
1. סקירה כללית
BigQuery הוא מחסן נתונים לצורכי ניתוח מנוהל במלואו של Google, בקנה מידה של פטה-בייט ובעלות נמוכה. BigQuery הוא NoOps – אין תשתית לניהול ולא צריך מנהל מסד נתונים – כך שאתם יכולים להתמקד בניתוח נתונים כדי למצוא תובנות משמעותיות, להשתמש ב-SQL מוכר ולנצל את היתרונות של המודל שלנו של תשלום לפי שימוש.
ב-Codelab הזה תשתמשו בספריית הלקוח של Google Cloud BigQuery כדי לשלוח שאילתות למערכי נתונים ציבוריים של BigQuery באמצעות Node.js.
מה תלמדו
- איך משתמשים ב-Cloud Shell
- איך מפעילים את BigQuery API
- איך מאמתים בקשות API
- איך מתקינים את ספריית הלקוח של BigQuery ל-Node.js
- איך שולחים שאילתות לגבי יצירות של שייקספיר
- איך מריצים שאילתות בקבוצת הנתונים של GitHub
- איך משנים את הגדרות השמירה במטמון ואת הנתונים הסטטיסטיים שמוצגים
מה תצטרכו
סקר
איך תשתמשו במדריך הזה?
איך היית מדרג את חוויית השימוש שלך ב-Node.js?
איזה דירוג מגיע לדעתך לחוויית השימוש שלך בשירותים של Google Cloud Platform?
2. הגדרה ודרישות
הגדרת סביבה בקצב אישי
- נכנסים אל Cloud Console ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. (אם עדיין אין לכם חשבון Gmail או G Suite, אתם צריכים ליצור חשבון).


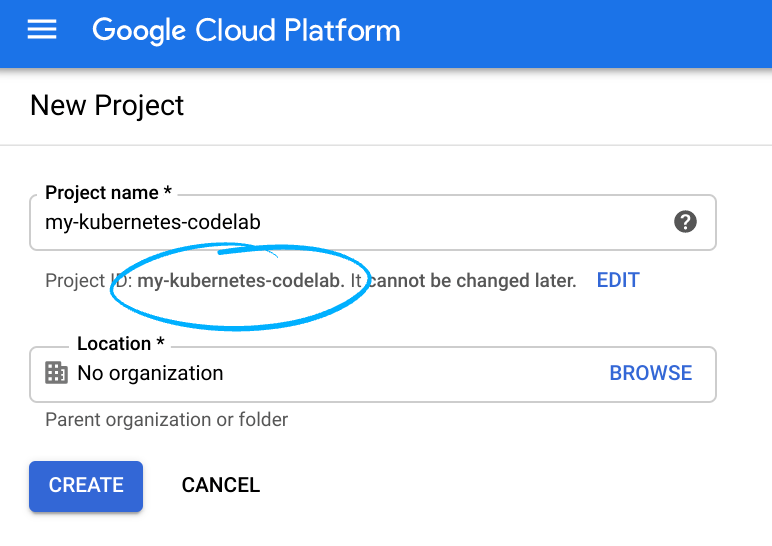
חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שלמעלה כבר תפוס ולא יתאים לכם, מצטערים!). בהמשך ה-codelab הזה נתייחס אליו כאל PROJECT_ID.
- לאחר מכן, תצטרכו להפעיל את החיוב ב-Cloud Console כדי להשתמש במשאבים של Google Cloud.
העלות של התרגול הזה לא אמורה להיות גבוהה, ואולי אפילו לא תצטרכו לשלם בכלל. חשוב לפעול לפי ההוראות בקטע 'ניקוי' כדי להשבית את המשאבים, וכך לא תחויבו אחרי שתסיימו את המדריך הזה. משתמשים חדשים ב-Google Cloud זכאים לתוכנית תקופת ניסיון בחינם בשווי 300$.
מפעילים את Cloud Shell
אפשר להפעיל את כלי שורת הפקודה של Cloud SDK מרחוק מהמחשב הנייד, אבל בסדנת הקוד הזו תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
הפעלת Cloud Shell
- ב-Cloud Console, לוחצים על Activate Cloud Shell
.

אם זו הפעם הראשונה שאתם מפעילים את Cloud Shell, יוצג לכם מסך ביניים (מתחת לקו הקיפול) עם תיאור של הכלי. במקרה כזה, לוחצים על המשך (והמסך הזה לא יוצג לכם יותר). כך נראה המסך החד-פעמי:

הקצאת המשאבים והחיבור ל-Cloud Shell נמשכים רק כמה רגעים.

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את רוב העבודה ב-codelab הזה, אם לא את כולה, באמצעות דפדפן או Chromebook.
אחרי שמתחברים ל-Cloud Shell, אמור להופיע אימות שכבר בוצע ושהפרויקט כבר הוגדר לפי מזהה הפרויקט.
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שעברתם אימות:
gcloud auth list
פלט הפקודה
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
פלט הפקודה
[core] project = <PROJECT_ID>
אם לא, אפשר להגדיר אותו באמצעות הפקודה הבאה:
gcloud config set project <PROJECT_ID>
פלט הפקודה
Updated property [core/project].
3. הפעלת BigQuery API
BigQuery API אמור להיות מופעל כברירת מחדל בכל פרויקט ב-Google Cloud. כדי לבדוק אם זה נכון, מריצים את הפקודה הבאה ב-Cloud Shell:
gcloud services list
האפשרות BigQuery אמורה להופיע ברשימה:
NAME TITLE
bigquery-json.googleapis.com BigQuery API
...
אם BigQuery API לא מופעל, אפשר להשתמש בפקודה הבאה ב-Cloud Shell כדי להפעיל אותו:
gcloud services enable bigquery-json.googleapis.com
4. אימות בקשות API
כדי לשלוח בקשות ל-BigQuery API, צריך להשתמש בחשבון שירות. חשבון שירות שייך לפרויקט שלכם, וספריית הלקוח של Google BigQuery Node.js משתמשת בו כדי לשלוח בקשות ל-BigQuery API. בדומה לכל חשבון משתמש אחר, חשבון שירות מיוצג על ידי כתובת אימייל. בקטע הזה נשתמש ב-Cloud SDK כדי ליצור חשבון שירות, ואז ניצור פרטי כניסה שיידרשו לאימות בתור חשבון השירות.
קודם צריך להגדיר משתנה סביבה עם PROJECT_ID, שבו תשתמשו לאורך כל ה-codelab הזה:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value core/project)
לאחר מכן, יוצרים חשבון שירות חדש כדי לגשת אל BigQuery API באמצעות:
gcloud iam service-accounts create my-bigquery-sa --display-name "my bigquery codelab service account"
לאחר מכן, יוצרים פרטי כניסה שהקוד של Node.js ישתמש בהם כדי להיכנס בתור חשבון השירות החדש. יוצרים את פרטי הכניסה ושומרים אותם כקובץ JSON ~/key.json באמצעות הפקודה הבאה:
gcloud iam service-accounts keys create ~/key.json --iam-account my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com
לבסוף, מגדירים את משתנה הסביבה GOOGLE_APPLICATION_CREDENTIALS, שמשמש את ספריית BigQuery API C# , שמוסבר עליה בשלב הבא, כדי למצוא את פרטי הכניסה. משתנה הסביבה צריך להיות מוגדר לנתיב המלא של קובץ ה-JSON של פרטי הכניסה שיצרתם. מגדירים את משתנה הסביבה באמצעות הפקודה הבאה:
export GOOGLE_APPLICATION_CREDENTIALS="/home/${USER}/key.json"
5. הגדרת בקרת גישה
ב-BigQuery נעשה שימוש בניהול זהויות והרשאות גישה (IAM) כדי לנהל את הגישה למשאבים. ל-BigQuery יש מספר תפקידים מוגדרים מראש (משתמש, בעל נתונים, צופה בנתונים וכו') שאפשר להקצות לחשבון השירות שיצרתם בשלב הקודם. מידע נוסף על בקרת גישה זמין במאמרי העזרה של BigQuery.
כדי להריץ שאילתות במערכי הנתונים הציבוריים, צריך לוודא שלחשבון השירות יש לפחות את התפקיד bigquery.user. ב-Cloud Shell, מריצים את הפקודה הבאה כדי להקצות את התפקיד bigquery.user לחשבון השירות:
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} --member "serviceAccount:my-bigquery-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" --role "roles/bigquery.user"
כדי לוודא שחשבון השירות קיבל את תפקיד המשתמש, מריצים את הפקודה הבאה:
gcloud projects get-iam-policy $GOOGLE_CLOUD_PROJECT
6. התקנה של ספריית הלקוח של BigQuery ל-Node.js
קודם יוצרים תיקייה BigQueryDemo ועוברים אליה:
mkdir BigQueryDemo
cd BigQueryDemo
לאחר מכן, יוצרים פרויקט Node.js שבו ישמשו דוגמאות של ספריית הלקוח של BigQuery:
npm init -y
אתם אמורים לראות את פרויקט Node.js שנוצר:
{
"name": "BigQueryDemo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
מתקינים את ספריית הלקוח של BigQuery:
npm install --save @google-cloud/bigquery
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN BigQueryDemo@1.0.0 No description
npm WARN BigQueryDemo@1.0.0 No repository field.
+ @google-cloud/bigquery@2.1.0
added 69 packages from 105 contributors and audited 147 packages in 4.679s
found 0 vulnerabilities
עכשיו אתם מוכנים להשתמש בספריית הלקוח של BigQuery Node.js.
7. שליחת שאילתות לגבי יצירות של שייקספיר
מערך נתונים ציבורי הוא כל מערך נתונים שמאוחסן ב-BigQuery וזמין לציבור הרחב. יש עוד הרבה מערכי נתונים ציבוריים שאפשר להריץ עליהם שאילתות. חלק מהם מתארחים גם ב-Google, אבל רובם מתארחים אצל צדדים שלישיים. אפשר לקרוא מידע נוסף בדף מערכי נתונים ציבוריים.
בנוסף למערכי הנתונים הציבוריים, BigQuery מספק מספר מוגבל של טבלאות לדוגמה שאפשר להריץ עליהן שאילתות. הטבלאות האלה מופיעות בbigquery-public-data:samples dataset. אחת מהטבלאות האלה נקראת shakespeare. היא מכילה אינדקס מילים של יצירות שייקספיר, עם מספר הפעמים שכל מילה מופיעה בכל אוסף.
בשלב הזה תריצו שאילתה על הטבלה shakespeare.
קודם פותחים את עורך הקוד בפינה השמאלית העליונה של Cloud Shell:

יוצרים קובץ queryShakespeare.js בתוך התיקייה BigQueryDemo :
touch queryShakespeare.js
עוברים לקובץ queryShakespeare.js ומוסיפים את הקוד הבא:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeare() {
// Queries a public Shakespeare dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(row));
}
queryShakespeare();
}
main();
כדאי להקדיש דקה או שתיים כדי לבדוק את הקוד ולראות איך מתבצעת השאילתה בטבלה.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
node queryShakespeare.js
אמורה להופיע רשימה של מילים והמופעים שלהן:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
...
8. הרצת שאילתה בקבוצת הנתונים של GitHub
כדי להכיר טוב יותר את BigQuery, נריץ עכשיו שאילתה על מערך הנתונים הציבורי של GitHub. אפשר למצוא את הודעות הקומיט הנפוצות ביותר ב-GitHub. תשתמשו גם בממשק האינטרנט של BigQuery כדי להציג תצוגה מקדימה של שאילתות אד-הוק ולהריץ אותן.
כדי לראות את הנתונים, פותחים את מערך הנתונים של GitHub בממשק המשתמש האינטרנטי של BigQuery:
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
כדי לראות תצוגה מקדימה של הנתונים, לוחצים על הכרטיסייה Preview (תצוגה מקדימה):

יוצרים את הקובץ queryGitHub.js בתוך התיקייה BigQueryDemo:
touch queryGitHub.js
עוברים לקובץ queryGitHub.js ומוסיפים את הקוד הבא:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryGitHub() {
// Queries a public GitHub dataset.
// Create a client
const bigqueryClient = new BigQuery();
// The SQL query to run
const sqlQuery = `SELECT subject AS subject, COUNT(*) AS num_duplicates
FROM \`bigquery-public-data.github_repos.commits\`
GROUP BY subject
ORDER BY num_duplicates
DESC LIMIT 10`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
};
// Run the query
const [rows] = await bigqueryClient.query(options);
console.log('Rows:');
rows.forEach(row => console.log(`${row.subject}: ${row.num_duplicates}`));
}
queryGitHub();
}
main();
כדאי להקדיש דקה או שתיים כדי לבדוק את הקוד ולראות איך מתבצעת שאילתה בטבלה כדי למצוא את הודעות הקומיט הנפוצות ביותר.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
node queryGitHub.js
אמורה להופיע רשימה של הודעות על ביצוע שינויים והמופעים שלהן:
Rows:
Update README.md: 2572220
: 1985733
Initial commit: 1940228
Mirroring from Micro.blog.: 646772
update: 592520
Update data.json: 548730
Update data.js: 548354
...
9. שמירה במטמון ונתונים סטטיסטיים
כשמריצים שאילתה, BigQuery שומר את התוצאות במטמון. כתוצאה מכך, שאילתות זהות חוזרות ייקחו הרבה פחות זמן. אפשר להשבית את השמירה במטמון באמצעות אפשרויות השאילתה. ב-BigQuery מתבצע גם מעקב אחרי נתונים סטטיסטיים מסוימים לגבי השאילתות, כמו זמן היצירה, זמן הסיום והמספר הכולל של בייטים שעברו עיבוד.
בשלב הזה משביתים את השמירה במטמון ומציגים נתונים סטטיסטיים לגבי השאילתות.
עוברים לקובץ queryShakespeare.js בתוך התיקייה BigQueryDemo ומחליפים את הקוד בקוד הבא:
'use strict';
function main() {
// Import the Google Cloud client library
const {BigQuery} = require('@google-cloud/bigquery');
async function queryShakespeareDisableCache() {
// Queries the Shakespeare dataset with the cache disabled.
// Create a client
const bigqueryClient = new BigQuery();
const sqlQuery = `SELECT word, word_count
FROM \`bigquery-public-data.samples.shakespeare\`
WHERE corpus = @corpus
AND word_count >= @min_word_count
ORDER BY word_count DESC`;
const options = {
query: sqlQuery,
// Location must match that of the dataset(s) referenced in the query.
location: 'US',
params: {corpus: 'romeoandjuliet', min_word_count: 250},
useQueryCache: false,
};
// Run the query as a job
const [job] = await bigqueryClient.createQueryJob(options);
console.log(`Job ${job.id} started.`);
// Wait for the query to finish
const [rows] = await job.getQueryResults();
// Print the results
console.log('Rows:');
rows.forEach(row => console.log(row));
// Print job statistics
console.log('JOB STATISTICS:')
console.log(`Status: ${job.metadata.status.state}`);
console.log(`Creation time: ${job.metadata.statistics.creationTime}`);
console.log(`Start time: ${job.metadata.statistics.startTime}`);
console.log(`Statement type: ${job.metadata.statistics.query.statementType}`);
}
queryShakespeareDisableCache();
}
main();
כמה דברים שכדאי לשים לב אליהם בקוד. קודם כול, משביתים את השמירה במטמון על ידי הגדרת UseQueryCache ל-false באובייקט options. שנית, ניגשתם לנתונים הסטטיסטיים לגבי השאילתה מאובייקט המשרה.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
node queryShakespeare.js
אמורה להופיע רשימה של הודעות על ביצוע שינויים והמופעים שלהן. בנוסף, אמורים להופיע גם נתונים סטטיסטיים לגבי השאילתה:
Rows:
{ word: 'the', word_count: 614 }
{ word: 'I', word_count: 577 }
{ word: 'and', word_count: 490 }
{ word: 'to', word_count: 486 }
{ word: 'a', word_count: 407 }
{ word: 'of', word_count: 367 }
{ word: 'my', word_count: 314 }
{ word: 'is', word_count: 307 }
{ word: 'in', word_count: 291 }
{ word: 'you', word_count: 271 }
{ word: 'that', word_count: 270 }
{ word: 'me', word_count: 263 }
JOB STATISTICS:
Status: RUNNING
Creation time: 1554309220660
Start time: 1554309220793
Statement type: SELECT
10. טעינת נתונים לתוך BigQuery
אם רוצים להריץ שאילתות על נתונים משלכם, צריך קודם לטעון את הנתונים ל-BigQuery. BigQuery תומך בטעינת נתונים ממקורות רבים, כמו Google Cloud Storage, שירותים אחרים של Google או מקור מקומי שניתן לקריאה. אפשר אפילו להזרים את הנתונים. מידע נוסף זמין במאמר בנושא טעינת נתונים לתוך BigQuery.
בשלב הזה תטענו קובץ JSON שמאוחסן ב-Google Cloud Storage לטבלה ב-BigQuery. קובץ ה-JSON נמצא במיקום: gs://cloud-samples-data/bigquery/us-states/us-states.json
אם אתם רוצים לדעת מה התוכן של קובץ ה-JSON, אתם יכולים להשתמש בכלי gsutil של שורת הפקודה כדי להוריד אותו ב-Cloud Shell:
gsutil cp gs://cloud-samples-data/bigquery/us-states/us-states.json .
Copying gs://cloud-samples-data/bigquery/us-states/us-states.json...
/ [1 files][ 2.0 KiB/ 2.0 KiB]
Operation completed over 1 objects/2.0 KiB.
אפשר לראות שהוא מכיל את רשימת המדינות בארה"ב, וכל מדינה היא אובייקט JSON בשורה נפרדת:
less us-states.json
{"name": "Alabama", "post_abbr": "AL"}
{"name": "Alaska", "post_abbr": "AK"}
...
כדי לטעון את קובץ ה-JSON הזה ל-BigQuery, יוצרים קובץ createDataset.js וקובץ loadBigQueryJSON.js בתוך התיקייה BigQueryDemo:
touch createDataset.js
touch loadBigQueryJSON.js
מתקינים את ספריית הלקוח של Google Cloud Storage Node.js:
npm install --save @google-cloud/storage
עוברים לקובץ createDataset.js ומוסיפים את הקוד הבא:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
async function createDataset() {
const datasetId = "my_states_dataset3";
const bigqueryClient = new BigQuery();
// Specify the geographic location where the dataset should reside
const options = {
location: 'US',
};
// Create a new dataset
const [dataset] = await bigqueryClient.createDataset(datasetId, options);
console.log(`Dataset ${dataset.id} created.`);
}
createDataset();
}
main();
לאחר מכן, עוברים לקובץ loadBigQueryJSON.js ומזינים את הקוד הבא:
'use strict';
function main() {
// Import the Google Cloud client libraries
const {BigQuery} = require('@google-cloud/bigquery');
const {Storage} = require('@google-cloud/storage');
const datasetId = "my_states_dataset3";
const tableId = "my_states_table";
async function createTable(datasetId, tableId) {
// Creates a new table
// Create a client
const bigqueryClient = new BigQuery();
const options = {
location: 'US',
};
// Create a new table in the dataset
const [table] = await bigqueryClient
.dataset(datasetId)
.createTable(tableId, options);
console.log(`Table ${table.id} created.`);
}
async function loadJSONFromGCS(datasetId, tableId) {
// Import a GCS file into a table with manually defined schema.
// Instantiate clients
const bigqueryClient = new BigQuery();
const storageClient = new Storage();
const bucketName = 'cloud-samples-data';
const filename = 'bigquery/us-states/us-states.json';
// Configure the load job.
const metadata = {
sourceFormat: 'NEWLINE_DELIMITED_JSON',
schema: {
fields: [
{name: 'name', type: 'STRING'},
{name: 'post_abbr', type: 'STRING'},
],
},
location: 'US',
};
// Load data from a Google Cloud Storage file into the table
const [job] = await bigqueryClient
.dataset(datasetId)
.table(tableId)
.load(storageClient.bucket(bucketName).file(filename), metadata);
// load() waits for the job to finish
console.log(`Job ${job.id} completed.`);
// Check the job's status for errors
const errors = job.status.errors;
if (errors && errors.length > 0) {
throw errors;
}
}
// createDataset(datasetId);
createTable(datasetId, tableId);
loadJSONFromGCS(datasetId, tableId);
}
main();
כדאי להקדיש דקה או שתיים כדי להבין איך הקוד טוען את קובץ ה-JSON ויוצר טבלה (עם סכימה) במערך נתונים.
חוזרים ל-Cloud Shell ומריצים את האפליקציה:
node createDataset.js
node loadBigQueryJSON.js
מערך נתונים וטבלה נוצרים ב-BigQuery:
Table my_states_table created.
Job [JOB ID] completed.
כדי לוודא שמערך הנתונים נוצר, אפשר לעבור לממשק המשתמש האינטרנטי של BigQuery. יוצגו לכם מערך נתונים חדש וטבלה. אם עוברים לכרטיסייה Preview של הטבלה, אפשר לראות את הנתונים בפועל:

11. מעולה!
למדתם איך להשתמש ב-BigQuery באמצעות Node.js.
הסרת המשאבים
כדי להימנע מחיובים בחשבון Google Cloud Platform על המשאבים שבהם השתמשתם במדריך למתחילים הזה:
- עוברים אל Cloud Platform Console.
- בוחרים את הפרויקט שרוצים לסגור ולוחצים על 'מחיקה' בחלק העליון. הפעולה הזו מתזמנת את הפרויקט למחיקה.
מידע נוסף
- Google BigQuery: https://cloud.google.com/bigquery/docs/
- Node.js ב-Google Cloud Platform: https://cloud.google.com/nodejs/
- ספריית הלקוח של Google BigQuery Node.js: https://github.com/googleapis/nodejs-bigquery
רישיון
עבודה זו מורשית תחת רישיון Creative Commons שמותנה בייחוס 2.0 כללי.