autenticato:
gcloud auth list
Output comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
In caso contrario, puoi impostarlo con questo comando:
gcloud config set project <PROJECT_ID>
Output comando
Updated property [core/project].
3. Abilita l'API BigQuery
L'API BigQuery dovrebbe essere abilitata per impostazione predefinita in tutti i progetti Google Cloud. Puoi verificare se è vero con il seguente comando in Cloud Shell:
gcloud services list
Dovresti visualizzare BigQuery nell'elenco:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
Se l'API BigQuery non è abilitata, puoi utilizzare il seguente comando in Cloud Shell per abilitarla:
gcloud services enable bigquery-json.googleapis.com
4. Autenticare le richieste API
Per effettuare richieste all'API BigQuery, devi utilizzare un service account. Un service account appartiene al tuo progetto e viene utilizzato dalla libreria client Node.js di Google BigQuery per effettuare richieste all'API BigQuery. Come qualsiasi altro account utente, un service account è rappresentato da un indirizzo email. In questa sezione utilizzerai Cloud SDK per creare un service account e poi creare le credenziali necessarie per l'autenticazione come service account.
Innanzitutto, imposta una variabile di ambiente con il PROJECT_ID che utilizzerai durante questo codelab:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Successivamente, crea un nuovo service account per accedere all'API BigQuery utilizzando:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Successivamente, crea le credenziali che il codice Node.js utilizzerà per accedere al nuovo service account. Utilizza il seguente comando per creare le credenziali e salvarle in un file JSON denominato "~/key.json":
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Infine, imposta la variabile di ambiente GOOGLE_APPLICATION_CREDENTIALS, utilizzata dalla libreria C# dell'API BigQuery, trattata nel passaggio successivo, per trovare le tue credenziali. Il valore della variabile di ambiente deve essere il percorso completo del file JSON delle credenziali che hai creato. Imposta la variabile di ambiente utilizzando il seguente comando:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
Puoi scoprire di più sull'autenticazione dell'API BigQuery.
5. Configurare il controllo dell'accesso
BigQuery utilizza Identity and Access Management (IAM) per gestire l'accesso alle risorse. BigQuery dispone di una serie di ruoli predefiniti (utente, dataOwner, dataViewer e così via) che puoi assegnare al service account creato nel passaggio precedente. Per saperne di più sul controllo dell'accesso, consulta la documentazione di BigQuery.
Prima di poter eseguire query sui set di dati pubblici, devi assicurarti che il service account disponga almeno del ruolo bigquery.user. In Cloud Shell, esegui questo comando per assegnare il ruolo bigquery.user al service account:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Puoi eseguire questo comando per verificare che all'account di servizio sia assegnato il ruolo utente:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Installa la libreria client di BigQuery per Node.js
Innanzitutto, crea una cartella BigQueryDemo e vai al suo interno:
mkdir BigQueryDemo
cd BigQueryDemo
Successivamente, crea un progetto Node.js che utilizzerai per eseguire gli esempi della libreria client BigQuery:
npm init -y
Dovresti vedere il progetto Node.js creato:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
Installa la libreria client di BigQuery:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Ora puoi utilizzare la libreria client Node.js di BigQuery.
7. Esegui query sulle opere di Shakespeare
Un set di dati pubblico è un set di dati archiviato in BigQuery e reso disponibile al pubblico. Sono disponibili molti altri set di dati pubblici su cui eseguire query, alcuni dei quali sono ospitati anche da Google, ma molti altri da terze parti. Per saperne di più, consulta la pagina Set di dati pubblici.
Oltre ai set di dati pubblici, BigQuery fornisce un numero limitato di tabelle di esempio su cui puoi eseguire query. Queste tabelle sono contenute in bigquery-public-data:samples dataset. Una di queste tabelle si chiama shakespeare.. Contiene un indice delle parole delle opere di Shakespeare, che indica il numero di volte in cui ogni parola compare in ogni corpus.
In questo passaggio, eseguirai una query sulla tabella shakespeare.
Innanzitutto, apri l'editor di codice dalla parte in alto a destra di Cloud Shell:
Crea un file queryShakespeare.js all'interno della cartella BigQueryDemo :
touch queryShakespeare.js
Vai al file queryShakespeare.js e inserisci il seguente codice:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Prenditi un minuto o due per studiare il codice e vedere come viene eseguita la query sulla tabella.
Torna a Cloud Shell ed esegui l'app:
node queryShakespeare.js
Dovresti visualizzare un elenco di parole e delle relative occorrenze:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. Esegui una query sul set di dati GitHub
Per acquisire maggiore familiarità con BigQuery, ora eseguirai una query sul set di dati pubblico GitHub. I messaggi di commit più comuni sono disponibili su GitHub. Utilizzerai anche l'interfaccia utente web di BigQuery per visualizzare l 'anteprima ed eseguire query ad hoc.
Per visualizzare i dati, apri il set di dati GitHub nell'interfaccia utente web di BigQuery:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Per visualizzare un'anteprima rapida dell'aspetto dei dati, fai clic sulla scheda Anteprima:
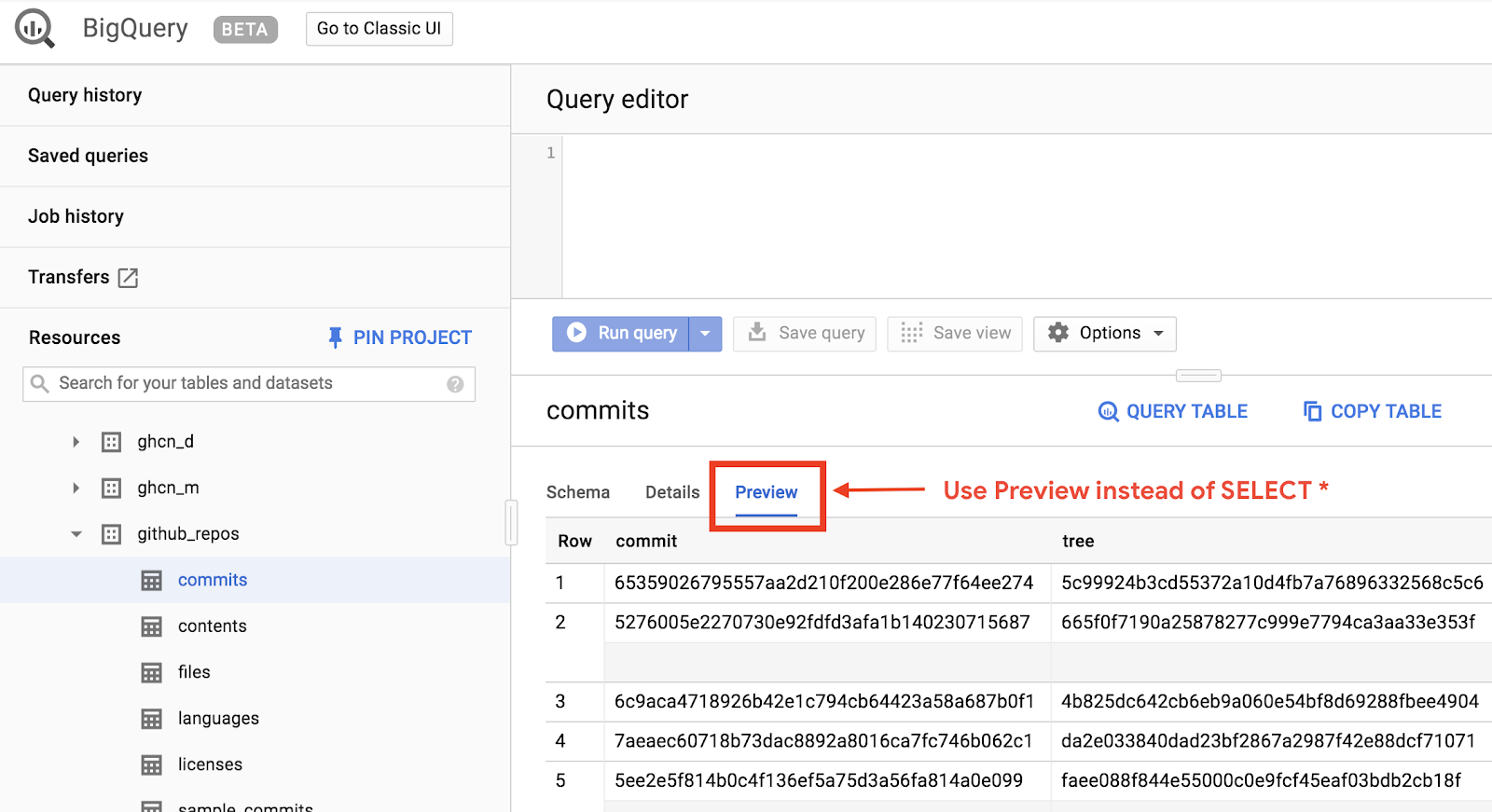
Crea il file queryGitHub.js all'interno della cartella BigQueryDemo:
touch queryGitHub.js
Vai al file queryGitHub.js e inserisci il seguente codice:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Dedica un minuto o due a studiare il codice e a vedere come viene eseguita la query sulla tabella per i messaggi di commit più comuni.
Torna a Cloud Shell ed esegui l'app:
node queryGitHub.js
Dovresti visualizzare un elenco dei messaggi di commit e delle relative occorrenze:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Memorizzazione nella cache e statistiche
Quando esegui una query, BigQuery memorizza nella cache i risultati. Di conseguenza, le query identiche successive richiedono molto meno tempo. È possibile disattivare la memorizzazione nella cache utilizzando le opzioni di query. BigQuery tiene traccia anche di alcune statistiche sulle query, come l'ora di creazione, l'ora di fine e il totale dei byte elaborati.
In questo passaggio, disattiverai la memorizzazione nella cache e visualizzerai alcune statistiche sulle query.
Vai al file queryShakespeare.js all'interno della cartella BigQueryDemo e sostituisci il codice con il seguente:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Ecco un paio di cose da notare sul codice. Innanzitutto, la memorizzazione nella cache viene disattivata impostando UseQueryCache su false all'interno dell'oggetto options. In secondo luogo, hai eseguito l'accesso alle statistiche sulla query dall'oggetto job.
Torna a Cloud Shell ed esegui l'app:
node queryShakespeare.js
Dovresti visualizzare un elenco di messaggi di commit e le relative occorrenze. Inoltre, dovresti visualizzare anche alcune statistiche sulla query:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. Caricamento di dati in BigQuery
Se vuoi eseguire query sui tuoi dati, devi prima caricarli in BigQuery. BigQuery supporta il caricamento di dati da molte origini, come Google Cloud Storage, altri servizi Google o un'origine locale leggibile. Puoi anche trasmettere in streaming i tuoi dati. Puoi scoprire di più nella pagina Caricamento di dati in BigQuery.
In questo passaggio, caricherai un file JSON archiviato in Google Cloud Storage in una tabella BigQuery. Il file JSON si trova in: gs://cloud-samples-data/bigquery/us-states/us-states.json
Se vuoi conoscere i contenuti del file JSON, puoi utilizzare lo strumento a riga di comando gsutil per scaricarlo in Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Puoi notare che contiene l'elenco degli stati degli Stati Uniti e che ogni stato è un oggetto JSON su una riga separata:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Per caricare questo file JSON in BigQuery, crea un file createDataset.js e un file loadBigQueryJSON.js all'interno della cartella BigQueryDemo:
touch createDataset.js
touch loadBigQueryJSON.js
Installa la libreria client Node.js di Google Cloud Storage:
npm install --save @google-cloud/storage
Vai al file createDataset.js e inserisci il seguente codice:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Poi, vai al file loadBigQueryJSON.js e inserisci il seguente codice:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Dedica un minuto o due a studiare come il codice carica il file JSON e crea una tabella (con uno schema) in un set di dati.
Torna a Cloud Shell ed esegui l'app:
node createDataset.js
node loadBigQueryJSON.js
In BigQuery vengono creati un set di dati e una tabella:
Table my_states_table created.
Job [JOB ID] completed.
Per verificare che il set di dati sia stato creato, puoi accedere all'interfaccia utente web di BigQuery. Dovresti visualizzare un nuovo set di dati e una nuova tabella. Se passi alla scheda Anteprima della tabella, puoi visualizzare i dati effettivi:
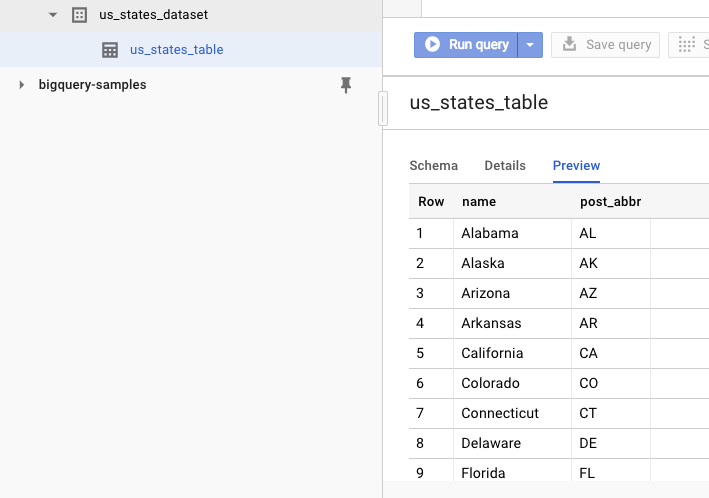
11. Complimenti!
Hai imparato a utilizzare BigQuery con Node.js.
Esegui la pulizia
Per evitare che al tuo account Google Cloud Platform vengano addebitate le risorse utilizzate in questa guida rapida, procedi come segue.
- Vai alla console Cloud Platform.
- Seleziona il progetto che vuoi chiudere, quindi fai clic su "Elimina" in alto: il progetto verrà pianificato per l'eliminazione.
Scopri di più
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js su Google Cloud Platform: https://cloud.google.com/nodejs/
- Libreria client Node.js di Google BigQuery: https://github.com/googleapis/nodejs-bigquery
Licenza
Questo lavoro è concesso in licenza ai sensi di una licenza Creative Commons Attribution 2.0 Generic.