
1. Genel Bakış
BigQuery; Google'ın tümüyle yönetilen, petabayt ölçekli, düşük maliyetli analiz veri ambarıdır. BigQuery NoOps'tur. Yönetilecek altyapı olmadığından ve veritabanı yöneticisine gerek olmadığından verileri analiz ederek anlamlı analizler bulmaya odaklanabilir, aşina olduğunuz SQL'i kullanabilir ve kullandıkça öde modelimizden yararlanabilirsiniz.
Bu codelab'de, Node.js ile BigQuery herkese açık veri kümelerini sorgulamak için Google Cloud BigQuery İstemci Kitaplığı'nı kullanacaksınız.
Neler öğreneceksiniz?
- Cloud Shell'i kullanma
- BigQuery API'yi etkinleştirme
- API isteklerinin kimliğini doğrulama
- Node.js için BigQuery istemci kitaplığını yükleme
- Shakespeare'in eserlerini sorgulama
- GitHub veri kümesini sorgulama
- Önbelleğe alma ve görüntüleme istatistiklerini ayarlama
Gerekenler
Anket
Bu eğitimi nasıl kullanacaksınız?
Node.js ile ilgili deneyiminizi nasıl değerlendirirsiniz?
Google Cloud Platform hizmetlerini kullanma deneyiminizi nasıl değerlendirirsiniz?
2. Kurulum ve Gereksinimler
Yönlendirmesiz ortam kurulumu
- Cloud Console'da oturum açın ve yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanın. (Gmail veya G Suite hesabınız yoksa hesap oluşturmanız gerekir.)


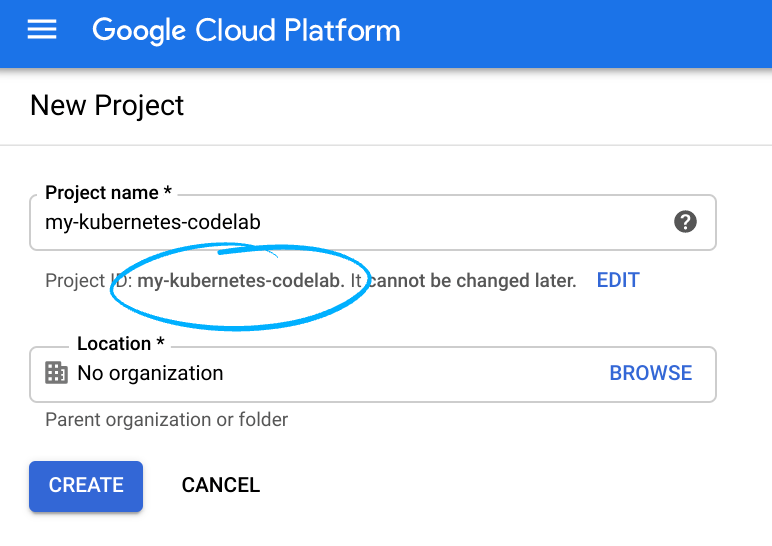
Proje kimliğini unutmayın. Bu kimlik, tüm Google Cloud projelerinde benzersiz bir addır (Yukarıdaki ad zaten alınmış olduğundan sizin için çalışmayacaktır). Bu codelab'in ilerleyen kısımlarında PROJECT_ID olarak adlandırılacaktır.
- Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i tamamlamak neredeyse hiç maliyetli değildir. Bu eğitimin ötesinde faturalandırma ücreti alınmaması için kaynakları nasıl kapatacağınız konusunda size tavsiyelerde bulunan "Temizleme" bölümündeki talimatları uyguladığınızdan emin olun. Google Cloud'un yeni kullanıcıları 300 ABD doları değerinde ücretsiz deneme programından yararlanabilir.
Cloud Shell'i başlatma
Cloud SDK komut satırı aracı dizüstü bilgisayarınızdan uzaktan çalıştırılabilir ancak bu codelab'de bulutta çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Cloud Shell'i etkinleştirme
- Cloud Console'da Cloud Shell'i etkinleştir 'i
tıklayın.

Cloud Shell'i daha önce hiç başlatmadıysanız ne olduğunu açıklayan bir ara ekran (ekranın alt kısmı) gösterilir. Bu durumda Devam'ı tıkladığınızda bu ekranı bir daha görmezsiniz. Bu tek seferlik ekran aşağıdaki gibi görünür:

Cloud Shell'in temel hazırlığı ve bağlanması yalnızca birkaç dakikanızı alır.

Bu sanal makine, ihtiyaç duyduğunuz tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin bulunur ve Google Cloud'da çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki çalışmalarınızın neredeyse tamamını yalnızca bir tarayıcı veya Chromebook'unuzla yapabilirsiniz.
Cloud Shell'e bağlandıktan sonra kimliğinizin doğrulandığını ve projenin, proje kimliğinize ayarlandığını görürsünüz.
- Kimliğinizin doğrulandığını onaylamak için Cloud Shell'de şu komutu çalıştırın:
gcloud auth list
Komut çıkışı
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
Komut çıkışı
[core] project = <PROJECT_ID>
Değilse şu komutla ayarlayabilirsiniz:
gcloud config set project <PROJECT_ID>
Komut çıkışı
Updated property [core/project].
3. BigQuery API'yi etkinleştirme
BigQuery API, tüm Google Cloud projelerinde varsayılan olarak etkinleştirilmelidir. Bunun doğru olup olmadığını Cloud Shell'deki aşağıdaki komutla kontrol edebilirsiniz:
gcloud services list
BigQuery'nin listelendiğini görmeniz gerekir:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
BigQuery API etkinleştirilmemişse Cloud Shell'de aşağıdaki komutu kullanarak etkinleştirebilirsiniz:
gcloud services enable bigquery-json.googleapis.com
4. API isteklerinin kimliğini doğrulama
BigQuery API'ye istekte bulunmak için hizmet hesabı kullanmanız gerekir. Hizmet hesabı projenize aittir ve Google BigQuery Node.js istemci kitaplığı tarafından BigQuery API istekleri göndermek için kullanılır. Diğer tüm kullanıcı hesapları gibi, hizmet hesabı da bir e-posta adresiyle temsil edilir. Bu bölümde, hizmet hesabı oluşturmak için Cloud SDK'yı kullanacak, ardından hizmet hesabı olarak kimlik doğrulamak için gereken kimlik bilgilerini oluşturacaksınız.
Öncelikle, bu codelab boyunca kullanacağınız PROJECT_ID'nizle bir ortam değişkeni ayarlayın:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
Ardından, BigQuery API'ye erişmek için yeni bir hizmet hesabı oluşturun:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
Ardından, Node.js kodunuzun yeni hizmet hesabınız olarak giriş yapmak için kullanacağı kimlik bilgilerini oluşturun. Bu kimlik bilgilerini oluşturduktan sonra aşağıdaki komut aracılığıyla bir JSON dosyası "~/key.json" olarak kaydedin:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
Son olarak, kimlik bilgilerinizi bulmak için sonraki adımda ele alınan BigQuery API C# kitaplığı tarafından kullanılan GOOGLE_APPLICATION_CREDENTIALS ortam değişkenini ayarlayın. Ortam değişkeni, oluşturduğunuz kimlik bilgisi JSON dosyasının tam dizin yoluna göre ayarlanmalıdır. Aşağıdaki komutu kullanarak ortam değişkenini ayarlayın:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
BigQuery API'nin kimliğini doğrulama hakkında daha fazla bilgi edinebilirsiniz.
5. Erişim denetimini ayarlama
BigQuery, kaynaklara erişimi yönetmek için Identity and Access Management'ı (IAM) kullanır. BigQuery'de, önceki adımda oluşturduğunuz hizmet hesabınıza atayabileceğiniz bir dizi önceden tanımlanmış rol (kullanıcı, dataOwner, dataViewer vb.) bulunur. Erişim denetimi hakkında daha fazla bilgiyi BigQuery dokümanlarında bulabilirsiniz.
Herkese açık veri kümelerini sorgulayabilmek için hizmet hesabının en azından bigquery.user rolüne sahip olduğundan emin olmanız gerekir. Cloud Shell'de, hizmet hesabına bigquery.user rolünü atamak için aşağıdaki komutu çalıştırın:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
Hizmet hesabına kullanıcı rolünün atandığını doğrulamak için aşağıdaki komutu çalıştırabilirsiniz:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. Node.js için BigQuery istemci kitaplığını yükleyin
Öncelikle BigQueryDemo klasörü oluşturun ve bu klasöre gidin:
mkdir BigQueryDemo
cd BigQueryDemo
Ardından, BigQuery istemci kitaplığı örneklerini çalıştırmak için kullanacağınız bir Node.js projesi oluşturun:
npm init -y
Oluşturulan Node.js projesini görmelisiniz:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
BigQuery istemci kitaplığını yükleyin:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
Artık BigQuery Node.js istemci kitaplığını kullanmaya hazırsınız.
7. Shakespeare'in eserlerini sorgulama
Herkese açık veri kümesi, BigQuery'de depolanan ve genel kullanıma sunulan tüm veri kümeleridir. Sorgulayabileceğiniz birçok başka herkese açık veri kümesi vardır. Bunlardan bazıları Google tarafından, çok daha fazlası ise üçüncü taraflarca barındırılır. Daha fazla bilgiyi Herkese Açık Veri Kümeleri sayfasında bulabilirsiniz.
BigQuery, ortak veri kümelerinin yanı sıra sorgulayabileceğiniz sınırlı sayıda örnek tablo da sağlar. Bu tablolar bigquery-public-data:samples dataset içinde yer alır. Bu tablolardan birinin adı shakespeare.. Bu tablo, Shakespeare'in eserlerinin kelime dizinini içerir ve her kelimenin her korpusta kaç kez geçtiğini gösterir.
Bu adımda, shakespeare tablosunu sorgulayacaksınız.
Öncelikle Cloud Shell'in sağ üst tarafındaki kod düzenleyiciyi açın:
BigQueryDemo klasöründe queryShakespeare.js dosyası oluşturun :
touch queryShakespeare.js
queryShakespeare.js dosyasına gidin ve aşağıdaki kodu ekleyin:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
Kodu incelemek ve tablonun nasıl sorgulandığını görmek için birkaç dakikanızı ayırın.
Cloud Shell'e dönüp uygulamayı çalıştırın:
node queryShakespeare.js
Kelimelerin ve kaç kez kullanıldıklarının listesini görürsünüz:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. GitHub veri kümesini sorgulama
BigQuery'ye daha aşina olmak için şimdi GitHub herkese açık veri kümesi ile ilgili bir sorgu göndereceksiniz. En yaygın commit mesajlarını GitHub'da bulabilirsiniz. Ayrıca, anlık sorguları önizlemek ve çalıştırmak için BigQuery'nin web kullanıcı arayüzünü kullanacaksınız.
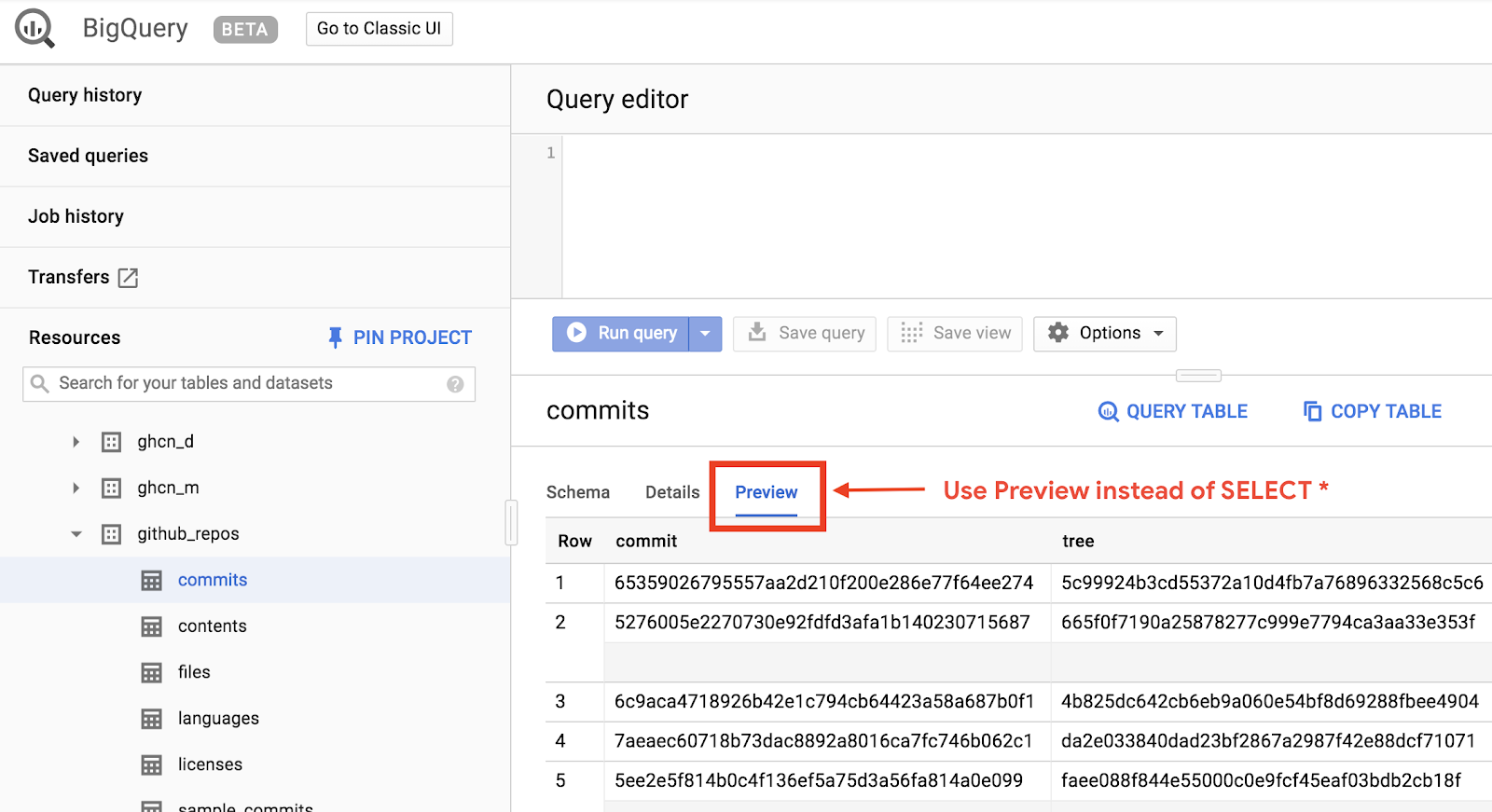
Verileri görüntülemek için GitHub veri kümesini BigQuery web arayüzünde açın:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Verilerin nasıl göründüğüne dair hızlı bir önizleme almak için Önizleme sekmesini tıklayın:
BigQueryDemo klasöründe queryGitHub.js dosyasını oluşturun:
touch queryGitHub.js
queryGitHub.js dosyasına gidin ve aşağıdaki kodu ekleyin:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
Kodu incelemek ve tablonun en yaygın commit mesajları için nasıl sorgulandığını görmek için bir veya iki dakikanızı ayırın.
Cloud Shell'e dönüp uygulamayı çalıştırın:
node queryGitHub.js
Commit mesajlarının ve bunların oluşumlarının listesini görürsünüz:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. Önbelleğe alma ve istatistikler
Sorgu çalıştırdığınızda BigQuery sonuçları önbelleğe alır. Bu nedenle, sonraki aynı sorgular çok daha kısa sürede tamamlanır. Sorgu seçeneklerini kullanarak önbelleğe almayı devre dışı bırakabilirsiniz. BigQuery, sorgularla ilgili bazı istatistikleri de (ör. oluşturma zamanı, bitiş zamanı ve işlenen toplam bayt) takip eder.
Bu adımda, önbelleğe almayı devre dışı bırakacak ve sorgularla ilgili bazı istatistikleri göstereceksiniz.
BigQueryDemo klasöründeki queryShakespeare.js dosyasına gidin ve kodu aşağıdakilerle değiştirin:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
Kodla ilgili dikkat edilmesi gereken bazı noktalar: Öncelikle, UseQueryCache nesnesinde options ayarı false olarak belirlenerek önbelleğe alma devre dışı bırakılır. İkincisi, sorguyla ilgili istatistiklere iş nesnesinden erişmişsinizdir.
Cloud Shell'e dönüp uygulamayı çalıştırın:
node queryShakespeare.js
Commit iletilerinin ve bunların oluşumlarının listesini görürsünüz. Ayrıca sorguyla ilgili bazı istatistikler de görürsünüz:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. BigQuery'ye veri yükleme
Kendi verilerinizi sorgulamak istiyorsanız önce verilerinizi BigQuery'ye yüklemeniz gerekir. BigQuery, Google Cloud Storage, diğer Google hizmetleri veya yerel, okunabilir bir kaynak gibi birçok kaynaktan veri yüklemeyi destekler. Verilerinizi yayınlayabilirsiniz. Daha fazla bilgiyi BigQuery'ye Veri Yükleme sayfasında bulabilirsiniz.
Bu adımda, Google Cloud Storage'da depolanan bir JSON dosyasını BigQuery tablosuna yükleyeceksiniz. JSON dosyası şu konumda bulunur: gs://cloud-samples-data/bigquery/us-states/us-states.json
JSON dosyasının içeriğini merak ediyorsanız Cloud Shell'de indirmek için gsutil komut satırı aracını kullanabilirsiniz:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
Bu dosyanın ABD eyaletlerinin listesini içerdiğini ve her eyaletin ayrı bir satırda JSON nesnesi olarak yer aldığını görebilirsiniz:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
Bu JSON dosyasını BigQuery'ye yüklemek için createDataset.js klasöründe bir BigQueryDemo dosyası ve bir loadBigQueryJSON.js dosyası oluşturun:
touch createDataset.js
touch loadBigQueryJSON.js
Google Cloud Storage Node.js istemci kitaplığını yükleyin:
npm install --save @google-cloud/storage
createDataset.js dosyasına gidin ve aşağıdaki kodu ekleyin:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
Ardından, loadBigQueryJSON.js dosyasına gidin ve aşağıdaki kodu ekleyin:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
Kodun JSON dosyasını nasıl yüklediğini ve bir veri kümesinde (şemayla birlikte) nasıl tablo oluşturduğunu incelemek için bir veya iki dakikanızı ayırın.
Cloud Shell'e dönüp uygulamayı çalıştırın:
node createDataset.js
node loadBigQueryJSON.js
BigQuery'de bir veri kümesi ve bir tablo oluşturulur:
Table my_states_table created.
Job [JOB ID] completed.
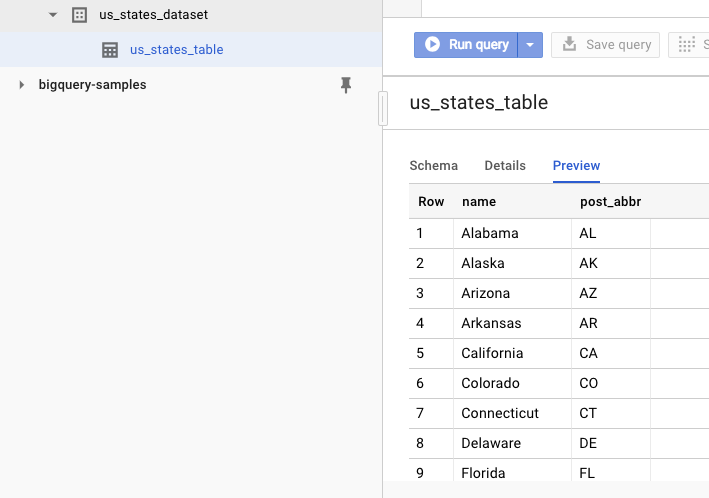
Veri kümesinin oluşturulduğunu doğrulamak için BigQuery web kullanıcı arayüzüne gidebilirsiniz. Yeni bir veri kümesi ve tablo görmeniz gerekir. Tablonun Önizleme sekmesine geçerseniz gerçek verileri görebilirsiniz:
11. Tebrikler!
Node.js kullanarak BigQuery'yi nasıl kullanacağınızı öğrendiniz.
Temizleme
Bu hızlı başlangıçta kullanılan kaynaklar için Google Cloud Platform hesabınızın ücretlendirmesini önlemek amacıyla:
- Cloud Platform Console'a gidin.
- Kapatmak istediğiniz projeyi seçin, ardından üst kısımdaki "Sil"i tıklayın. Bu işlem, projenin silinmesini planlar.
Daha Fazla Bilgi
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Google Cloud Platform'da Node.js: https://cloud.google.com/nodejs/
- Google BigQuery Node.js istemci kitaplığı: https://github.com/googleapis/nodejs-bigquery
Lisans
Bu çalışma, Creative Commons Attribution 2.0 Genel Amaçlı Lisans ile lisans altına alınmıştır.