
1. 概要
BigQuery は、Google が提供するペタバイト規模の低料金フルマネージド アナリティクス データ ウェアハウスです。BigQuery は NoOps(管理するインフラストラクチャが存在せず、データベース管理者が必要ない)であるため、使い慣れた SQL を使用してデータから有用な情報を見つけ出す作業に集中できます。また、このサービスは使った分だけ課金される従量制です。
この Codelab では、Google Cloud BigQuery クライアント ライブラリを使用して、Node.js で BigQuery 一般公開データセットに対してクエリを実行します。
学習内容
- Cloud Shell を使用する方法
- BigQuery API を有効にする方法
- API リクエストを認証する方法
- Node.js 用の BigQuery クライアント ライブラリをインストールする方法
- シェイクスピア作品のクエリ方法
- GitHub データセットに対するクエリ方法
- キャッシュ保存と統計情報の表示を調整する方法
必要なもの
アンケート
このチュートリアルをどのように使用されますか?
Node.js のご利用経験はどの程度ありますか?
Google Cloud Platform サービスのご利用経験についてどのように評価されますか?
2. 設定と要件
セルフペース型の環境設定
- Cloud Console にログインし、新しいプロジェクトを作成するか、既存のプロジェクトを再利用します(Gmail アカウントまたは G Suite アカウントをお持ちでない場合は、アカウントを作成する必要があります)。


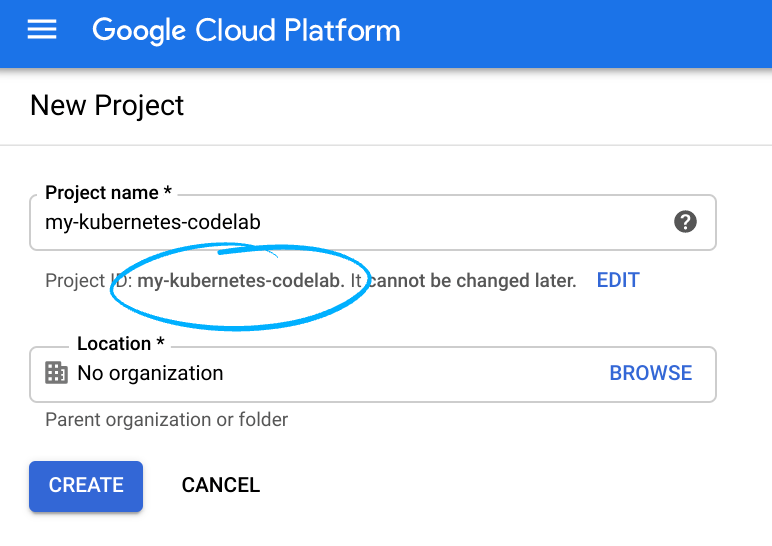
プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
- 次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
このコードラボを実行しても、費用はほとんどかからないはずです。このチュートリアル以外で請求が発生しないように、リソースのシャットダウン方法を説明する「クリーンアップ」セクションの手順に従うようにしてください。Google Cloud の新規ユーザーは $300 の無料トライアル プログラムをご利用いただけます。
Cloud Shell の起動
Cloud SDK コマンドライン ツールはノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Cloud Shell をアクティブにする
- Cloud Console で、[Cloud Shell をアクティブにする]
をクリックします。

Cloud Shell を初めて起動した場合は、その内容を説明する画面が(スクロールしなければ見えない位置に)表示されます。その場合は、[続行] をクリックしてください(以後表示されなくなります)。この中間画面は次のようになります。

すぐにプロビジョニングが実行され、Cloud Shell に接続されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。仮想マシンは Google Cloud で稼働し、永続的なホーム ディレクトリが 5 GB 用意されているため、ネットワークのパフォーマンスと認証が大幅に向上しています。このコードラボでの作業のほとんどは、ブラウザまたは Chromebook から実行できます。
Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自のプロジェクト ID が設定されていることがわかります。
- Cloud Shell で次のコマンドを実行して、認証されたことを確認します。
gcloud auth list
コマンド出力
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
上記のようになっていない場合は、次のコマンドで設定できます。
gcloud config set project <PROJECT_ID>
コマンド出力
Updated property [core/project].
3. BigQuery API を有効にする
BigQuery API は、すべての Google Cloud プロジェクトでデフォルトで有効になっています。Cloud Shell で次のコマンドを実行して、これが当てはまるかどうかを確認できます。
gcloud services list
BigQuery が表示されます。
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
BigQuery API が有効になっていない場合は、Cloud Shell で次のコマンドを使用して有効にできます。
gcloud services enable bigquery-json.googleapis.com
4. API リクエストを認証する
BigQuery API にリクエストを送信するには、サービス アカウントを使用する必要があります。サービス アカウントはプロジェクトに属し、Google BigQuery Node.js クライアント ライブラリで使用して BigQuery API リクエストを送信します。ほかのユーザー アカウントと同じように、サービス アカウントはメールアドレスで表されます。このセクションでは、Cloud SDK を使用してサービス アカウントを作成し、サービス アカウントの認証で必要になる認証情報を作成します。
まず、この Codelab 全体を通して使用する PROJECT_ID を使って環境変数を設定します。
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
次に、BigQuery API にアクセスする新しいサービス アカウントを作成します。
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
次に、作成した新しいサービス アカウントとしてログインするために Node.js コードで使用する認証情報を作成します。次のコマンドを使用して認証情報を作成し、JSON ファイル「~/key.json」に保存します。
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
最後に、GOOGLE_APPLICATION_CREDENTIALS 環境変数を設定します。これは、次のステップで説明する BigQuery API C# ライブラリが認証情報を検索する際に使用します。この環境変数は、作成した認証情報 JSON ファイルのフルパスに設定する必要があります。次のコマンドを使用して、環境変数を設定します。
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
BigQuery API の認証の詳細をご覧ください。
5. アクセス制御の設定
BigQuery は Identity and Access Management(IAM)を使用してリソースへのアクセスを管理します。BigQuery には、前の手順で作成したサービス アカウントに割り当てることができる事前定義ロール(ユーザー、データオーナー、データ閲覧者など)が多数あります。BigQuery ドキュメントのアクセス制御で、詳細を確認できます。
一般公開データセットに対してクエリを実行する前に、サービス アカウントに少なくとも bigquery.user ロールが付与されていることを確認する必要があります。Cloud Shell で次のコマンドを実行して、サービス アカウントに bigquery.user ロールを割り当てます。
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
次のコマンドを実行して、サービス アカウントにユーザーロールが割り当てられていることを確認できます。
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Node.js 用の BigQuery クライアント ライブラリをインストールする
まず、BigQueryDemo フォルダを作成して、そのフォルダに移動します。
mkdir BigQueryDemo
cd BigQueryDemo
次に、BigQuery クライアント ライブラリのサンプルを実行するために使用する Node.js プロジェクトを作成します。
npm init -y
作成された Node.js プロジェクトが表示されます。
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
BigQuery クライアント ライブラリをインストールします。
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
これで、BigQuery Node.js クライアント ライブラリを使用する準備が整いました。
7. シェイクスピア作品のクエリ
一般公開データセットは、BigQuery に保存され、一般に公開されるデータセットです。照会が可能な一般公開データセットは、他にも数多くあり、一部は Google でもホストされますが、多くはサードパーティでホストされます。詳細については、一般公開データセットのページをご覧ください。
BigQuery には、一般公開データセットのほかにも、クエリを実行できるサンプル テーブルがあります。これらのテーブルは bigquery-public-data:samples dataset に含まれています。これらのテーブルの 1 つは shakespeare. と呼ばれます。このテーブルには、シェイクスピア作品の単語の索引が含まれていて、それぞれのコーパスで各単語が出現する回数を示しています。
このステップでは、shakespeare テーブルに対してクエリを実行します。
まず、Cloud Shell の右上にあるコードエディタを開きます。
BigQueryDemo フォルダ内に queryShakespeare.js ファイルを作成します。
touch queryShakespeare.js
queryShakespeare.js ファイルに移動し、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
コードを 1 ~ 2 分ほど確認して、テーブルのクエリ方法を確認します。
Cloud Shell に戻ってアプリを実行します。
node queryShakespeare.js
単語とその出現回数のリストが表示されます。
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. GitHub データセットに対するクエリ
BigQuery の理解を深めるため、GitHub 一般公開データセットに対してクエリを発行します。最も一般的なコミット メッセージは GitHub で確認できます。また、BigQuery のウェブ UI を使用して、アドホック クエリをプレビューして実行します。
データを表示するには、BigQuery ウェブ UI で GitHub データセットを開きます。
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
データの外観を簡単にプレビューするには、[プレビュー] タブをクリックします。
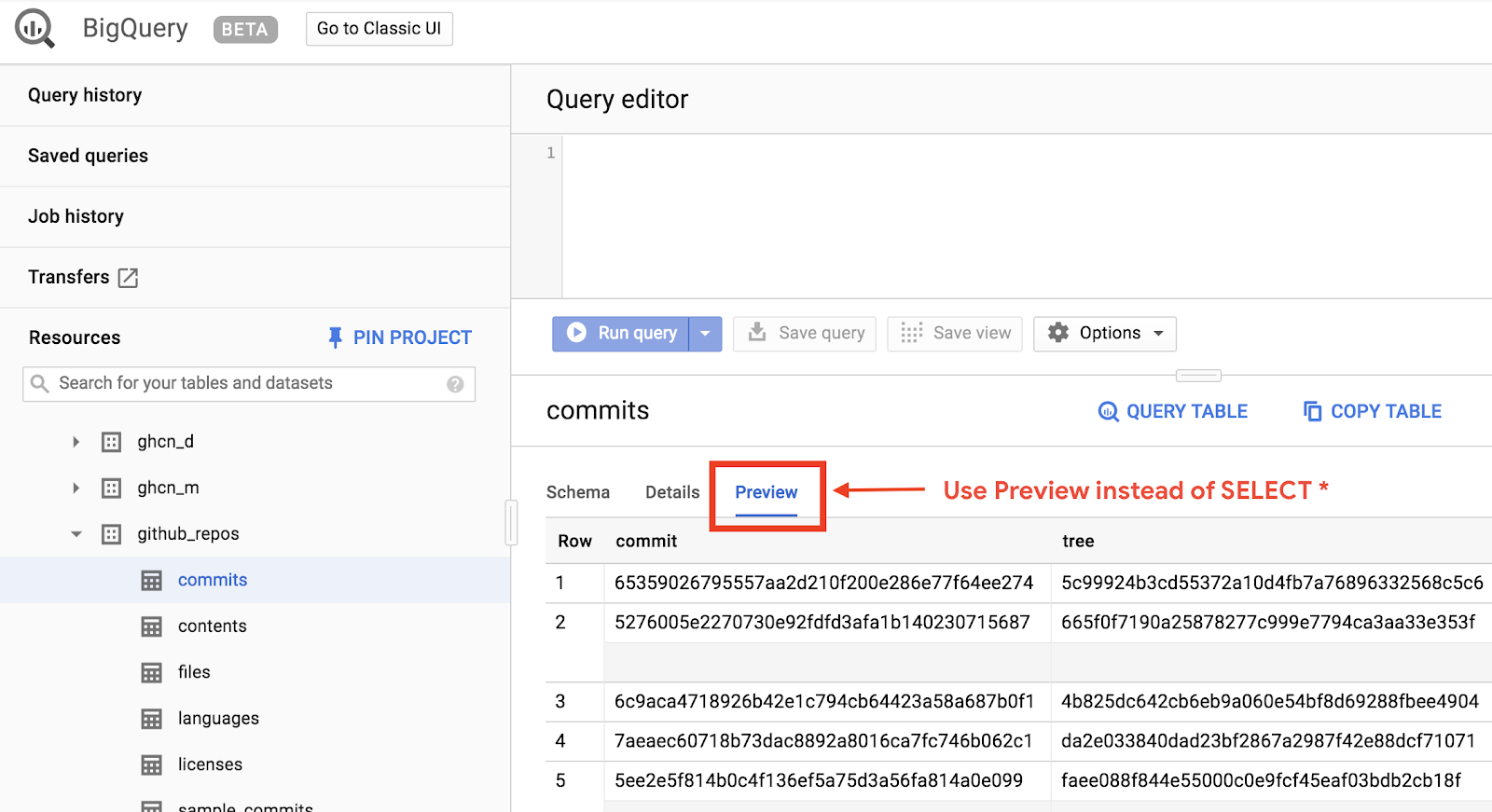
BigQueryDemo フォルダ内に queryGitHub.js ファイルを作成します。
touch queryGitHub.js
queryGitHub.js ファイルに移動し、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
コードを 1 ~ 2 分ほど確認して、最も一般的なコミット メッセージのテーブルがどのようにクエリされるかを確認します。
Cloud Shell に戻ってアプリを実行します。
node queryGitHub.js
コミット メッセージとその発生回数のリストが表示されます。
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. キャッシュ保存と統計情報
クエリを実行すると、BigQuery は結果をキャッシュに保存します。その結果、後続の同一クエリの所要時間が大幅に短縮されます。クエリ オプションを使用してキャッシュ保存を無効にできます。BigQuery は、作成時間、終了時間、処理されたバイト数の合計など、クエリに関する統計情報も追跡します。
このステップでは、キャッシュ保存を無効にして、クエリに関する統計情報を表示します。
BigQueryDemo フォルダ内の queryShakespeare.js ファイルに移動し、コードを次のコードに置き換えます。
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
コードについて、いくつか注意点があります。まず、options オブジェクト内で UseQueryCache を false に設定して、キャッシュ保存を無効にします。次に、ジョブ オブジェクトからクエリに関する統計情報にアクセスしました。
Cloud Shell に戻ってアプリを実行します。
node queryShakespeare.js
コミット メッセージとその発生回数のリストが表示されます。また、クエリに関する統計情報も表示されます。
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. BigQuery へのデータの読み込み
独自のデータをクエリする場合は、まずデータを BigQuery に読み込む必要があります。BigQuery は、Google Cloud Storage、他の Google サービス、ローカルの読み取り可能なソースなど、さまざまなソースからのデータの読み込みをサポートしています。データをストリーミングすることもできます。詳細については、BigQuery へのデータの読み込みをご覧ください。
このステップでは、Google Cloud Storage に保存されている JSON ファイルを BigQuery テーブルに読み込みます。JSON ファイルは gs://cloud-samples-data/bigquery/us-states/us-states.json にあります。
JSON ファイルの内容を確認するには、Cloud Shell で gsutil コマンドライン ツールを使用してダウンロードします。
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
米国の州のリストが含まれており、各州が別の行の JSON オブジェクトになっていることがわかります。
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
この JSON ファイルを BigQuery に読み込むには、BigQueryDemo フォルダ内に createDataset.js ファイルと loadBigQueryJSON.js ファイルを作成します。
touch createDataset.js
touch loadBigQueryJSON.js
Google Cloud Storage Node.js クライアント ライブラリをインストールします。
npm install --save @google-cloud/storage
createDataset.js ファイルに移動し、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
次に、loadBigQueryJSON.js ファイルに移動して、次のコードを挿入します。
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
コードが JSON ファイルを読み込み、データセットに(スキーマを含む)テーブルを作成する方法を 1 ~ 2 分ほどで確認します。
Cloud Shell に戻ってアプリを実行します。
node createDataset.js
node loadBigQueryJSON.js
BigQuery にデータセットとテーブルが作成されます。
Table my_states_table created.
Job [JOB ID] completed.
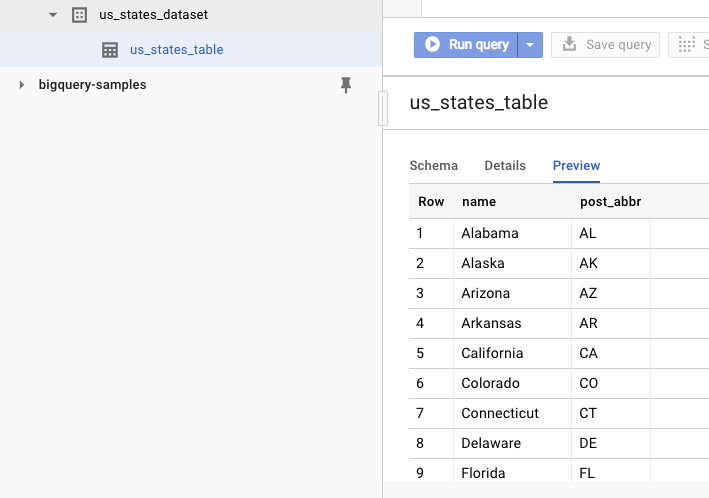
データセットが作成されたことを確認するには、BigQuery ウェブ UI にアクセスします。新しいデータセットとテーブルが表示されます。テーブルの [プレビュー] タブに切り替えると、実際のデータを確認できます。
11. 完了
Node.js を使用して BigQuery を使用する方法を学びました。
クリーンアップ
このクイックスタートで使用するリソースに対して Google Cloud Platform アカウントに課金されないようにするには:
- Cloud Platform Console に移動します。
- シャットダウンするプロジェクトを選択し、上部の [削除] をクリックします。これにより、プロジェクトの削除がスケジュールされます。
詳細
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Google Cloud Platform での Node.js: https://cloud.google.com/nodejs/
- Google BigQuery Node.js クライアント ライブラリ: https://github.com/googleapis/nodejs-bigquery
ライセンス
この作業はクリエイティブ・コモンズの表示 2.0 汎用ライセンスにより使用許諾されています。